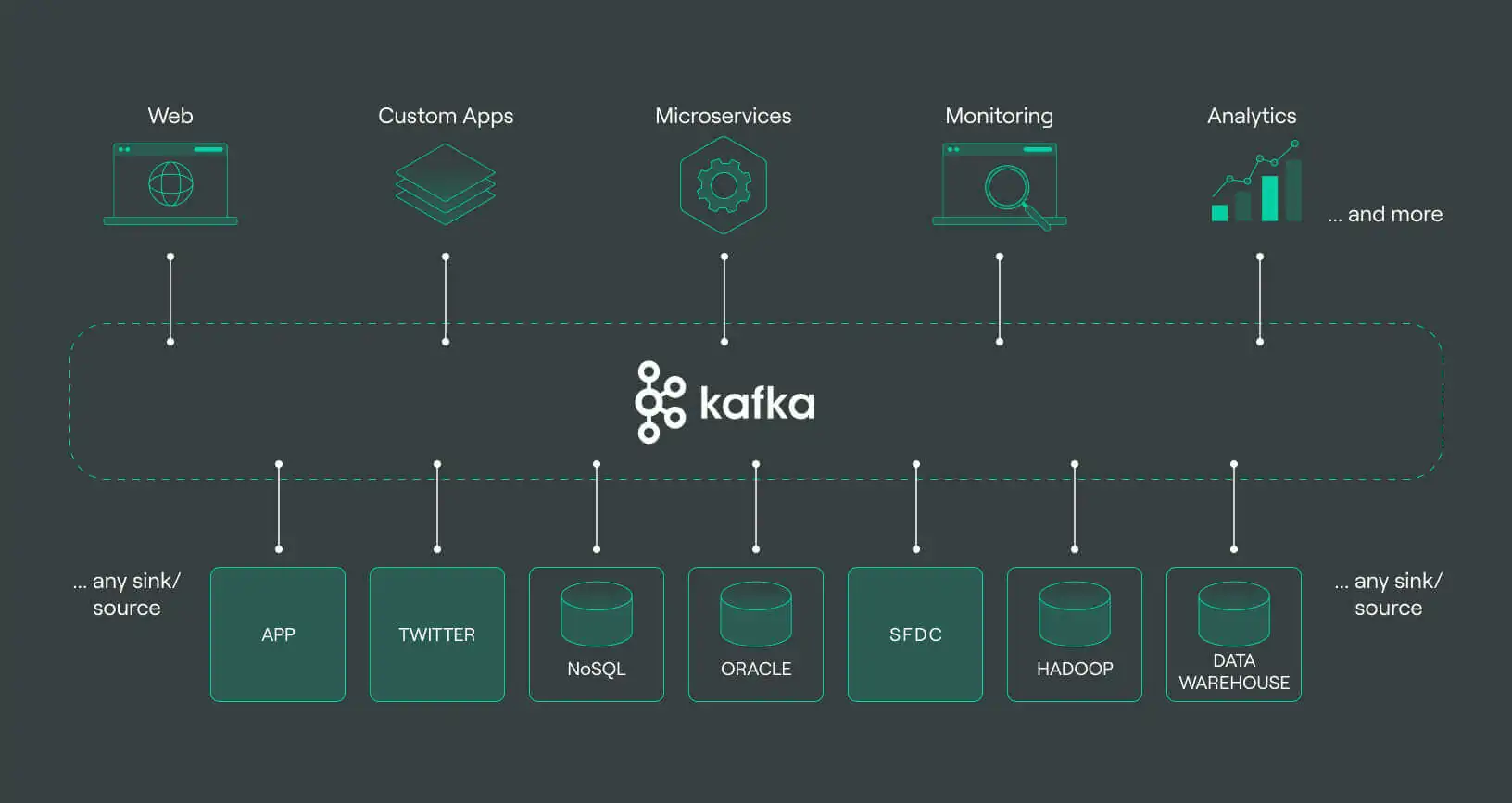
How To Use Apache Kafka For Real-Time Web Scraping
The open-source Apache Kafka distributed streaming system is used for large-scale data integration, real-time data pipelines, and stream processing. Kafka, which was first developed in 2011 at LinkedIn to manage real-time data streams, swiftly transformed from a messaging queue to a complete event streaming platform that could process over a million messages per second, or trillions of messages every day. Moreover, in the process of scraping data from various sites, this tool is really a helping hand for persistent data flow, fault resilience and scalability. Though typically, Python libraries like BeautifulSoup, Scrapy and Selenium are employed for scrapping the integration of Apache Kafka in this workflow offers a scalable, fault-tolerant, distributed platform facilitating the collecting, processing, and storing of high-volume streams. Kafka data integration enables enterprises to handle and process enormous quantities of data from many sources. Working side by side with Python libraries, Apache Kafka proficiently handles the real-time streaming and processing of the scraped data. The thorough process of real-time web scraping combining Apache Kafka is as follows.
