How To Use Scrapy’s Item Pipeline For Data Processing
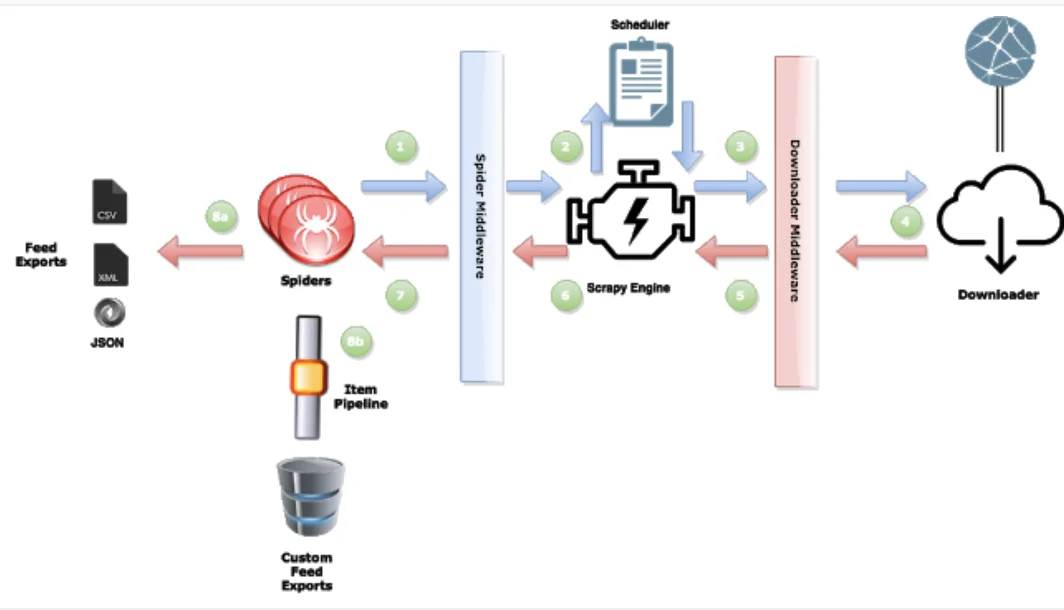
Scrapy has generated a lot of attention, which is well-deserved. It is a robust and free web scraping tool that allows for multiple requests at once and is relatively simple to use. Its Item Pipeline function, which processes the scrapped items, is an essential tool for handling extensive amounts of data. After being delivered to the Item Pipeline, an item is scraped by a spider and processed using a number of successively run components. Item pipelines are commonly used to clean HTML data, validate data that has been scraped, like ensuring that specific fields are present in the items, check for duplicates, and store the scraped item in a database. By using Scrapy’s item pipeline, the users can attain a well-structured and reliable quality of data to confidently utilize for various purposes, including further analysis. This blog includes a step-by-step approach to simplify the process of using Scrapy’s item pipeline for data processing.
Step 1: Defining An Item
Generally, inside Scrapy, items act as containers for putting away organized information that was extracted from various web pages. They work the same as Python dictionaries, though offering extra advantages, including field validation and adequate organization. By defining an item, you can guarantee that all scraped information follows a steady format, making it simpler to handle through Scrapy’s Item Pipeline.
To begin defining an item, you will make a new Python file like items.py inside your Scrapy project and specify a class that acquires from Scrapy.Item. Each attribute in this class will speak to a data field that will be extracted. Scrapy offers scrapy.Field() to define fields, which allows flexibility to keep metadata or apply changes later within the pipeline.
Look into the following example for redefining an item:
import scrapy
class ProductItem(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
category = scrapy.Field()
url = scrapy.Field()
In the above example, the ProductItem class bears fields to store product-related information. After it is defined, these fields can be settled inside a Scrapy spider and passed through the item pipeline to process further, such as cleaning, validating, or storing. Appropriately defining an item is the basis for an effective data processing workflow in Scrapy.
