
How to Scrape a Real-Estate Website?
Various cities continue to develop communities and build homes which demand real-estate magic! In this way, the real estate sector is growing in demand with each passing day. There are various real-estate websites available over the Internet sharing their expertise in the respective domain. These websites prove beneficial for buyers and sellers as well as real estate agents. In this blog, we are essentially focusing on acquiring real-estate data such as images, price listings, areas, rooms, and bathrooms for better package comparisons. Such websites can also be utilized to buy commercial properties as well. The best thing about such readily available website data is their MLS listings. In this way, you can have access to all multiple real-estate businesses out there in the world.
Today, we are neglecting and abandoning all traditional modes of manual data extraction and collection and relying on web scraping for achieving our target data within the blog. In this blog, we will be extracting valuable data such as:
Price comparisons
Creation of a list of properties (clients satisfaction)
Industrial insights
Web Scraping A Real Estate Website’s Data
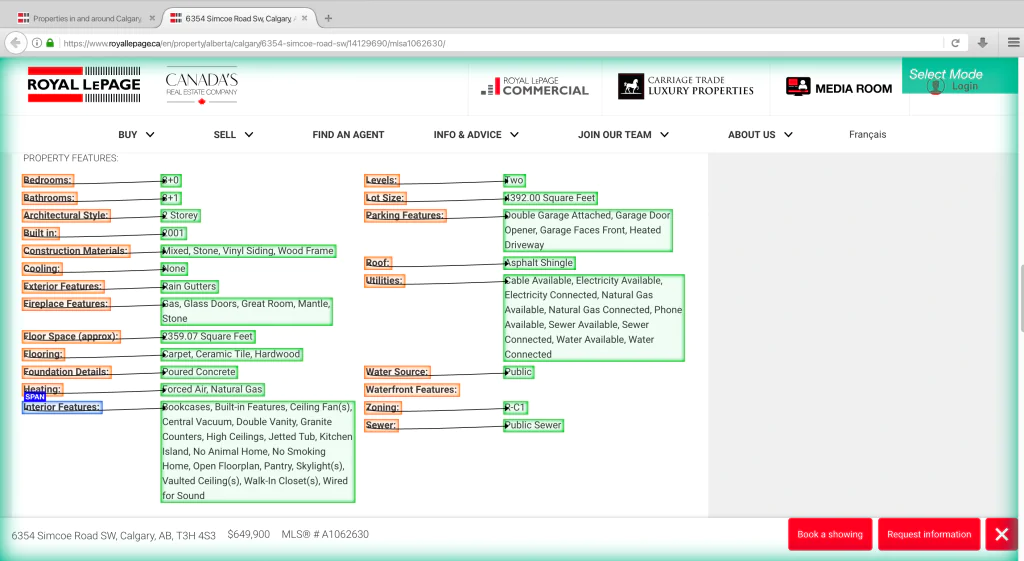
We are scraping the website, Royal LePage. All residential property data is going to be selected which fulfill the following requirements:
A price range starting from $400,000 and ending on $700,000
For sale is Calgary only
Location within the SW quadrant
Once you download ParseHub, you need to open the installed app and readily click on the ‘New Project’ option. Use the given URL from the target website i.e. Royal LePage for the result page. The page will be quickly rendered inside the app.