Step 1: Setting Up Kafka On Your System
To utilize Apache Kafka for real-time web scraping, primarily you will be setting up Kafka on your system or employing a handled Kafka service. Kafka mandates that Java, like JDK 8 or later, operate, so you will begin by installing Java if it is not already accessible. After that, download Kafka from the official Apache site and extract the files.
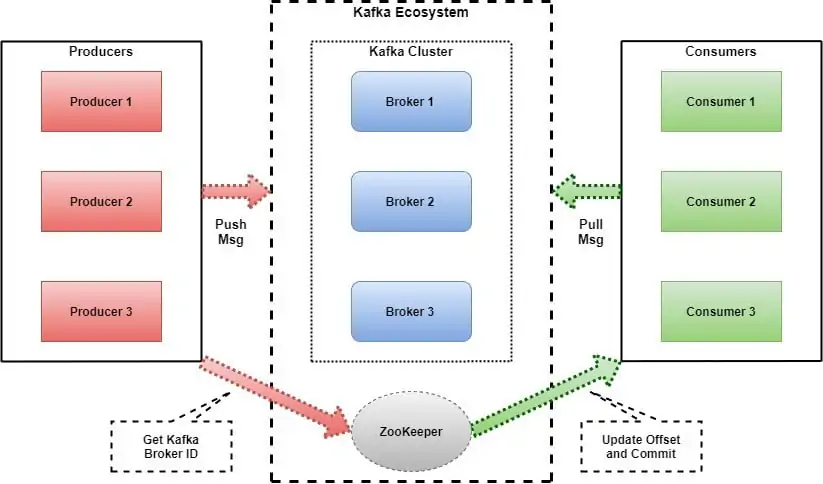
Since Kafka executes on a distributed architecture with a Zookeeper service that aids overseeing brokers. So, you will begin by assembling the Zookeeper, which is incorporated into Kafka’s package. To initiate Zookeeper, you will have to run the command as mentioned below:
bin/zookeeper-server-start.sh config/zookeeper.properties
After the Zookeeper is operating, you will initiate the Kafka broker like this:
bin/kafka-server-start.sh config/server.properties
It will launch a single-node Kafka setup, which is adequate for testing but should be developed for production usage. If you are employing a cloud-managed Kafka service such as Confluent Cloud, AWS MSK, or Azure Event Hubs, you’ll make a Kafka cluster via their UI and connect utilizing the assigned credentials.
Lastly, test the setup by creating a topic and sending sample messages to ensure that Kafka is functional. Utilize Kafka’s CLI tools or a client library such as kafka-python to confirm that messages are published and consumed accurately.
Step 2: Creating A Web Scraper

After setting up Kafka, create a web scraper to extract real-time information from sites. The selection of web scraping tools hinges on the complexity of the site and the format of the data. Standard Python libraries for web scraping incorporate BeautifulSoup, Scrapy, and Selenium.