Step 2: Activating The Item Pipeline
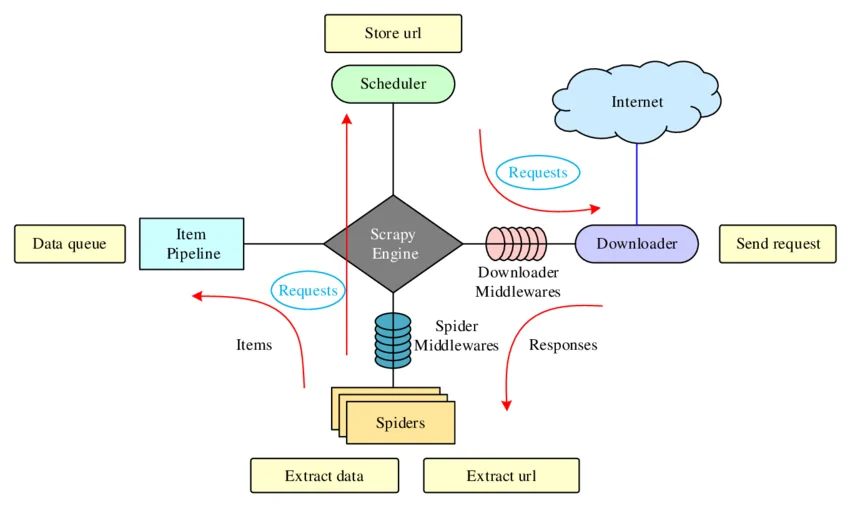
Once you have defined an item, the second phase involves enabling the Scrapy Item Pipeline within the project’s settings file. The pipeline is capable of handling and storing scraped information, and empowering it will confirm that items have passed the specified preparation steps.
Scrapy allows numerous pipeline classes to be utilized at the same time. Each pipeline is allotted an integer priority; usually, the lower numbers run first. To empower a pipeline, you will open the settings.py file in your Scrapy project and include the pipeline class with a priority value within the ITEM_PIPELINES dictionary.
Consider this example to enable the Pipeline:
# settings.py
ITEM_PIPELINES = {
‘myproject.pipelines.CleaningPipeline’: 300,
‘myproject.pipelines.DatabasePipeline’: 500,
}
In this, CleaningPipeline runs first, and then DatabasePipeline. Usually, the lower numbers suggest higher priority.
Enabling the pipeline ensures that scraped items move smoothly through the processing phases. Furthermore, it facilitates data cleaning, approval, and storage independently.
After it is enabled, the pipeline will process each item returned by the spider, securing effective data handling within the Scrapy project.
Step 3: Composing A Pipeline Class
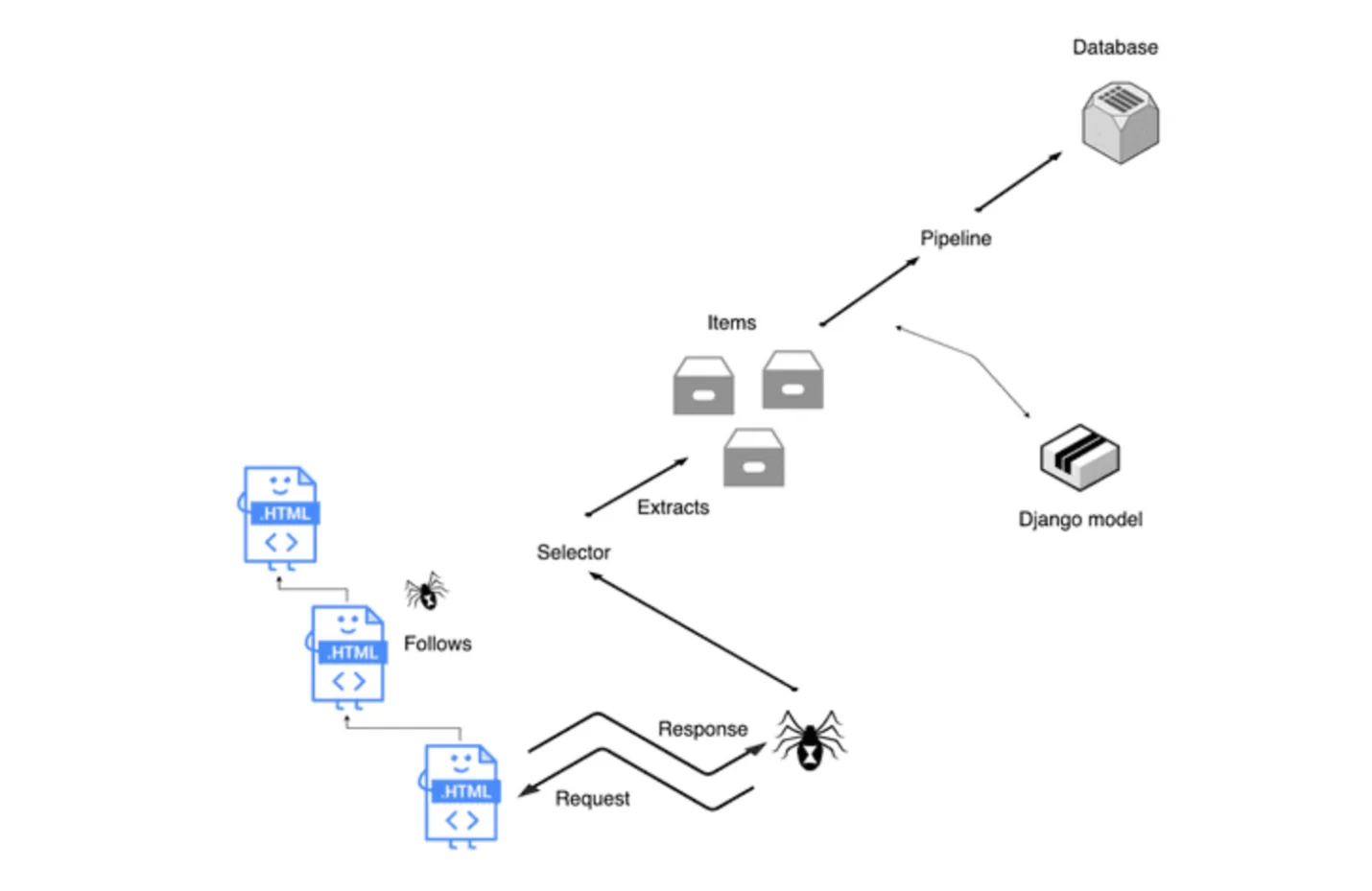
The third step is about creating a custom pipeline class that processes scraped items. A pipeline class supports the execution of tasks like data cleaning, approval, and storage. Scrapy can automatically send each item through the defined pipeline classes, permitting efficient data processing.
To form a pipeline, open or make a file entitled pipelines.py inside your Scrapy project directory. At that point, define a class that incorporates a process_item strategy, which Scrapy calls for each item sent through the pipeline.
Here is an example of creating a data-cleaning pipeline:
class CleaningPipeline:
def process_item(self, item, spider):
# Remove leading/trailing spaces from string fields
item[‘name’] = item[‘name’].strip() if ‘name’ in item else None
item[‘category’] = item[‘category’].strip() if ‘category’ in item else None
# Convert price to float
if ‘price’ in item:
item[‘price’] = float(item[‘price’].replace(‘$’, ”).strip())
return item
Creating a pipeline class can provide you with consistency in formatting and validation. It also helps remove pointless characters, convert data types, and handle lost values.
Finally, by creating a pipeline class, you make sure the item is within the correct format before storing it in a database or file.
After defining a pipeline class, Scrapy can proficiently prepare and plan data before it is stored or exported.
