How To Parse HTML With BeautifulSoup
Parsing HTML is a substantial skill for various tasks relevant to data collection and web development. To appease the task of parsing HTML, BeautifulSoup, which is a rich Python library, can empower users with intuitive ways to get into HTML documents. This library can stimulate you in multiple ways, including data extraction from sites, collection of complex data from web pages, and restructuring HTML into an easily coherent form. BeautifulSoup can provide you with a powerful set of relevant tools, which, primarily when used in combination with the Requests library, can empower you with an effortless process of parsing HTML content with the most nominal resistance. This blog will demonstrate the practical step-by-step process to parse HTML with BeautifulSoup. It will cover every minute detail, starting from the installation of required libraries to the final phase of making the extracted data error-free so that at the end you will have a thorough understanding of HTML parsing.
Step 1: Install The Essential Python Libraries
To start the process of parsing HTML with BeautifulSoup, you first have to install the essential Python libraries, which are BeautifulSoup and Requests. BeautifulSoup library will be utilized for parsing HTML and XML documents, and Requests libraries will handle HTTP requests to fetch the content of web pages.
Before coming to the main action, be sure that you have installed both libraries successfully. After that, open your terminal or command prompt and run the command as given below:
pip install beautifulsoup4 requests
Using this command, you can install the most recent version of the BeautifulSoup library and Requests. In case you’re employing a Jupyter notebook or a similar interactive environment, you’ll also be able to install these libraries directly from inside the notebook utilizing the same command beginning with an exclamation mark like this:
!pip install beautifulsoup4 requests
After installation, you need to import these libraries into your Python script or notebook. Import BeautifulSoup from the bs4 module, and Requests can be imported directly. Here’s a way to instantly import these libraries:
from bs4 import BeautifulSoup
import requests
After your libraries are successfully installed and imported, you can continue with the next step of fetching and parsing HTML content. This initial step is the basis for working with web data in Python.
Step 2: Fetching The HTML Content
The second step of parsing HTML with BeautifulSoup is fetching the HTML content of the web page you need to parse. You can choose the Requests library to make HTTP requests for a webpage and get its content effortlessly.
Choose which webpage you need to scrape. To illustrate it practically, let us use an example of http://example.com as our concerned URL.
Utilize the requests.get() function to send a request to the URL. This action will return a Response object, possessing the webpage’s content in its text attribute.
response = requests.get(‘http://example.com’)
html_content = response.text
Consider checking the effectiveness of the request by confirming the status code of the response; for example, a status code of 200 can imply that the request was effective.
if response.status_code == 200:
print(“Request successful”)
else:
print(f”Request failed with status code {response.status_code}”)
With the help of Requests, you have now fetched the raw HTML data from the chosen webpage, and now you can use it to parse with BeautifulSoup.
Step 3: Create A BeautifulSoup Object
After fetching the HTML data, you have to create a BeautifulSoup object. That object will let you parse, explore, and control the HTML document.
To initiate a BeautifulSoup object:
Utilize the HTML content fetched within the past step as input when making the BeautifulSoup object.
BeautifulSoup supports different parsers to select one of your preferences, from html.parser, lxml, and html5lib. Usually, the built-in html.parser functions well for the majority of the tasks and doesn’t demand any kind of external dependence. In case you would like more vigorous parsing, you can utilize lxml for speed and adaptability. The following example contains the html.parser:
soup = BeautifulSoup(html_content, ‘html.parser’)
In this example, html_content is the raw HTML you retrieved with Requests, while html.parser refers to the parser to be used.
Your soup object presently holds the whole HTML structure of the page which is parsed into an easily navigable format. Besides, BeautifulSoup will automatically fix broken tags, making the document well-shaped, and authorizing for simple extraction of components.
At this point, you can utilize different BeautifulSoup strategies to investigate and control the HTML tree, which will be covered in the next steps.
