
How to Scrape the Data from Quora?
If you have clicked on to read this blog then it is quite obvious that you have some learning interests regarding web scraping techniques to scrape data from millennium websites available over the Internet. Data is what drives the buying behavior of a customer, and your duty as an analyst or a marketer is to understand the pattern which the target customer makes which of course is determined through relevant data. The bottom line is that the core function of the research market is data which enables it to expand each year.
When we talk about questions, we need answers to address them. Well, an online search for answers mostly leads us to Quora, a website where people address a common causal question regarding almost anything which hits your mind. The website is a hub of all intellectuals and experts sharing their wise words and opinions on a certain topic. Hence, you can find tons of different perspectives and ideas regarding your business data project or data on any personal research task.
You can easily scrape all answers in the form of data from Quora by simply creating a web scraper using Python. Web Scraper can scrape all data by entering questions. This is what this blog is essentially all about!
Where Is The Code to Scrape Quora?
Web Scraping is the best-suited option to scrape any popular or target website data without any hassle. However, there are certain dos and don’ts affiliated with web scraping which is going to be discussed in the latter section of the blog. Let us begin with defining our web scraping tools to scrape Quora Website data efficiently.
When scraping a lot of articles by DIY web-scarping tools the best option is to use Beautiful Soup Library and Python 3.7. To scrape data from Quora Website, we are going to follow the same thing. And store the data within JSON file format. By using code we can scrape and extract all questions and answers from Quora Website very easily. Another thing is that you can use a text editor. PyCharm (a full-blown IDE) is utilized for the purpose however you can also use Atom in its place. As it comes with multiple plugins option and it is lighter in terms of mass.
