
How To Scrape Data From Online Forums And Discussion Boards
Online forums and discussion boards are confirmed to be the treasure houses of user-generated data in the form of public reviews, consumer feedback, or industry-related discussions. A multitude of information about the attitudes, actions, and requirements of customers can be found in these forums. Consumers often discuss their experiences and present a source of data and input that businesses can use to better understand their target market and make strategic choices. Using robust scraping approaches, analysts can gather this vast data to identify trends and sentiments, thus benefitting businesses. In the process of scrapping data from online forums and discussion boards, the main objective is to extract pertinent data like posts, usernames, thread titles, etc. However, data extraction and scraping from such websites are not like simply scraping data from common sites. The websites containing consumer forums and discussion boards have elaborate layouts, pagination, and also JavaScript-heavy content; all such aspects make them formidable to scrape. This blog will provide a detailed process to effectively scrape consumer opinion-related data from online forums and discussion boards to aid enterprises in decision-making.
Step 1: Specify The Online Forums Or Discussion Boards You Need To Scrape

The first step to scraping websites from online forums and discussion boards is to specify the online forums or discussion boards you need to scrape. Concentrate on platforms that adapt to your information collection objectives. For instance, if you are analyzing buyer feedback on products, choose forums such as Reddit or specialized product review platforms. Make sure that the forum is available without registration or features a guest access possibility; if verification is mandated, note the credentials required.
After you have chosen a forum, identify the particular sections or threads where the required data is located. Forums generally diverge into categories, subcategories, and threads, so condensing your target area can save time and effort during the scraping process. Pay attention to whether the forum supports highlights such as pagination or filtering, as these can affect your scraping strategy.
Finally, be sure to review the forum’s terms of service and policies to affirm that web scraping is authorized. Mindful scraping incorporates respecting legal and ethical limitations to prevent infringing on user privacy or the rules of the platform.
Step 2: Examine The Website’s Structure
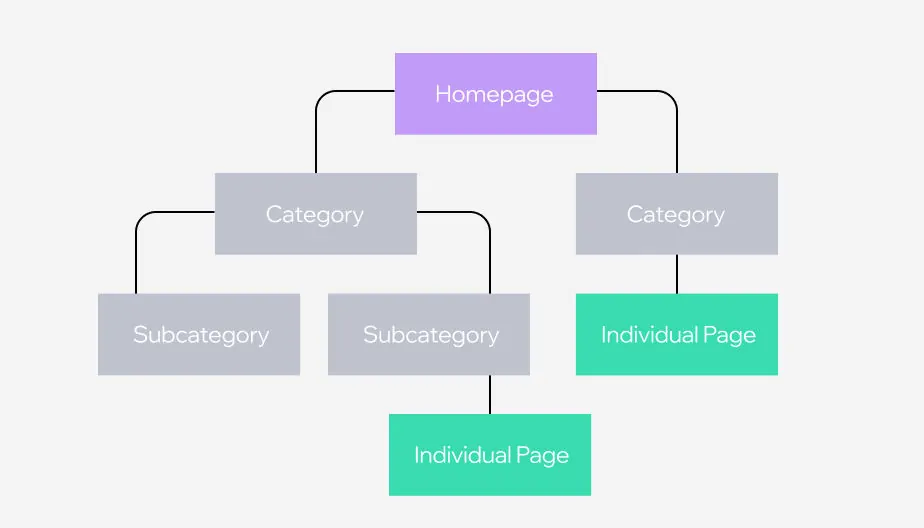
After the target forum is chosen, the second step is to examine its structure to comprehend how data is displayed. Open the forum in your web browser and utilize the built-in developer tools that you can usually access by taping F12 or right-clicking to select Inspect to interpret the HTML layout. Determine the tags, classes, or attributes that include the particular information you need, like user comments, usernames, timestamps, or thread titles.
Search for steady patterns within the HTML layout across different threads or posts, as this makes a difference when making a proficient scraping script. For instance, usernames could be inside <div> tags with a particular class title, while comments could be wrapped in <p> or <span> tags.
Check if the forum operates dynamic loading with JavaScript, like content loads as you scroll, or if it depends on AJAX requests. Dynamic content may demand employing a tool like Selenium for page rendering or capturing API requests through the Network tab for productive data extraction.