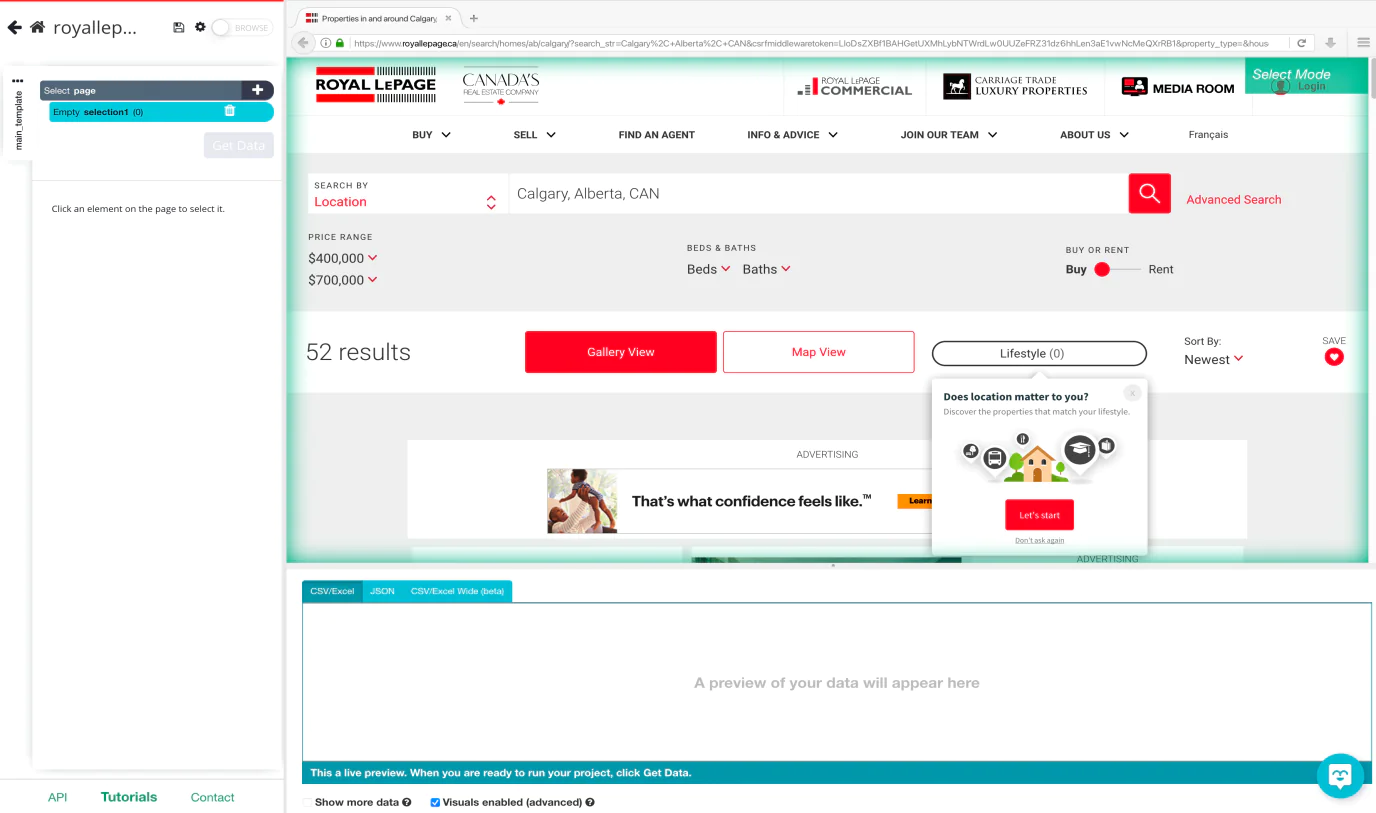
As soon as the website is rendered you can select a function that will be automatically created as a response.
Now select and click on the first address listing from the page. The address on which you have clicked will now be highlighted to green to show that it has been selected as an option.