Step 4: Parsing The HTML
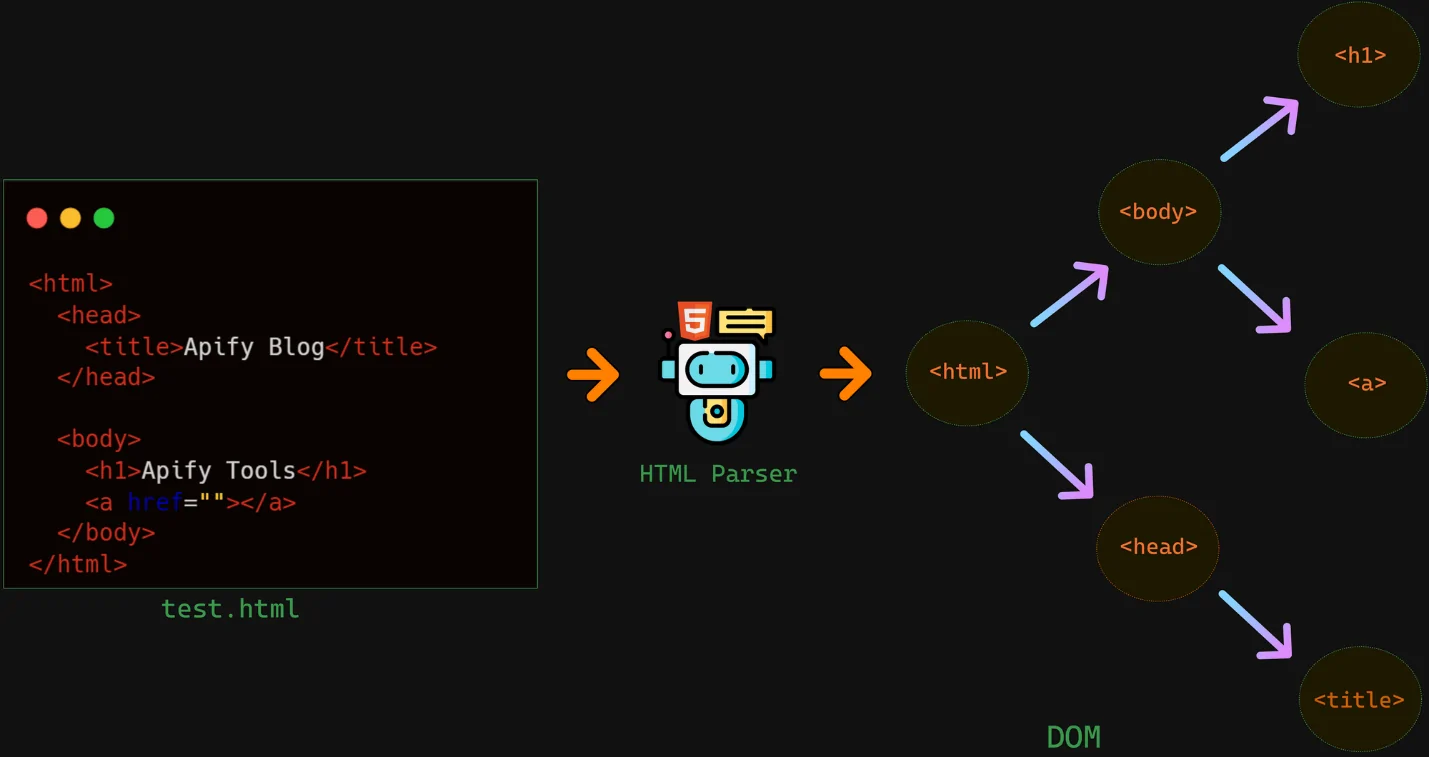
After creating the BeautifulSoup object, move on to the process of parsing the HTML and collecting the information you’re inquisitive about. BeautifulSoup offers several capable strategies to look, explore, and retrieve specific elements from the HTML document.