Step 4: Sending Items Through Pipeline
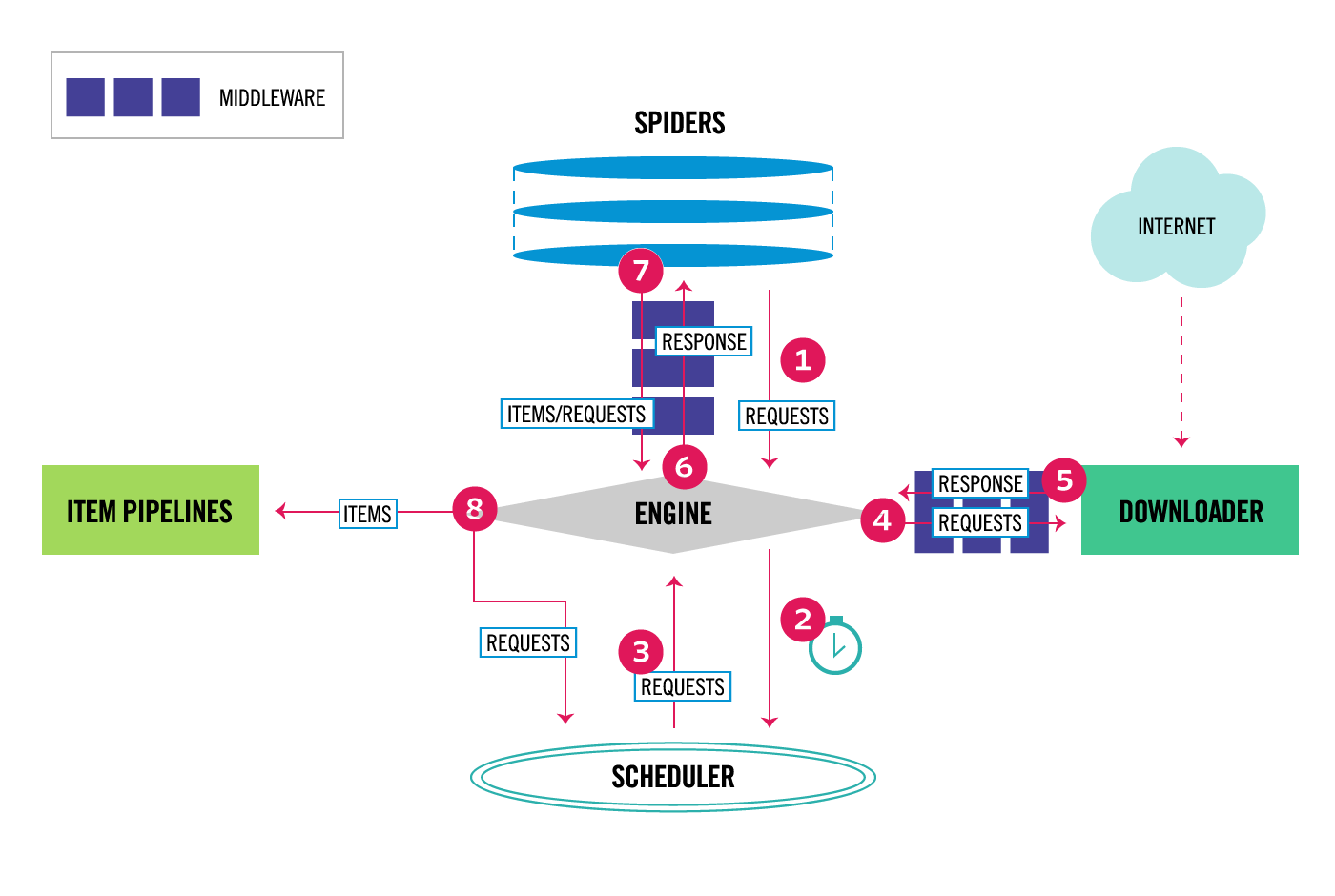
After the pipeline class is created, Scrapy consequently sends scraped items through it. The process_item strategy inside the pipeline class is where the factual data processing occurs. Each pipeline class can alter, approve, or filter items before they continue to the following stage or are stored.
