
How to use Selenium to scrape data?
To address issues in business and research, data is a universal requirement. Forms, questionnaires, surveys, and interviews are all ways to get data, but they don’t nearly reach the largest data source out there. The Internet is a vast source of information on every conceivable topic. Unfortunately, the majority of websites do not give users the ability to save and keep the information that is visible on their web pages. This issue is resolved and users are now able to scrape huge amounts of the data they require from the web, thanks to web scraping.
There are numerous tools to scrape data, however, in this post, we will tell you about to scrape data with Selenium.
What is web scraping?
Web scraping is the automated collection of information and data from a website or any other online resource. Web scraping, as opposed to screen scraping, collects the HTML code from within the webpage. Users can then extract data and perform data cleansing, manipulation, and analysis by processing the HTML code of the webpage. For extensive data analysis initiatives, exhaustive volumes of this data can even be saved in a database. The popularity and need for data analysis, as well as the volume of raw data that can be gathered using online scrapers, have sparked the creation of specialized python packages that make web scraping simple as cake.
Why is web scraping important?
Two major advantages of web scraping are:
Competitive analysis
Compared to the human population, there are perhaps 100 times more things sold through e-commerce networks. Imagine having real-time access to all of these data in a database or spreadsheet. Data scraping can help you with that! Utilize a data-driven pricing strategy to sway consumer purchasing decisions, entice customers who are price conscious by lowering the costs of the products they browse through to below the market base price, and maximize profits in the process. Get to track products using data scraping for changes in availability and stock count so you can take advantage of that.
Financial Decisions to make
The concept of web scraping is not new to the investment community. To reduce the chance of failure, hedge funds occasionally use the web scraping technique to gather alternative data. It aids in the identification of prospective investment possibilities and unforeseen risks.
Investment decisions are difficult because they frequently need some steps, such as developing a fictitious thesis, conducting experiments, and conducting research, before a wise choice can be reached. An investment theory can be tested most successfully by examining historical facts. It enables you to learn the true reasons behind prior failures or achievements, avoid traps in the future, and potentially increase investment returns.
Web scraping is a method for more efficiently extracting historical data, which may then be fed into a machine-learning database for model training. To improve decision-making, investment businesses use big data to increase the accuracy of analytical results.
What is Selenium?
Initially designed as a tool to evaluate a website’s functionality, Selenium swiftly evolved into a general web browser automation tool used for web scraping and other automation tasks. Through middleware managed by Selenium webdriver, this widely used tool can automate various browsers like Chrome, Firefox, Opera, and even Internet Explorer.
The W3C organization’s first browser automation protocol, Webdriver, is basically a middleware protocol service that stands between the browser and the client and translates user input into actions the browser can.
Role of Selenium and Python in web scraping
Python includes libraries for nearly any operation a user may imagine, including modules for activities like web scraping. Selenium is a collection of numerous open-source browser automation applications. It includes bindings for a number of well-known programming languages, including Python, which we’ll be utilizing in this tutorial.
Selenium with Python was initially created and used largely for cross-browser testing, but as time went on, new inventive use cases, including web scraping, were discovered.
Selenium automates operations on numerous well-liked browsers, including Firefox, Chrome, and Safari, using the Webdriver protocol. This automation can be done remotely or locally, for example, to test a website (for purposes such as web scraping).
How to use Selenium for Web Scraping?
Set up and tools
1 Installation
- Install Selenium using pip
pip install selenium
- Install Selenium using Conda
conda install -c conda-forge selenium
2 Download the chrome driver
Any of the methods listed below can be used to download web drivers.
- You can either directly download the chrome driver from the below link-
https://chromedriver.chromium.org/downloads
- Or, you can download it directly using the below line of code-driver = webdriver.Chrome(ChromeDriverManager().install())
The methods listed below will assist us in finding components on a web page and will return a list:
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
Let’s now create a Python script to scrape photos from the internet.
Image web scraping using Selenium Python
Step 1: Importing libraries
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import ElementClickInterceptedException
Step 2: Installing the driver
#Install Driver
driver = webdriver.Chrome(ChromeDriverManager().install())
Step 3: Specifying search URL
#Specify Search URL
driver.get(search_url.format(q=’Car’))
In order to prevent you from facing legal consequences for using licensed or copyrighted images, we have utilized this unique URL. Alternative search URLs include https://google.com.
Then, using our Search URL, we look for Car. Paste the link into to driver. get(“ Your Link Here ”) function and run the cell. By doing this, a new browser tab will be opened for that link.