In the case of static websites, BeautifulSoup with requests is a productive solution. A basic scraper can be implemented considering the following example:
import requests
from bs4 import BeautifulSoup
url = “https://example.com”
response = requests.get(url)
soup = BeautifulSoup(response.text, “html.parser”)
data = soup.find_all(“p”) # Extracts all paragraph text
for item in data:
print(item.text)
If you are dealing with dynamic websites that depend on JavaScript, Selenium could be a superior choice. Look into the following example.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(“https://example.com”)
content = driver.page_source
print(content)
driver.quit()
The scraper ought to be optimized for speed and proficiency, taking care of retries and avoiding getting blocked by utilizing user-agent rotation and proxy servers. After the scraper collects the specified data, the following phase involves sending this information to Kafka for real-time processing.
Step 3: Sending The Collected Data To A Kafka Topic
The third step is about sending the collected data to a Kafka topic and employing a Kafka producer. It will permit real-time streaming of scraped information, making it accessible for customers to further handle.
Use the following code and install the kafka-python library, which is to communicate with Kafka in Python.
pip install kafka-python
After that, you will create a Kafka producer that passes messages or scraped data to a particular Kafka topic. Consider the example provided below.
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers=’localhost:9092′,
value_serializer=lambda v: json.dumps(v).encode(‘utf-8’)
)
topic = “scraped_data”
# Example scraped data
data = {“title”: “Sample Article”, “content”: “This is some scraped content.”}
producer.send(topic, data)
producer.flush()
print(“Data sent to Kafka topic successfully!”)
Adjust the web scraper to persistently send new information to Kafka as it scrapes, confirming real-time streaming. Execute error handling and retries to handle network problems and prevent information loss.
After the producer effectively sends data to Kafka, customers can handle and store it in real-time. The following step is to construct a Kafka consumer for retrieval and analysis of the scraped data.
Step 4: Building A Kafka Consumer
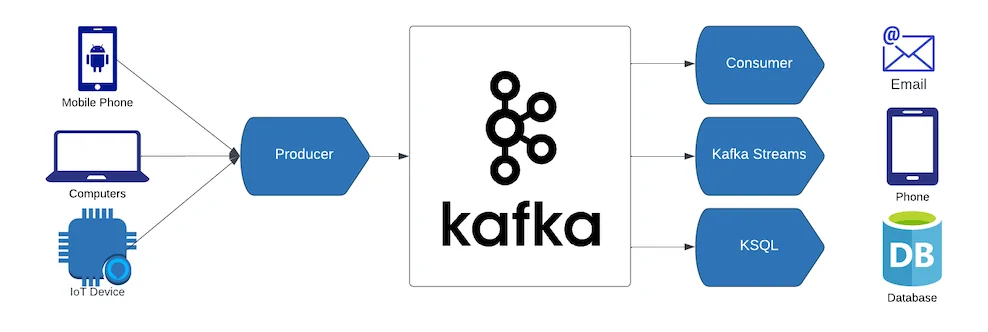
This step involves building a Kafka consumer to retrieve and handle this information in real-time. The consumer will read messages from the Kafka topic, facilitating further examination, modification, or storage within a database.
First of all, you have to make sure that you have the kafka-python library installed. You can utilize the code below:
pip install kafka-python
You have to create a Kafka consumer who subscribes to a topic and constantly listens for further messages. Look at the below example of a basic Kafka consumer in Python:
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
‘scraped_data’,
bootstrap_servers=’localhost:9092′,
auto_offset_reset=’earliest’,
value_deserializer=lambda x: json.loads(x.decode(‘utf-8’))
)
print(“Listening for new messages…”)
for message in consumer:
data = message.value
print(f”Received data: {data}”)
Arrange or organize the scraped text also, filter out the pointless information, or consider extracting essential insights.
Once done with data handling, store the handled data in a database such as PostgreSQL, MongoDB, or Elasticsearch for further investigation.
Kafka permits multiple customers to perform in parallel by partitioning data into segments. It can enhance scalability, guaranteeing high-speed handling of expansive data streams.