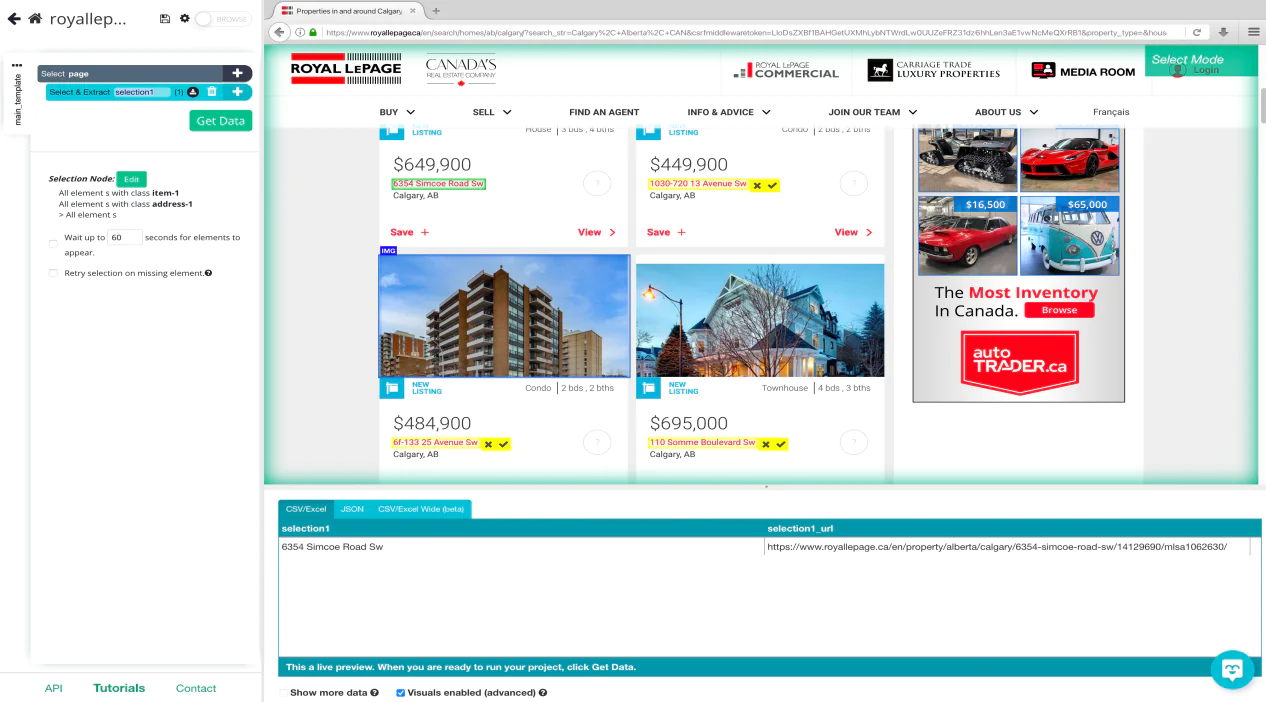
ParseHub will suggest other unique elements which you would also like to extract. All the remaining addresses on the page can be highlighted in yellow. Just click on the second address in the given list and you will see that all yellowish items are now green. This is because all these items are now selected.
To the very left sidebar, you can rename selected items to ‘Address’. You will notice that the web scraping tool is efficiently extracting the address and URL for every listing.