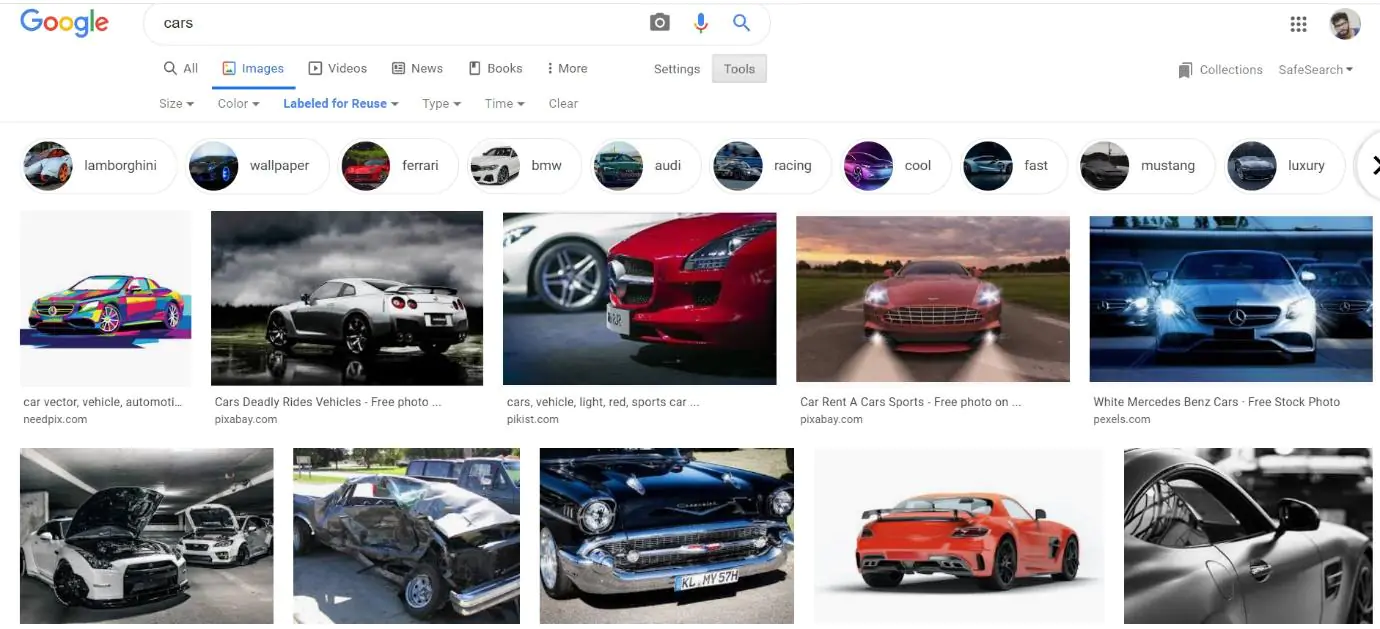
Step 4: Scrolling to the end of the page
#Scroll to the end of the page
driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”)
time.sleep(5)#sleep_between_interactions
We could use this line of code to go to the page’s conclusion. After that, we give a 5-second sleep period to ensure that we don’t encounter an issue where we try to read content from a page that hasn’t yet loaded.
Step 5: Locating the images to be scraped from the page
#Locate the images to be scraped from the current page
imgResults = driver.find_elements_by_xpath(“//img[contains(@class,’Q4LuWd’)]”)
totalResults=len(imgResults)
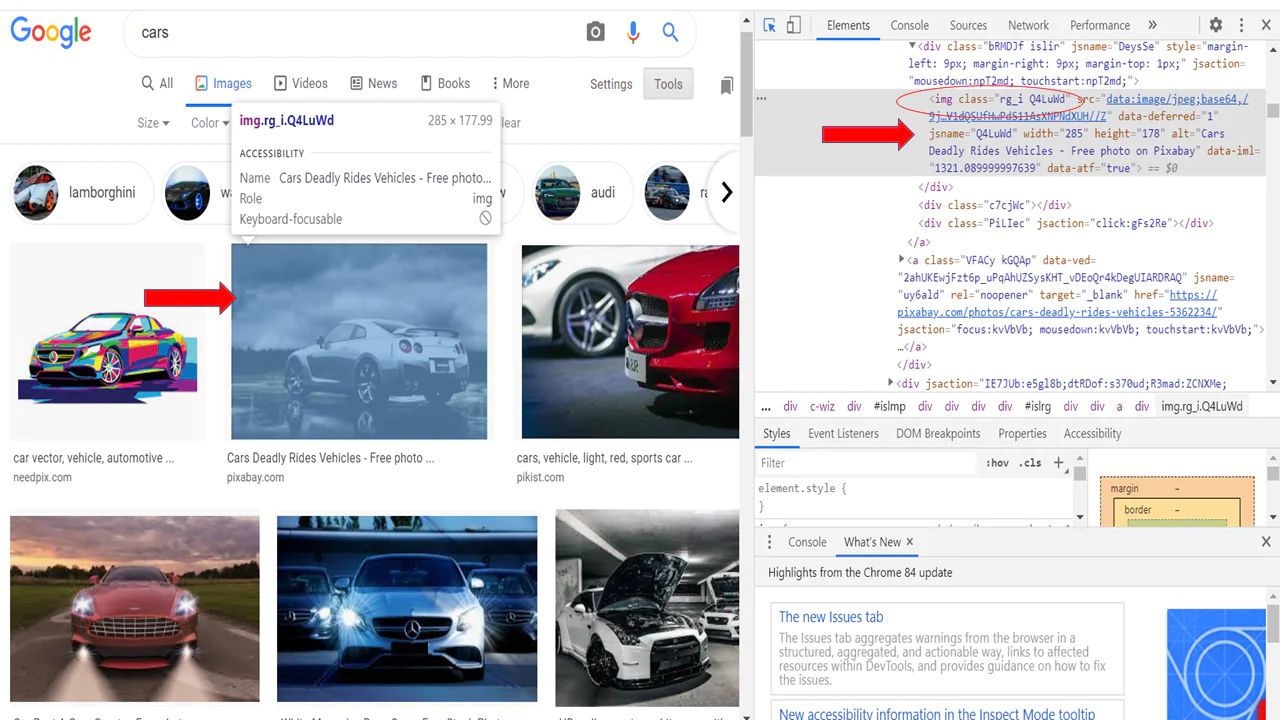
We’ll now fetch every picture link on that specific page. To save such links, we shall make a “list.” So, to achieve that, open the browser window, right-click anywhere on the page, and choose “inspect element,” or use Ctrl+Shift+I to activate the developer tools.
Determine any properties now, including class, id, etc. It appears in each of these pictures. In our example, all of these photos share the class=”‘Q4LuWd” attribute.
Step 6: Extracting the corresponding link of each image
As is clear, the images displayed on the page are still thumbnails and not actual images. Therefore, in order to download each image, we must click on each thumbnail and gather relevant details about that particular image.
#Click on each Image to extract its corresponding link to download
img_urls = set()
for i in range(0,len(imgResults)):
img=imgResults[i]
try:
img.click()
time.sleep(2)
actual_images = driver.find_elements_by_css_selector(‘img.n3VNCb’)
for actual_image in actual_images:
if actual_image.get_attribute(‘src’) and ‘https’ in actual_image.get_attribute(‘src’):
img_urls.add(actual_image.get_attribute(‘src’))
except ElementClickInterceptedException or ElementNotInteractableException as err:
print(err)
Therefore, the snippet of code above executes the following operations:
- Go through each thumbnail one at a time, then click it.