At the time when a spider yields an item, Scrapy passes it through the pipelines within the order specified in settings.py. The process_item strategy must return the adjusted item, or else Scrapy will drop it from additional processing.
Look into this example to process items within the pipeline:
class ValidationPipeline:
def process_item(self, item, spider):
# Ensure name and price fields are not empty
if not item.get(‘name’) or not item.get(‘price’):
raise DropItem(f”Missing required fields in {item}”)
# Ensure price is positive
if item[‘price’] <= 0:
raise DropItem(f”Invalid price: {item[‘price’]}”)
return item
Processing Items within the Pipeline cleans data by expelling undesirable characters, formats strings, and normalizing data.
It also guarantees that all vital areas are present and values are accurate.
Dropping the items that do not meet particular criteria helps avoid unreasonable data.
With the execution of the process_item strategy, Scrapy makes sure that exclusively high-quality and structured information moves forward within the pipeline.
Step 5: Storing The Data
Once you are done processing and validating the items in the pipeline, you will need to store or export the information. Scrapy’s item pipeline permits storing information in various forms, including databases, CSV files, JSON, and external APIs. This ultimate phase in data processing guarantees that the extracted data is saved effectively for afterwards utilization.
Here is an example of storing data in a database:
Look into the code below for saving items in a MongoDB database, defining a pipeline class that interfaces to the database and inserts the prepared items.
import pymongo
class MongoDBPipeline:
def __init__(self):
self.client = pymongo.MongoClient(“mongodb://localhost:27017/”)
self.db = self.client[“scrapy_database”]
self.collection = self.db[“products”]
def process_item(self, item, spider):
self.collection.insert_one(dict(item))
return item
If you want to store data in other options like JSON, you can do it this way:
import json
class JsonPipeline:
def open_spider(self, spider):
self.file = open(‘output.json’, ‘w’)
def process_item(self, item, spider):
json.dump(dict(item), self.file)
return item
def close_spider(self, spider):
self.file.close()
Similarly, to save data as CSV, you will use the built-in feed exports of Scrapy, just this way:
scrapy crawl my_spider -o output.csv
By storing data in a pipeline, you save the processed items automatically and are supported in multiple formats, including JSON, CSV, API, and databases. It also prevents duplicate or inaccurate entries.
This phase completes the information extraction and processing pipeline, making the scraped data functional for analysis, reporting, or further usage.
Step 6: Running The Spider
The last step involves running the Scrapy Spider to watch how the data flows via the pipeline. Operating the spider initiates the whole Scrapy framework, allowing the pipeline to handle each scraped item by degrees.
To begin the process of running the Spider, you will head to your Scrapy project directory. Then, you need to use the following command:
scrapy crawl my_spider
Following is an example to follow in case you need to save the yield in a particular format:
scrapy crawl my_spider -o output.json
Alternatively, you can use this:
scrapy crawl my_spider -o output.csv
For the verification of the pipeline execution, you will first check the scrapy logs to ensure that items are passing through the pipeline.
After that, you will ensure that the information is cleaned, approved, and stored accurately.
If you are employing a database, confirm that records are inserted effectively.
The Running of the Spider is critical since it makes sure that each item streams through defined processing steps.
Moreover, it Identifies errors in item fields, pipelines, or storage while producing a structured yield for analysis or utilization.
After running the spider effectively, your Scrapy Item Pipeline is completely operational, processing and storing organized web information proficiently.
Conclusion
In summary, the data we usually scrape can be extremely disorganized and unstructured, including having extraneous information and an incorrect format. Consequently, the use of Scrapy’s item pipeline to process that scrapped data can help us in many ways, including data cleaning, formatting, validating, storing and more. It works best in situations that are more complicated and require further processing of the material that has been scraped. In brief, with no additional code, the item pipeline offers a simple and adaptable method of managing the output of scrapy items.
