
How To Scrape Data From Password-Protected Websites
Many websites use password security to restrict access to a particular page. When a visitor reaches a protected page, they are required to enter the password. It enables a website to distribute its own exclusive content according to its own terms. Even if this strategy is significant and helpful for a site’s security, individuals pose particular difficulties when it comes to web scraping password-protected websites since these sites need authentication in order to access the necessary data. When information is not easily accessible through open APIs or other channels, it becomes necessary to extract it from websites. In addition, although there are manual approaches, automation may greatly speed up this procedure, increasing data extraction’s effectiveness and lowering the error rate. This blog will present a step-by-step process to scrape data from password-protected websites from the website’s structure analysis to handle typical challenges like CSRF tokens and CAPTCHAs, maintain sessions and cookies, navigate login methods, by utilizing Python libraries including the BeautifulSoup, Scrapy and Selenium.
Step 1: Examining The Website’s Structure
Before scraping data from a password-protected site, the primary step is to examine the website’s structure, login component, and data retrieval process. It includes reviewing the site utilizing developer tools that can be accessible in most browsers by tapping F12 or right-clicking and then choosing Inspect to understand the way authentication operates.
Begin by heading to the login page and inspecting whether it employs a basic HTML form or a more complex JavaScript-based verification framework. If that is a form-based login, explore for the form’s action URL, required input areas like username, password, or CSRF tokens, and the strategy utilized, such as POST or GET. If JavaScript is included, you’ll require Selenium or Puppeteer rather than standard requests-based strategies.
Following, look at the cookies, headers, and session management. Once you log in manually, assess the network traffic beneath the Network tab in developer tools. Determine the requests sent, the response status codes, and any cookies or authorization tokens that have been received. Some sites utilize JWT or session cookies for confirmation, which must be sent alongside requests.
With a thorough analysis of the website’s login mechanism, you can determine the finest approach for programmatic access so that you can effectively verify and retrieve protected content in the afterwards phases.
Step 2: Setting Up An HTTP Session
After the website structure analysis is done, the next step is to set up an HTTP session to handle requests proficiently. It guarantees that authentication credentials hold on over multiple requests, permitting consistent access to ensured pages.
In Python, the requests library is generally utilized for this purpose. Rather than sending individual requests that mandate re-authentication per time, a session object (requests.Session()) automatically keeps up cookies and headers. It can mirror a genuine browser session, anticipating the need to log in over and over.
To begin with, initialize a session and define the vital headers. Most sites demand at least a User-Agent header to dodge bot detection. Supplementary headers like Referer, Origin, and Accept-Language may also be required, and they can be replicated from browser requests utilizing developer tools.
After that, if the site employs cookies for verification, the session will automatically store and reuse them. If the login process yields an authentication token such as JWT, it should be extracted from the response and included in consequent requests via headers.
With an appropriate configuration of session handling, the user can stay logged in and get to restricted content proficiently, gearing up for the authenticating and logging-in phase.