- Give our browser a 2-second nap (:P).
- To find that image on the page, discover the specific HTML element that goes with it.
- Still, we receive many results for a given image. But the download URL for that photograph is all that matters to us.
- So, after extracting the’src’ attribute from each result for that image, we check to see if “https” is included in the’src’ or not, since an online link normally begins with “https.”
Step 7: Downloading and save each image in the destination directory
os.chdir(‘C:/Qurantine/Blog/WebScrapping/Dataset1’)
baseDir=os.getcwd()
for i, url in enumerate(img_urls):
file_name = f”{i:150}.jpg”
try:
image_content = requests.get(url).content
except Exception as e:
print(f”ERROR – COULD NOT DOWNLOAD {url} – {e}“)
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert(‘RGB’)
file_path = os.path.join(baseDir, file_name)
with open(file_path, ‘wb’) as f:
image.save(f, “JPEG”, quality=85)
print(f”SAVED – {url} – AT: {file_path}“)
except Exception as e:
print(f”ERROR – COULD NOT SAVE {url} – {e}“)
So here you are! You’ve now successfully extracted the image for your project.
Conclusion
Web scraping has existed since the early days of the World Wide Web, however, it is quite difficult to scrape modern websites that largely rely on new technology. However, with the help of web scrappers, this task has become easier.
In this article, we learned how to use Selenium to scrape data. Selenium is generally recognized as a popular open-source testing framework for online applications that enables QA professionals to run automated tests, carry out playbacks, and add remote control capability (allowing many browser instances for load testing and multiple browser types).
Regardless matter how a browser is designed, Selenium can easily communicate common Python commands to many browsers. Python is a scripted language; therefore running a compiler to translate lines of code into something that can be implemented and used is not a concern.