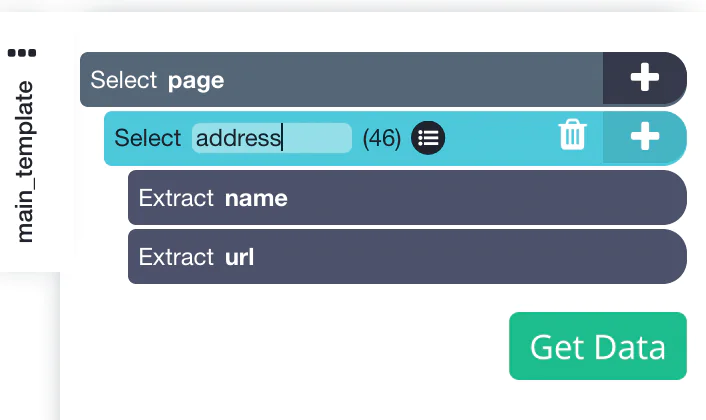
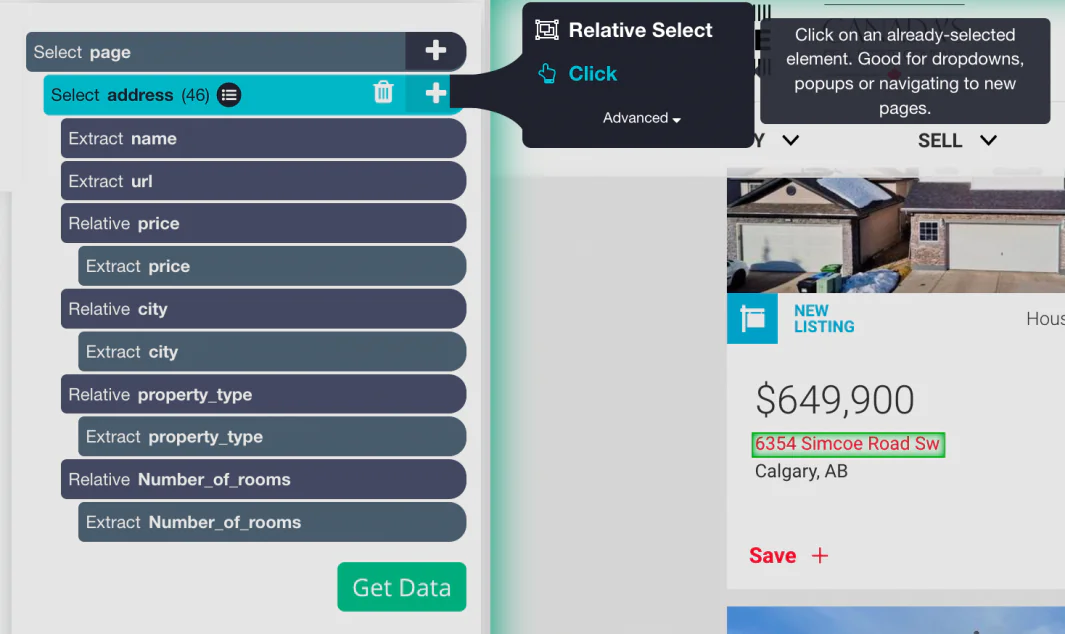
Now click the (+) PLUS icon on the left sidebar to address the selection of the relative command action.
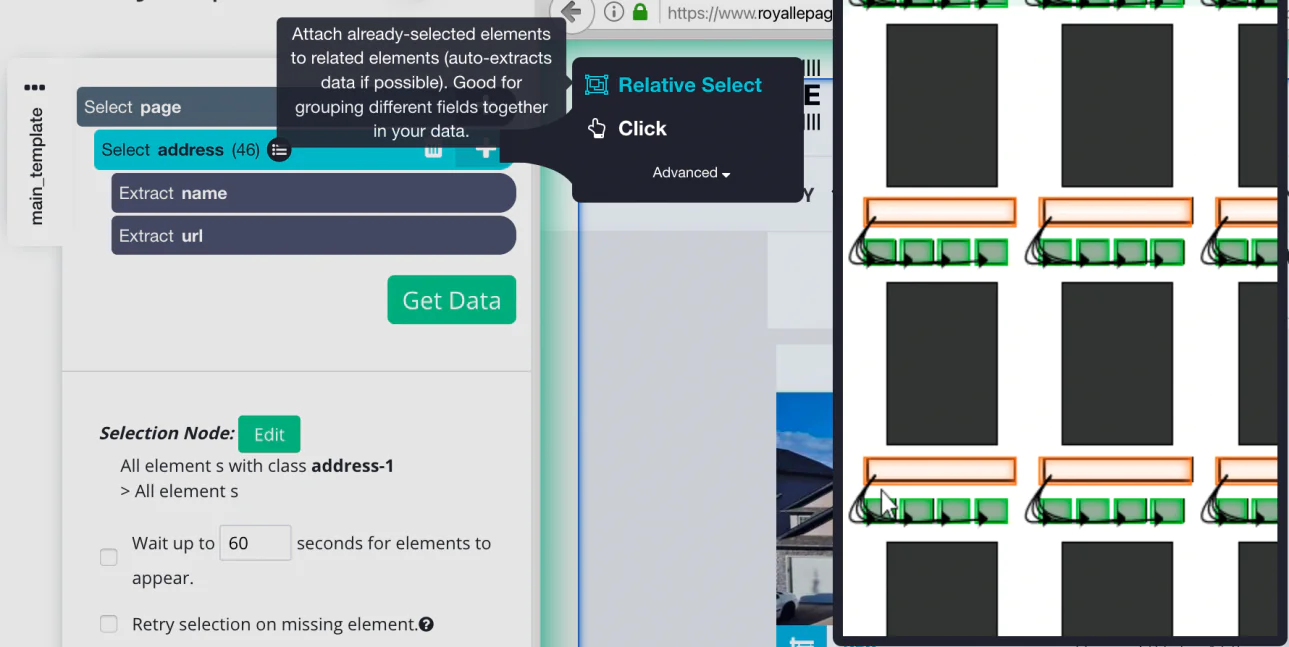
With ‘Relative select Command’ you need to click on the very first address of listing on the page and later on the price. Then you will encounter an arrow connecting the two selections.
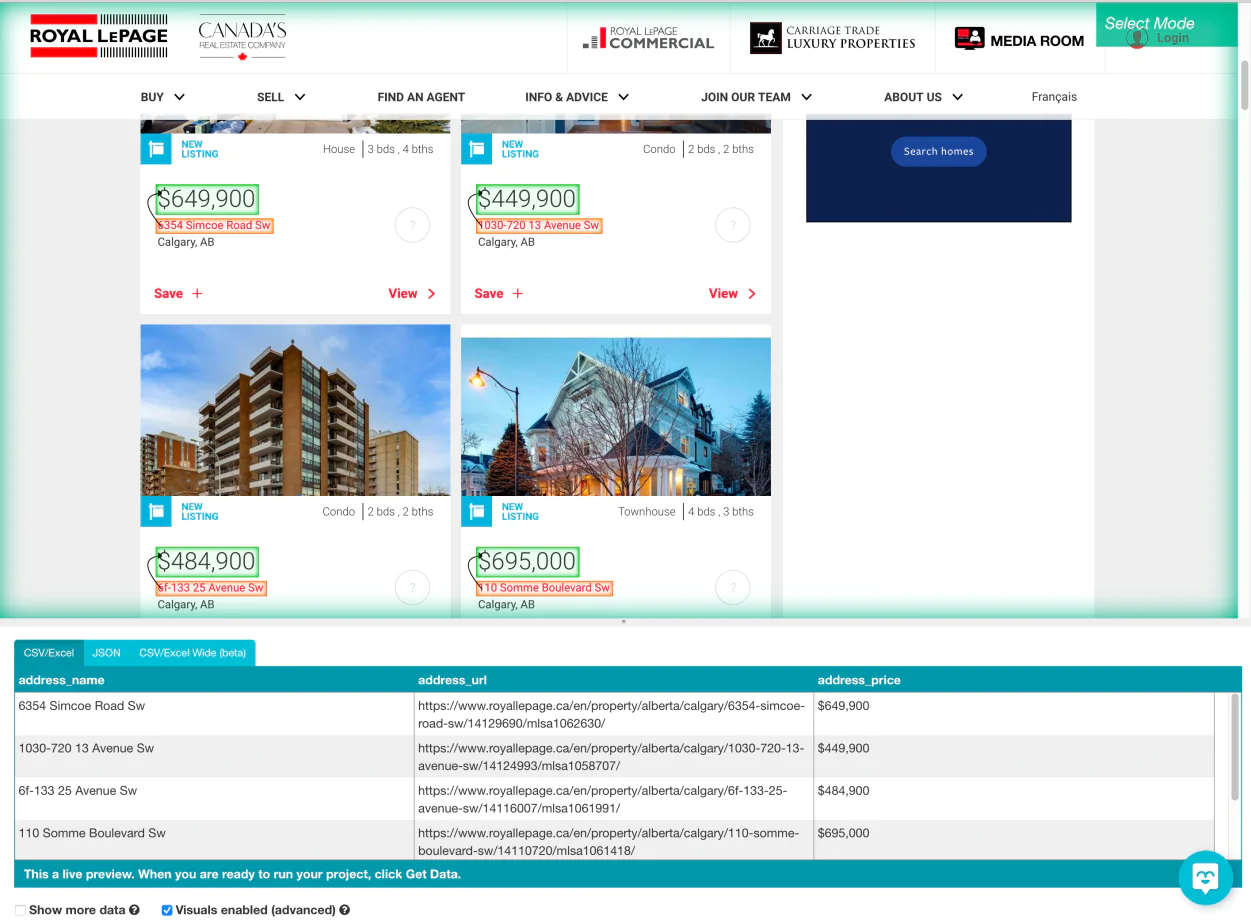
You need to further expand the new command which you have already created and then again delete the URL which is being extracted by default.
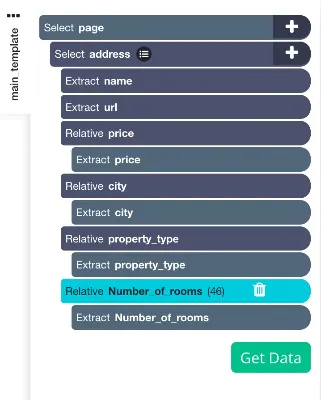
9. Repeat step 7 until property types, the number of rooms, and the located city is extracted. Remember to make sure that the new selections are renamed accordingly.