Step 3: Logging Into The Site Programmatically
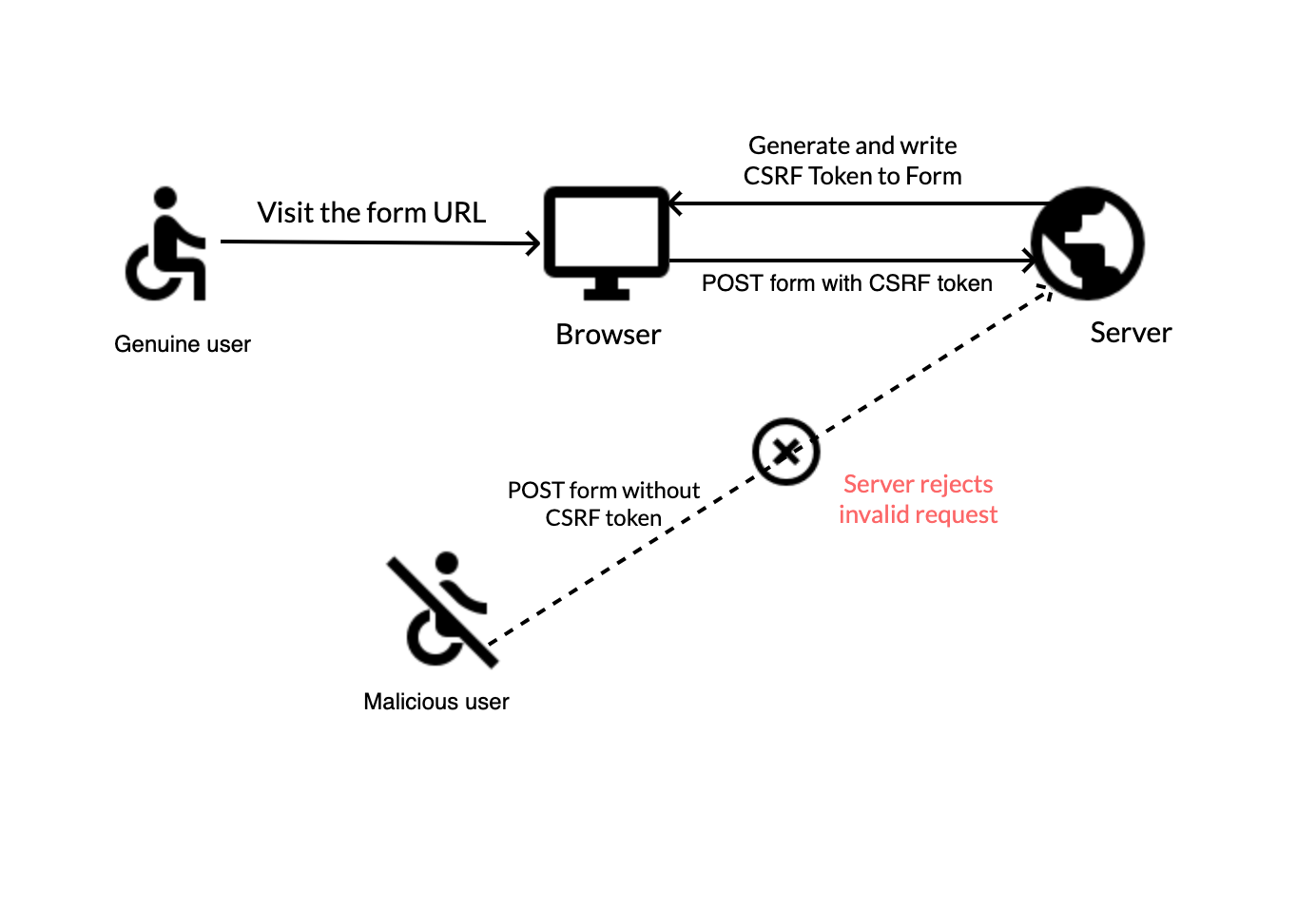
This step is about authenticating by logging into the site programmatically. It includes sending the proper credentials and dealing with any security measures such as CSRF tokens, captchas, or multi-factor authentication.
To begin with, you need to identify the login URL and required form fields utilizing browser developer tools. Most sites need at least a username or email and password, but some also incorporate hidden fields such as CSRF tokens. In case a CSRF token exists, you first need to get it from the login page and incorporate it into the POST request.
Utilizing the requests library in Python, pass a POST request with the login payload inside a session. Look into this example:
import requests
session = requests.Session()
login_url = “https://example.com/login”
payload = {
“username”: “your_username”,
“password”: “your_password”,
“csrf_token”: “extracted_token”
}
response = session.post(login_url, data=payload)
After a successful login, the response could include authentication cookies or a session token. To affirm authentication, request a protected page and inspect the response status. If confirmation falls flat, examine the response for extra security measures, like captchas or headers blocking bots.
This stage will guarantee you’ve got a dynamic session, permitting access to restricted content to extract information.
Step 4: Accessing The Protected Pages

After confirmation is done, the fourth step involves accessing the protected pages, including the information you need. As the session keeps up authentication, any request to restricted content will presently be treated as a verified user request.