Step 3: Select A Scraping Tool
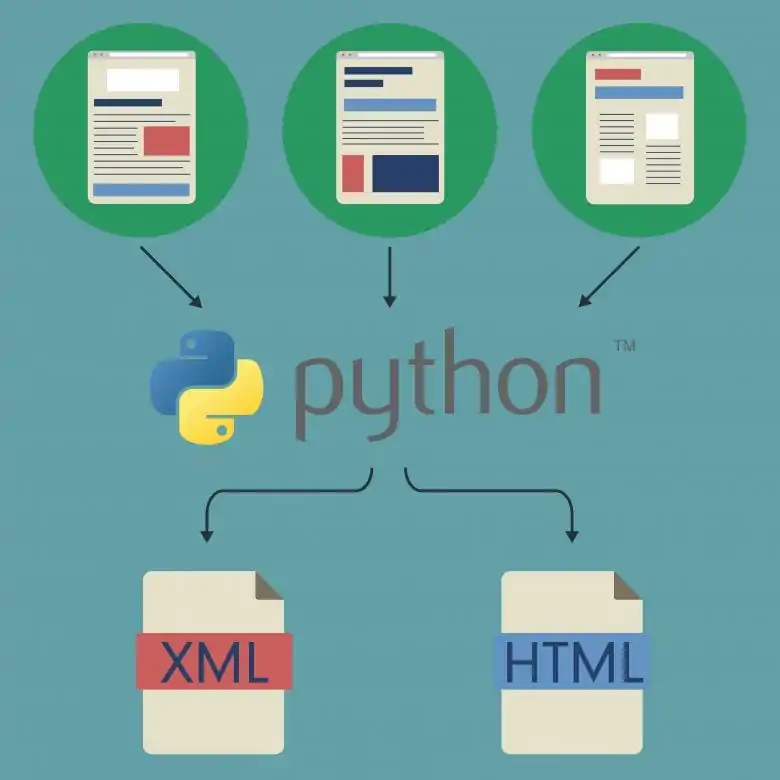
Picking the proper web scraping tool or library is vital to effectively extract data from forums. Prevalent Python libraries incorporate BeautifulSoup to parse HTML, Selenium for dealing with dynamic content, and Scrapy for large-scale scraping projects. Your selection counts on the forum’s format and intricacy.
If the forum utilizes static HTML, BeautifulSoup coalesced with Requests is typically adequate for extracting information. On the other hand, for forums with dynamic content that loads through JavaScript, Selenium is more appropriate since it can render web pages just like a browser. Then again, if you are dealing with big-volume data scraping, Scrapy presents robust crawling and scaling traits.
Take under consideration the forum’s security attributes, like CAPTCHA or anti-bot mechanisms. To evade them ethically, tools such as Captcha Solver APIs can be combined if allowed. Furthermore, look into the programming language you’re pleased with; while Python is highly suggested due to its endless library environment, you should also explore other tools, such as Puppeteer, for JavaScript scraping chores.
Step 4: Create The Script
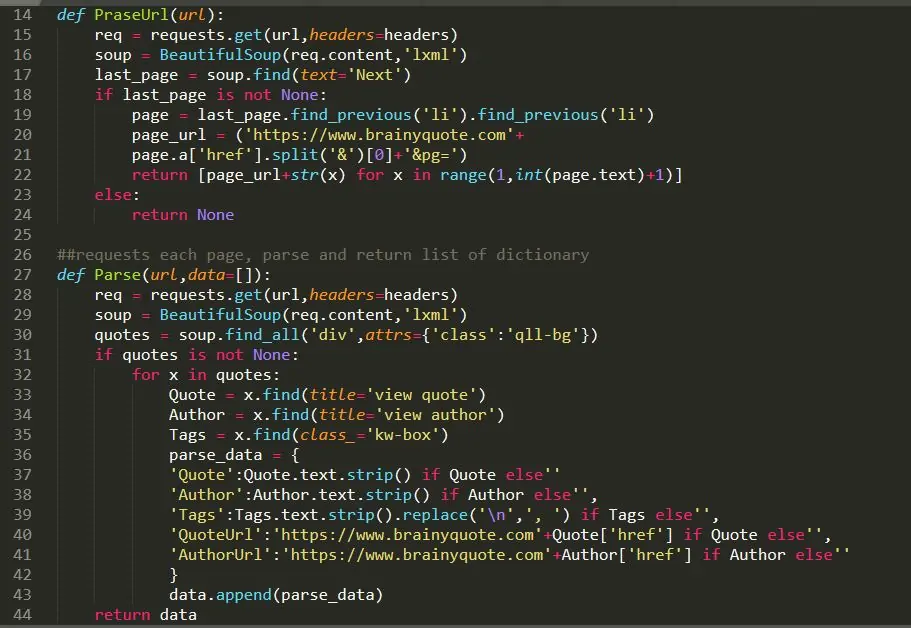
The fourth step includes creating the script that fetches information from the forum utilizing the selected scraping tool. Begin by importing the vital libraries, like requests and BeautifulSoup, for static HTML scraping or Selenium for dynamic content. Utilize the requests library to send an HTTP GET request to the forum’s URL and retrieve its HTML content. The following is an example:
import requests
from bs4 import BeautifulSoup
url = “https://example-forum.com/thread”
response = requests.get(url)
html_content = response.content
soup = BeautifulSoup(html_content, ‘html.parser’)
In this example, the soup object contains the parsed HTML, and you’ll utilize strategies like find() or find_all() to find particular elements, like post titles or comments.