Here we have selected the target data which is needed to be scraped very successfully from the results page. It should look something as given in the image below:
Scraping more data from each real estate listing
Now let us get scraping the selected data. In this case, we tell ParseHub to click on every listing and extract data separately from each page. Such as:
Images
Property description
Property information
At first, we should click on the sidebar on the 3 visible dots which lie next to main_template text.
Rename the template to ‘Listing_results_page’. These templates assist ParseHub to keep separate the different page layouts. This keeps them organized systematically.
It is time to use the (+) PLUS button which lies next to the ‘address’ selection option. Choose the command and a pop-up will show up asking if the link is on the next page. Select ‘No’ and create a new input template in which we will utilize the Listing_page.
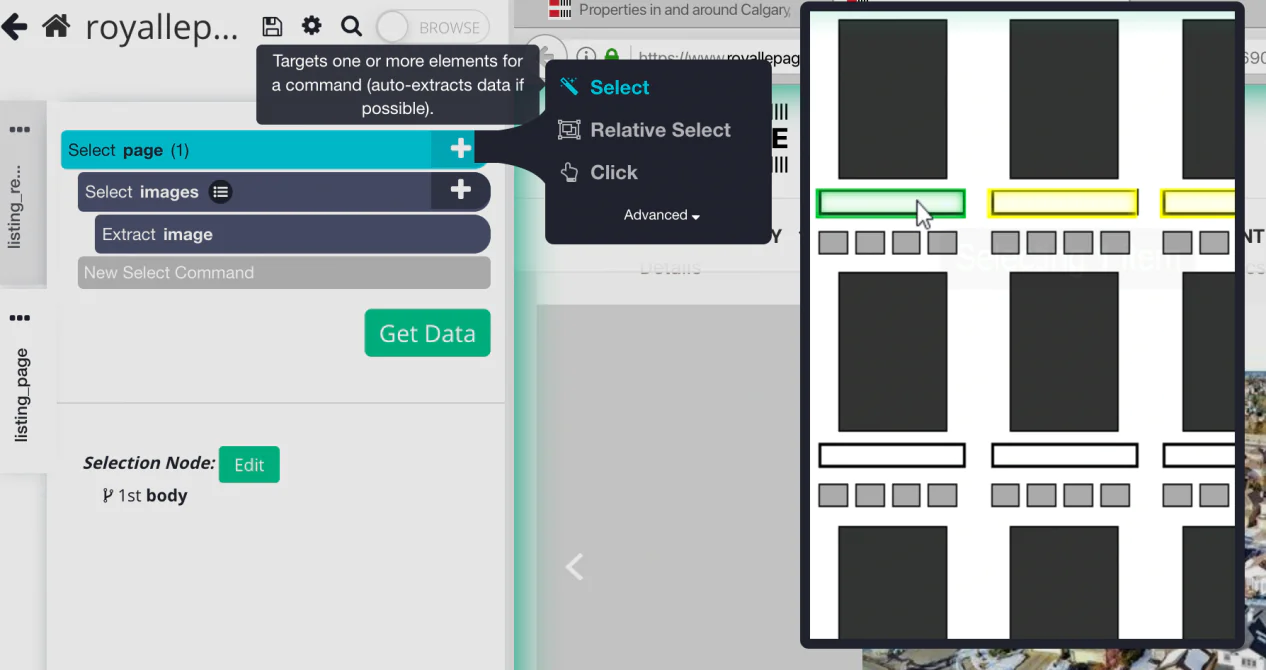
ParseHub will automatically render a new template on the result page.
Click on property images. These will be highlighted (yellow) and simply click on the yellow image to extract the image successfully.

Continue to click the (+) PLUS button to sign in to the next page via ‘SELECT Option’.
By choosing the command you can click on the property content very easily. All descriptions involve keywords when buyers search for open concepts.
Just rename the selection ‘Property_information’ or anything which suits your taste.
Let us extract all property features by clicking the (+) PLUS button. Afterward, click on the yellow highlighted content and extract the description.
Then all you need to do is to rename the selected features as ‘Building_features’.
Now select the relative command select.