Begin by identifying the URLs of the pages you need to scrape. You’ll be able to do this by getting through the site manually and utilizing browser developer tools via the F12 > Network tab to track requests that are created after login. Seek for URLs getting the desired data, whether as formal HTML pages or API endpoints returning JSON.
Utilizing the active session, pass a GET request to the target URL. Look into this code:
protected_url = “https://example.com/protected-data”
response = session.get(protected_url)
if response.status_code == 200:
print(“Access granted!”)
print(response.text) # Contains the page’s HTML or JSON data
else:
print(“Access denied. Check authentication.”)
If the request is blocked, check if extra authentication tokens are needed or if the site catches bot-like manners. For these cases, headers ought to be balanced to imitate a genuine browser, or JavaScript-based rendering may require Selenium.
After the page content is effectively retrieved, the following step is to extract the required information.
Step 5: Extracting The Specified Data

Once you have accessed the protected pages, it’s time to extract the specified data from the response. Per the way the data is organized, you will have to parse HTML, JSON, or XML utilizing diverse libraries like the following.
In case the response has HTML, you will utilize BeautifulSoup to parse and extract particular components utilizing this example:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, “html.parser”)
data = soup.find_all(“div”, class_=”target-class”) # Adjust selector based on structure
for item in data:
print(item.text.strip())
Utilize developer tools via F12 > Inspect Element to discover the right HTML tags and traits for scraping.
On the off chance that the site offers JSON data, you will extract and process it utilizing the json module this way:
import json
data = response.json() # Converts JSON response to Python dictionary
print(data[“key”]) # Access the required field
If the data has further pages, inspect it for pagination URLs like ?page=2. Loop through pages employing a dynamic request like the following:
for page in range(1, 6): # Adjust range based on total pages
paginated_url = f”https://example.com/data?page={page}”
page_response = session.get(paginated_url)
# Process data as before
After the data is extracted, the ultimate step involves storing and handling it effectively.
Step 6: Storing And Processing The Extracted Content
The final phase is about storing and processing the extracted content in a proper format for further investigation or utilization. Per the sort of information and your prerequisites, you’ll save it in CSV, JSON, databases, or other storage forms.
If the information is tabular, you can store it in a CSV file utilizing the CSV module the following way:
import csv
data_list = [(“Name”, “Price”), (“Product A”, “$10”), (“Product B”, “$20”)]
with open(“scraped_data.csv”, “w”, newline=””, encoding=”utf-8″) as file:
writer = csv.writer(file)
writer.writerows(data_list)
If you have structured information, JSON could be an adaptable format. You can use it this way:
import json
data_dict = {“products”: [{“name”: “Product A”, “price”: “$10”}, {“name”: “Product B”, “price”: “$20”}]}
with open(“scraped_data.json”, “w”, encoding=”utf-8″) as file:
json.dump(data_dict, file, indent=4)
Similarly, in case of large-scale information, you will store it in an SQL database utilizing SQLite the following way:
import sqlite3
conn = sqlite3.connect(“scraped_data.db”)
cursor = conn.cursor()
cursor.execute(“CREATE TABLE IF NOT EXISTS products (name TEXT, price TEXT)”)
cursor.execute(“INSERT INTO products VALUES (?, ?)”, (“Product A”, “$10”))
conn.commit()
conn.close()
After the information is put away, it can be further handled, examined, or utilized for automation. At this point stage, be sure about the data validation, error handling, and ethical adherence to scraping approaches.
Conclusion
In summary, a lot of valuable information is available online; there may be instances where a website requires a password to view. Scraping important data, even from password-protected websites, is feasible with the help of scraping tools like Python libraries and other approaches like those discussed in this blog. From basic authentication to managing more complicated tasks, such as evading CSRF tokens and anti-bot measures, you can eventually achieve a simplified scraping process. Nevertheless, you must be aware of the target site’s scraping policies and legislation in order to adhere to privacy and personal data issues for desirable outcomes.