Utilize soup.find() to find the primary occurrence of a particular HTML tag. The following example is to locate the first h1 tag on the page:
h1_tag = soup.find(‘h1’)
print(h1_tag.text)
It will print the text in the tag. You can replace h1 with any other tag like p, div, and so on.
To discover all occurrences of a particular tag, utilize soup.find_all(). It can yield a list of all matching components. Look into the example given below to get all the tags on the page:
links = soup.find_all(‘a’)
for link in links:
print(link.get(‘href’))
The above code can print the href attributes (URLs) of all the anchor tags onto the page.
Moreover, BeautifulSoup permits you to look for components by class or ID. To discover a component with a particular ID, follow the:
element_by_id = soup.find(id=’specific-id’)
print(element_by_id.text)
To discover components with a specific class:
elements_by_class = soup.find_all(class_=’specific-class’)
for element in elements_by_class:
print(element.text)
Utilizing these methods, you can effectively extract the details you would like from the HTML.
Step 5: Structuring The Parsed Data
This step involves manipulating and structuring the parsed data to conform to your needs, which is vital for making the extracted data valuable to analyse, store, and present.
In the case of textual data, utilize ‘.text’ or ‘.get_text()’ to retrieve the discernable substance from HTML elements. Use the given code to get the text from all ” tags:
paragraphs = soup.find_all(‘p’)
for paragraph in paragraphs:
print(paragraph.get_text())
For attaining attribute values such as ‘href’ from anchor tags or ‘src’ from pictures, utilize the ‘.get()’ strategy as below:
for img in soup.find_all(‘img’):
print(img.get(‘src’))
Preserve the extracted information in an organized format, like in the form of lists, dictionaries, or Pandas DataFrames, according to the intricacy of the data:
links = [link.get(‘href’) for link in soup.find_all(‘a’)]
To further use, export the organized data to a CSV or JSON format, which you can do by utilizing Python’s built-in libraries or Pandas:
import pandas as pd
df = pd.DataFrame(links, columns=[‘URL’])
df.to_csv(‘links.csv’, index=False)
By organizing and exporting the information, you make it ready for examination, detailing, or any other purpose.
Step 6: Dealing With Error Handling
It is common to face issues of network errors, missing information, or contorted HTML while working with web scraping and parsing HTML. So, it is a must to give attention to error handling and extreme cases so that your script runs easily with no obstacles.
Inspect the status code of the HTTP response to deal with network errors or request issues. Be sure that you handle diverse status codes suitably:
response = requests.get(‘http://example.com’)
if response.status_code == 200:
html_content = response.text
else:
print(f”Error: Unable to fetch page, status code {response.status_code}”)
In some cases, the tags you’re seeking out for might not be present within the HTML. Utilize conditional statements to check in case a component exists before trying to get to its content:
h1_tag = soup.find(‘h1’)
if h1_tag:
print(h1_tag.get_text())
else:
print(“No <h1> tag found.”)
Cover your code in try-except blocks to capture and handle unforeseen blunders like network issues or parsing blunders:
try:
response = requests.get(‘http://example.com’)
response.raise_for_status() # Raise an exception for HTTP errors
soup = BeautifulSoup(response.text, ‘html.parser’)
# Continue with data extraction
except requests.RequestException as e:
print(f”Request failed: {e}”)
except Exception as e:
print(f”An error occurred: {e}”)
At last, by consolidating error handling and addressing severe issues, you make your scraping more active and less inclined to breaking due to unanticipated occurrences.
Conclusion
In sum, parsing HTML using BeautifulSoup is an easy-to-operate process that makes navigating HTML documents attainable even for less experienced people. Moreover, the final output or data you get is free from errors, as BeautifulSoup not only supports data extraction but also enables restructuring the gathered information, making it easily discernable. In addition, BeautifulSoup offers multiple approaches like tag names, attributes, text content etc making data organization more straightforward. Finally, even those with limited programming knowledge and holding the basics of HTML and Python can use BeautifulSoup and achieve successful HTML content parsing.