Click the label (first) and then select feature. It can be continued a couple of times to make the app familiar with the action you want to conduct.
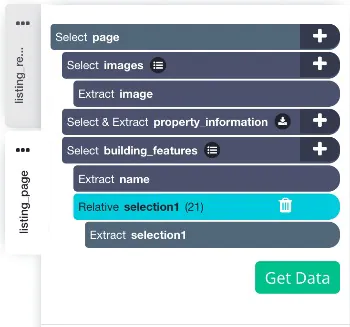
The listing_page template must look something as shown in the image below:
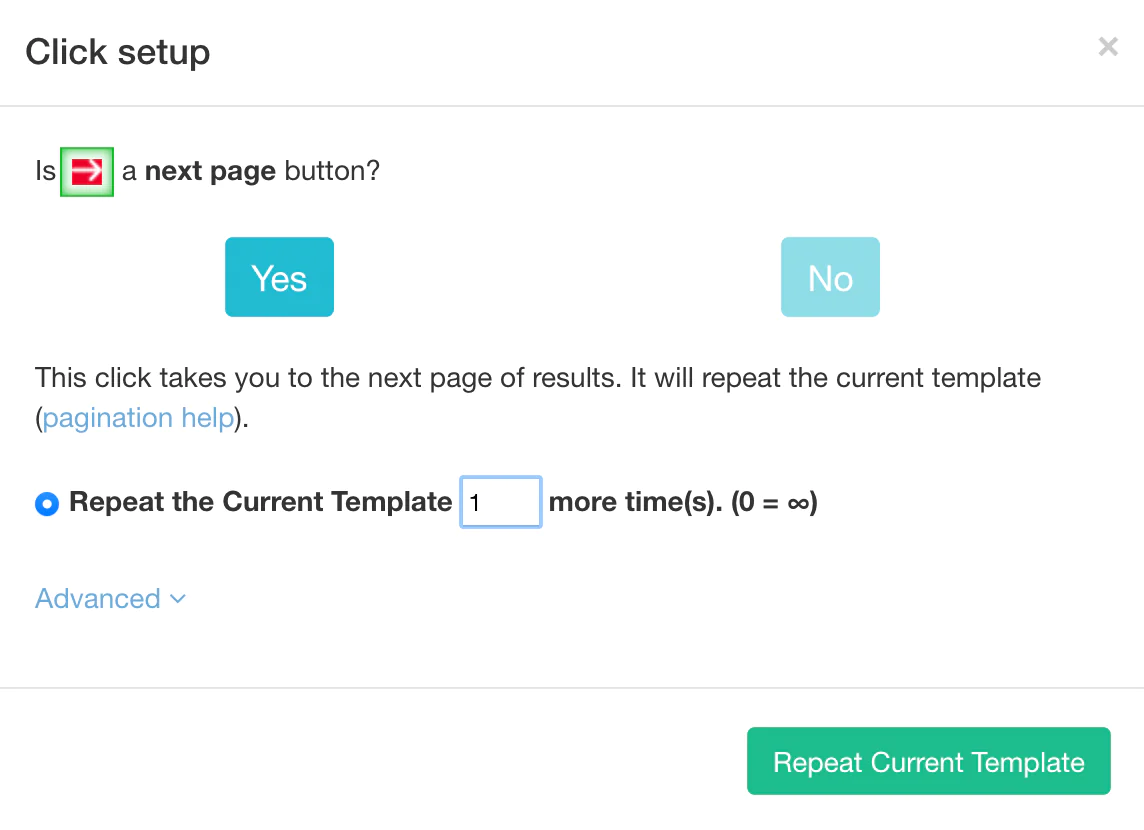
Adding Pagination (optional)
‘Pagination’ can also be added to the project depending upon the number of listings you need to scrape. Since we are working on two result pages, let us deal with pagination for your convenience and reference.
Begin with starting ParseHub to navigate the further page results.
Return to template ‘Listng_results_page’. You might as well have to change the browser tab to search for the result page.
Again make use of the (+) PLUS button to select and choose the command selected.
Now move towards the ‘Next Page Link’ which can be found at the bottom line of the website Royal LePage. Rename to ‘Next_button’.