To begin with, writing the code we must import both internal and external libraries. Once you are done with setting the SSL certificate to ‘CERT_NONE’. Then just check the hostname to False such that we can avoid all errors arising during data scraping action. After completing the action, to complete the entire setup we need to accept questions from the user. To do this, check out the demo given below, for your reference.

We create the URL using the above question. With string manipulation, we convert the question to the URL. This step is important as Quora Website formats all URLs into questions. Once we have the URL created, we can easily inbuilt requests from urllib to hit on the webpage. This step will help us to track the piece of code that we need to track. Do remember to add Firefox in the header. This part is significant in your data scraping project as most websites have built-in systems for blocking scrapers if you don’t use the header. In the alternative case, your IP will get blocked eventually and further strict actions will be initiated against you in the worst possible case.
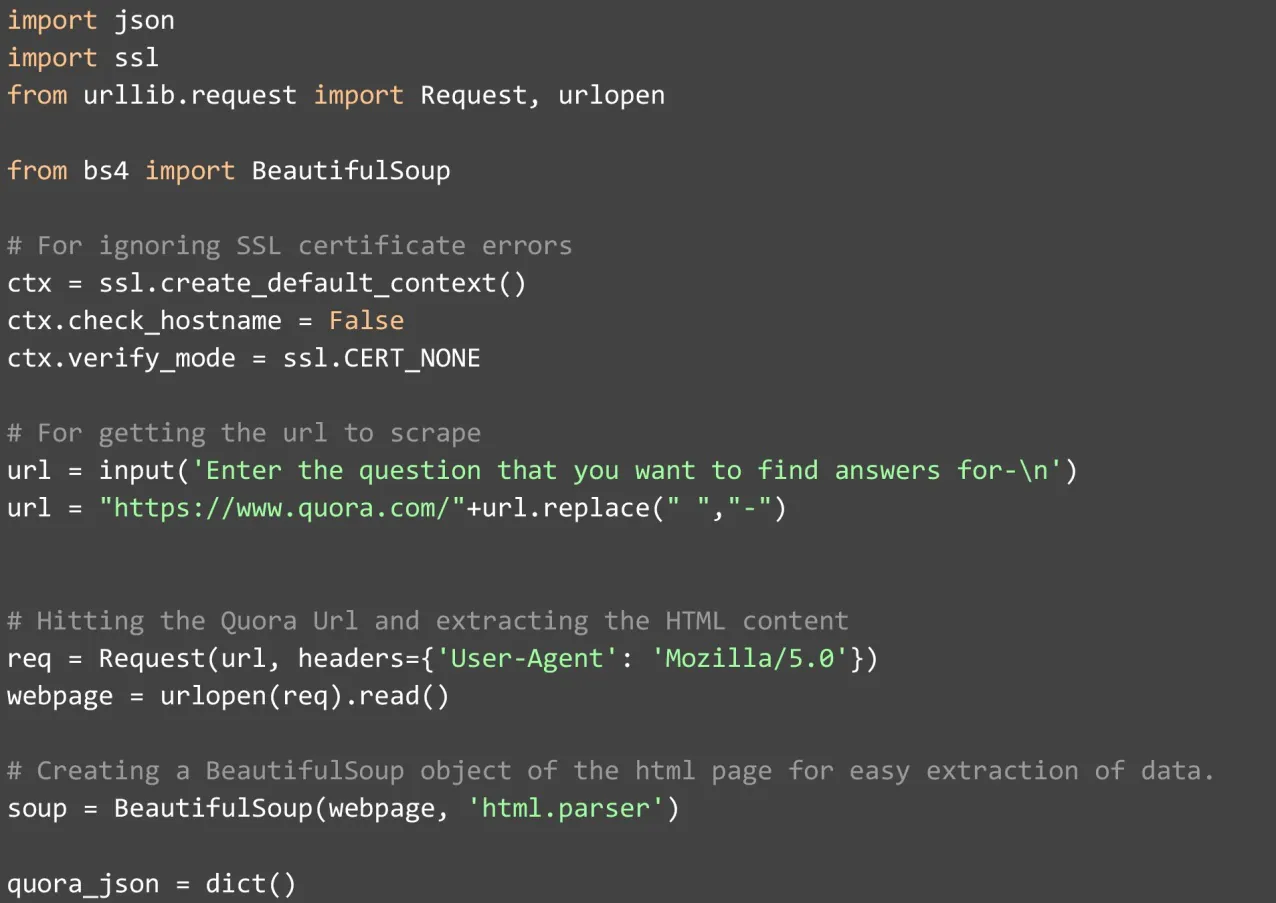
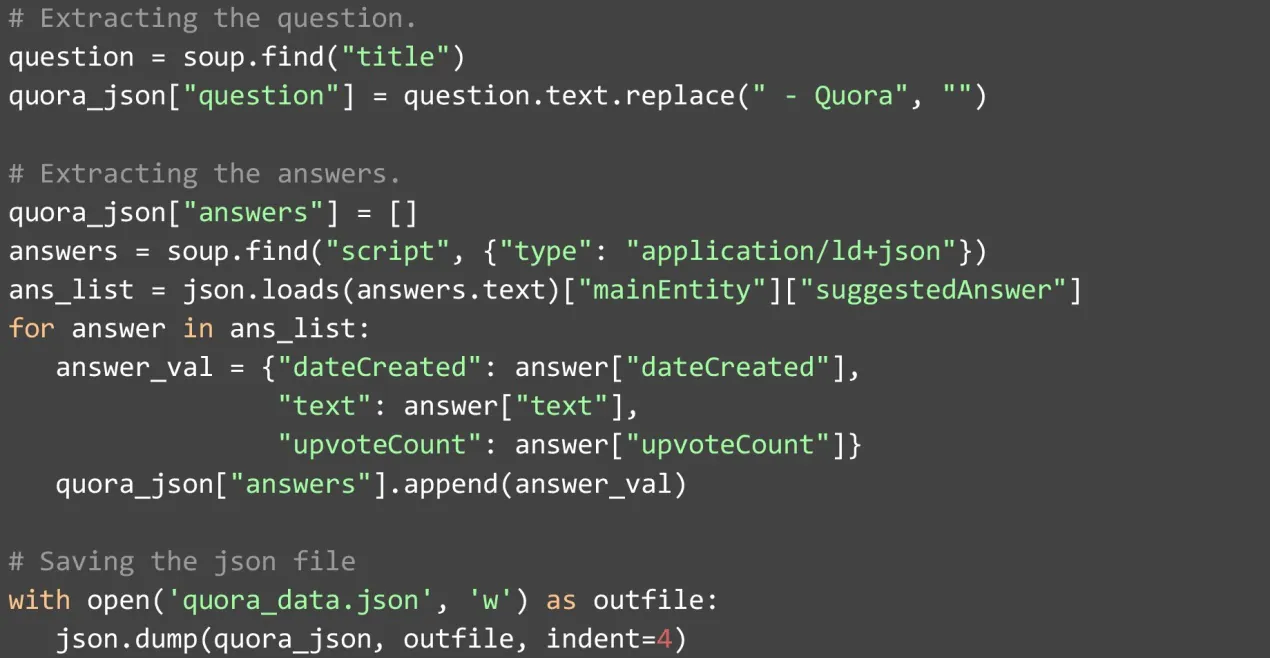
After the webpage is obtained in the given HTML format, it should be stored in a variable format. As we need to convert the HTML format into the Beautiful Soup Object such that it becomes simple to parse and extraction of data becomes easier. We can extract the question directly from the ‘title tag’ which is present on the web page. We just need to remove ‘– Quora’ as all titles come with this string.
Scraping the right answer to your specific question is a little complex. You will need to extract the JSON stored data in the element type ‘script’ consisting of a higher value for the ‘application/Id+json’ as type. After doing this, you will come across a list of answers with various fields.
From the various fields we have placed certain answers below for your better understanding:
The exact date on which answer is written.
The answer to the question itself.
The number of up-votes the answer has received.
Once you extract data you can append it as a list of answers and save the final output file in JSON format. We use this format simply because it proves very accessible while transferring heavy data files and sharing them to different technology versions like Windows, macOS, etc.