In case of dynamically loaded content, you will utilize Selenium to launch a browser and load the page:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(“https://example-forum.com/thread”)
html_content = driver.page_source
Comprehensively test your script by printing gathered data and guaranteeing it accommodates your target. Handle errors such as broken links or missing elements focused on exception handling.
Step 5: Navigate The Multiple Pages
Most forums distribute data over different pages, particularly in threads with broad discussions. To scrape all the desired data, your script must navigate these pages methodically. Begin by analyzing the pagination structure within the forum’s HTML utilizing the browser’s developer tools. Determine the component, like a “Next” button or numbered page links, that leads to another set of data.
For static pagination, URLs regularly have a parameter like page=2. Adjust this parameter programmatically to iterate through pages. The following is an example using requests:
for page in range(1, 11): # Scrape first 10 pages
url = f”https://example-forum.com/thread?page={page}”
response = requests.get(url)
soup = BeautifulSoup(response.content, ‘html.parser’)
# Extract and process data
In case of dynamic pagination that is handled by JavaScript, utilize Selenium to communicate with the “Next” button. Look into the following code:
next_button = driver.find_element(By.LINK_TEXT, “Next”)
while next_button:
next_button.click()
html_content = driver.page_source
# Extract and process data
next_button = driver.find_element(By.LINK_TEXT, “Next”)
Make sure that the loop terminates accurately to prevent infinite scraping attempts on the final page.
Step 6: Save The Scraped Data
Once you are done extracting the required data, the final step is to save it in a structured format for further investigation or processing. Standard storage formats incorporate CSV, JSON, or databases such as MySQL or MongoDB, depending on the scale and complexity of your project.
For simple projects, you’ll utilize Python’s built-in csv module to save information into a file. You can use the following code:
import csv
data = [[“Username”, “Comment”, “Timestamp”], [“user1”, “This is a comment”, “2025-01-03”]]
with open(“forum_data.csv”, mode=”w”, newline=””) as file:
writer = csv.writer(file)
writer.writerows(data)
Alternatively, for hierarchical or complex information, JSON could be an awesome option:
import json
data = [{“username”: “user1”, “comment”: “This is a comment”, “timestamp”: “2025-01-03”}]
with open(“forum_data.json”, mode=”w”) as file:
json.dump(data, file, indent=4)
For large-scale scraping, storing information directly into a database progresses organization and versatility. Utilize libraries such as pymysql or sqlalchemy for MySQL or pymongo for MongoDB to put extracted information effectively while overseeing duplicates and relationships.
Conclusion
To conclude, in the snappy digital world of today, information is crucial, particularly when it comes to promoting business expansion. Additionally, online forums are a terrific source for acquiring useful facts in the form of customer-relevant information. They are the gold mines of public opinion, which include the vast ideas of individuals from all walks of life. Correspondingly, web scraping offers a potent approach to extracting data from these forums, helping businesses gain insights from the exchanged ideas of the masses. Eventually, firms can obtain substantial insights into user attitudes, trends, and discussions occurring within these forums by scraping the forum’s data.