The web scraping tool will by default extract all text and URLs for the given link. Remove the 2 ongoing commands by expanding the ‘Next_button’ selection.
A pop-up will show up for the ‘Next’ link.
Click ‘YES’
Enter the page numbers you would like to navigate.
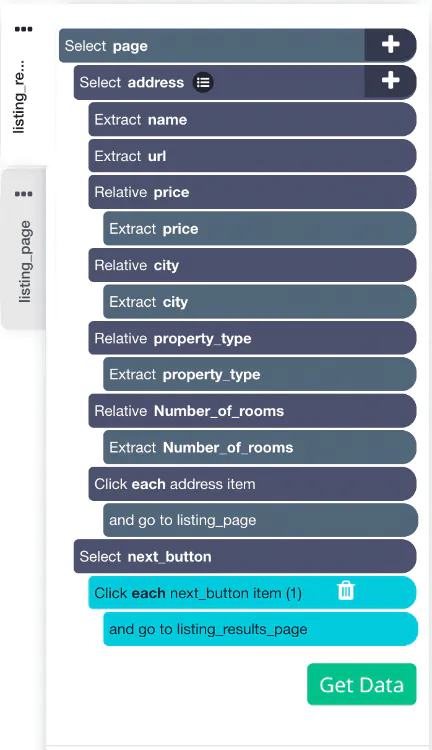
The final project is ready which must look something identical to this:
Running and Exporting your Project
With all the work we have done so far our project is final to scrape ‘Royal LePage’. To complete the action just click on the green button ‘Get Data’. You will come across the following page:
Once the data from the website is entirely scraped, you will be notified via email. The downloaded data can be stored in any format like Excel, CSV, or JSON file format of your choice.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