Understanding The Output
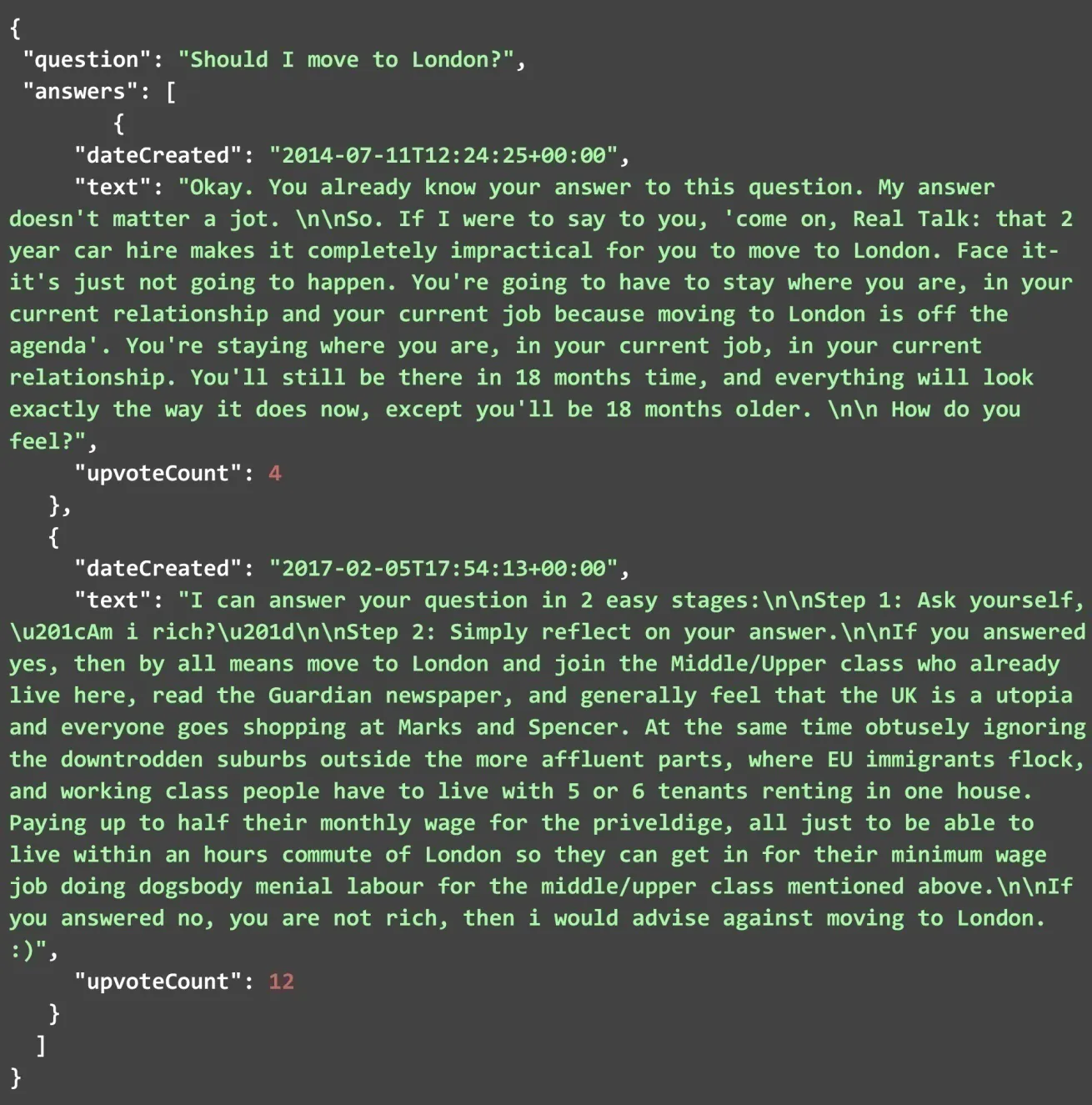
You can find the JSON file as given below. It contains all answers that are scraped from the HTML webpage when we run the code with questions as mentioned in the last part. As you can see that JSON format consists of two fields. For both the answer and the question, every answer must include all three parameters as mentioned earlier. Whereas, to scrape the answers we need to have a particular question lined up. A few of them are mentioned below, you can check these out for clearing the blur picture in your mind.
The Limitations of Scraping Content From Quora
Web Scraping might as well look like a perfect solution to you for getting all answers from Quora. But like any other DIY code there are certain limitations to the code. Your code will break every time you enter a question that does not exist. Hence, precautionary measures are necessary. At the same instance, you have to type a question multiple times to see which version of it exists within the website.
It is better to do some homework on the given website to avoid any failed attempts over questions. The closest question is to be entered to get desired results. Another aspect is how you choose to relate the qualms of data scraping of the Quora website. You will need to take care that you pass the robot.txt.file to scrape the target data more precisely. Afterward, the storing of data is another important condition to benefit from. It is to be noted that any sort of commercial usage of the data can result in some major legal issues and the data collection for inappropriate reasons can be dangerous.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