After the consumer is set up and addressing data proficiently, the next phase is to store or examine the data for significant insights.
Step 5: Data Storage And Examination
This step is important for either you just want to store data or want to examine it for further use. You will select storage or analysis tools based on the sort of data and functional requirements.
If you have structured data, relational database options such as PostgreSQL or MySQL are great alternatives. Alternatively, in the case of unstructured or semi-structured information, NoSQL databases such as MongoDB or search engines like Elasticsearch are ideal.
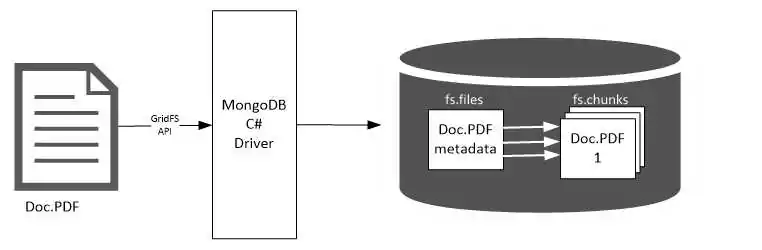
Here is an example to keep data in MongoDB:
from pymongo import MongoClient
client = MongoClient(“mongodb://localhost:27017/”)
db = client[“scraped_data_db”]
collection = db[“articles”]
def store_data(data):
collection.insert_one(data)
print(“Data stored successfully!”)
To store information in PostgreSQL, you will utilize psycopg2 to insert information into tables.
To examine data in real-time, you can opt for tools such as Apache Spark Streaming, Flink, or Elasticsearch with Kibana.
Following is an example of Elasticserach utilization data visualization.
from elasticsearch import Elasticsearch
es = Elasticsearch([“http://localhost:9200″])
es.index(index=”scraped_data”, body={“title”: “Example”, “content”: “This is sample content”})
As required, you can think about applying NLP models for sentiment examination, keyword extraction, or summarization before storing information.
Once you are done with data storage or analysis, the ultimate step is to scale and screen the framework to optimize performance.
Step 6: Monitoring The Performance
If you have to deal with extensive real-time web scraping, you must optimize Kafka for versatility. Expanding the number of partitions in a topic authorizes numerous clients to handle information concurrently, progressing effectiveness. Deploying Kafka in a multi-broker cluster makes sure about the sounder load distribution and averts failures. The web scraper should also be reformed by executing offbeat requests, utilizing rotating proxies to maintain a strategic distance from IP bans, and limiting requests per moment to avoid over-burdening target sites.
Persistent monitoring helps catch issues before they affect information assemblage. Prometheus and Grafana offer real-time metrics on Kafka broker health, topic lag, and consumer execution. Also, the Kafka Manager or Kafdrop can be utilized to examine topics and guarantee messages are smoothly processed. To keep an eye on scraper productivity, logging tools, including ELK Stack or Splunk, assist in analyzing errors and request bummers.
To avoid data loss, Kafka replication ought to be activated so messages stay open even in case a broker crashes. Consumers ought to execute checkpointing to renew from the final processed message. Utilizing dead letter queues, DLQ helps store tricky messages independently without blocking the central information flow.
So long as the volume of scraped data grows, framework resources must be refined. Kafka consumers ought to be evenly scaled to handle more oversized workloads. Database indexing ought to be implemented to accelerate storage and retrieval. Standard performance testing guarantees smooth operation and minimizes downtime, keeping the real-time web scraping framework stable and proficient.
Conclusion
In summary, Apache Kafka can help manage the data of several web pages at once since it is made to handle massive amounts of data. When you need to expand the crawling capacity, it can be readily scaled horizontally by adding more brokers. Kafka also offers durability, guaranteeing that your scraped data is kept safe even in the event of errors. Real-time data processing using Kafka enables instantaneous analysis or archiving of gathered data. Apache Kafka can be a great option if your web scraping project has to handle a lot of data, be scalable, and benefit from a real-time processing architecture.
