
What is Optical Character Recognition (OCR)?
Optical Character Recognition or OCR has become a much-celebrated technology to distinguish handwritten or printed characters from documents in both scanned or hardcopy form. The Optical Character Recognition process involves a thorough examination and translation of a document every character into code. The code can be used for better and efficient data processing. Commonly, OCR is referred to as a Text Recognition Tool. OCR systems are composed of both software and hardware elements that are used to readily convert scanned documents into machine-readable text. The hardware part includes an optical scanner that copies or reads text from the document while the software part typically contributes to advanced document data processing. Artificial Intelligence (AI) is used within technologically advanced software to implement ICR i.e. Intelligent Character Recognition. ICR is a more advanced option to identify different linguistic styles and features of handwriting.
Optical Character Recognition (OCR) is most commonly used to convert hard copy documents like historic files into PDFs. Users can efficiently edit the soft copy format and search for any specific content section within the document as if it is created within a word processor. The darker areas of the document are processed further to locate numeric digits or alphabetic letters. OCR programs vary in technique and typically target one character, one word, or one block at a time from the text.
Evolution of Optical Character Recognition (OCR)
Optical Character Recognition (OCR) technology was invented by Dr. Edmund Fournier d’Albe as a reading device that translated letters into sounds for the visually impaired population. During WW1, Popular physicist Emanuel Goldberg is the next in line to invent a character the reading machine that could easily convert textual characters into telegraph code. With passing time, Goldberg repurposed existing technologies to develop a first-ever record-keeping system that IBM later on acquired under its name. Optical Character Recognition (OCR) gained immense popularity with the digitization of newspapers. In the 2000s, OCR technology has evolved into a largely cloud-based service. Nowadays anyone can access OCR services on mobile phones with a professional level accuracy rate.
How Does OCR Work?
The entire OCR process is straightforward. In professional practice, the technology can be a bit complex to implement due to various other factors. Like as, when dealing with different fonts and methods of letter formation at a larger scale. These factors contribute to making the job a bit tough in the identification of characters within the selected document text.
Optical Character Recognition involves a cycle of streamlined steps that is divided into image pre-processing, text character recognition, and then post-processing stage. Let us discuss every step of OCR for a clear cut understanding of how OCR technology works –
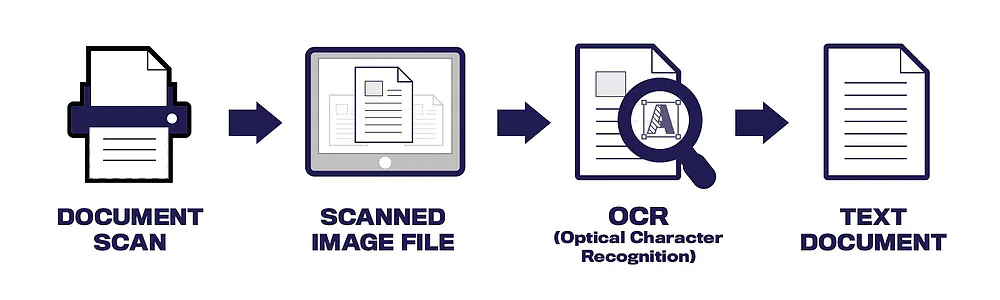
Step 1: The Document is Scanned
The very initial step is to make sure that the target document is correctly aligned in the scanner. After scanning it the horizontal and vertical alignment of document text lines will greatly impact the overall process efficiency. Of course, if you are dealing with any digital image like a PNG, JPEG, or PDF, the step is not mandatory as the image is pre-scanned.
Step 2: Software Refines the Image
The next step includes the improvement of elements within the document that need to be captured with the help of software sets. Any artifacts, obstructions, imperfections, dust particles are removed and edges of letters are smoothened out. Afterward, the text is closely and carefully removed from the document/image in a manner that plain text remains.
Step 3: Binarization
Now is the time to align the text lines and convert any other shade of grey or colors into black and white background. This step is very essential in the whole OCR process it not only makes recognition of fonts easier but also helps to differentiate text with perfect accuracy.
Step 4: Identify the Characters
This step is all about figuring out which characters are on a page of a document. The basic forms of OCR compare pixels of every scanned letter to an existent font database. This proves to be a reference point for matching character lists. The more advanced form of OCR technology breaks down every character into constituent elements of a whole like curves and corners to match actual letters features.
Step 5: Ensure Accuracy
OCR software further reduces the error ratio by making good use of internal dictionaries for cross-referencing. This enables higher data quality at all levels of the OCR process.
Step 6: Produce an Editable Digital Text File
The final output includes a fully researched, processed, and searchable digital text file that can be easily manipulated when required.
Common Uses of OCR
Optical Character Recognition (OCR) applies to a range of business types. There are many commercial and practical uses of OCR technology ranging from data entry to automatic data recognition. Here are a few examples –
Banking

One of the major applications of OCR is related to the banking sector. OCR helps improve financial transactions and manage security risks effectively. Banks can accurately extract data from:
- Checks—capturing the account information and the handwritten amount and signature
- Mortgage applications, loan documents, and pay-slips
- ATMs, to improve security and accuracy in self-service processes.
Insurance
OCR also finds its uses in insurance companies by delivering good customer service and company performance. Documents can be digitized and automated via OCR and other latest technologies like AI and ML.
Healthcare
With OCR, it is possible to scan, search and store patient medical histories containing reports like X-rays, treatments, insurance payments, and tests. Any hospital record can be directly accessed via OCR. This significantly reduces the need for manual admin.
Legal
The legal industry deals with a lot of paperwork. OCR technology provides immense benefits to digitize a wide range of documentation including affidavits, handwritten notes, judgments, statements, filings, and wills.
Tourism and Hospitality
In the tourism and hospitality sector, OCR can enable guests to self-check-in by scanning their passports on a hotel website or app.
Retail
OCR technology proves authentic and useful in the retail industry as well. It offers data capture services from invoices, packing lists, purchase orders, and much more. It works to improve customer experience as a noteworthy byproduct. All thanks to mobile OCR technology customers don’t need to stress about losing vouchers any longer. They can simply scan serial codes via phones to redeem the lost vouchers.
How ITS Can Help You With OCR Services?
Information Transformation Service (ITS) has a lot to offer in a little. ITS OCR Professionals are trained in attaining multi-lingual objectives. Our executives will manage your data center in the most effective way. ITS Team holds a comprehensive understanding of ICR and OCR Service providing processes, Functioning, and solutions, making it a beneficial association for your business. We are exceptional at putting up with international standards and providing you with 100% error-free results within the shortest interval of time. ITS can benefit you with OCR Services in the long run. ITS works 24/7 round-the-clock services for quick turnout time that helps the client benefit from the time zone advantage. If you are interested in ITS OCR Services, you can ask for a free quote!
