
How To Overcome Anti-Scraping Measures With BeautifulSoup
To get access to a tremendous sum of data and useful insights, web scraping has become a fundamental tool in information collection. In any case, this process often coincides with the challenge of overcoming anti-scraping measures executed by websites to defend their information and keep servers in form. These defensive measures, like CAPTCHAs, IP blocking, user-agent filtering, and rate limiting, are scheduled to identify and block automated scraping tools, which can remarkably prevent your scraping actions. BeautifulSoup, an effective Python library used for web scraping, gives a productive solution with various procedures to explore these obstructions viably. You can overcome the challenges of anti-scraping measures by integrating BeautifulSoup with other tools, including proxies, headless browsers, and rotating user agents, with a lowered risk of being detected. For a more obstacle-free web scraping task while overcoming issues like anti-scraping measures, this blog will present steps to be utilized using the BeautifulSoup library.
Step 1: Getting Know-How Of Basic Anti-Scrapping Measure
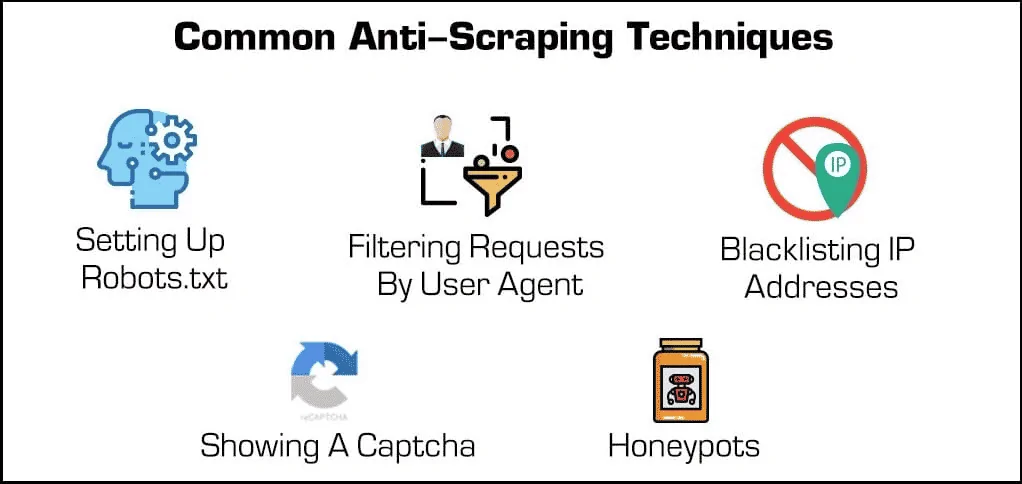
As mentioned, anti-scraping measures are a set of strategies utilized by websites to anticipate unauthorized data extraction. To develop successful scraping techniques, it is important to have adequate knowledge of these measures.
One of the most seen anti-scraping approaches is CAPTCHAs, which ask the users to solve puzzles to verify they’re human. Another one is IP blocking, which limits access relative to IP addresses. Rate-limiting is also a common measure that limits the number of requests users can make in a provided time frame.
Moreover, it is also typical for Websites to utilize JavaScript to load content dynamically in a way that makes it more challenging for simple scraping tools to get to the information straight. Also, sites might utilize advanced detection strategies like analyzing request patterns or utilizing machine learning algorithms to distinguish and block scraping attempts.
Having a thorough understanding of frequently used anti-scraping strategies, you’ll better prepare for the challenges you might face in your scraping trials. It will assist you in actualizing successful countermeasures utilizing BeautifulSoup and other tools, and be sure to have a smoother and more fruitful data extraction process.
Step 2: Installing And Setting Up BeautifulSoup
To initiate scraping with BeautifulSoup, you have to set up your development environment. Download BeautifulSoup and its dependencies. The following pip can be used for that:
pip install beautifulsoup4
pip install requests
BeautifulSoup works simultaneously with a parser to translate HTML or XML data. The most distinctive parser used is lxml, which you’ll install with the code:
pip install lxml
After you’ve downloaded the necessary packages, you’ll be able to commence composing your script. Import the specified libraries and present a request to the webpage you need to scrape utilizing the requests library using:
import requests
from bs4 import BeautifulSoup
url = ‘http://example.com’
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘lxml’)
In this phase, requests.get(url) brings the HTML content of the webpage, and BeautifulSoup(response.text, ‘lxml’) parses the content in the form of a BeautifulSoup object. This object enables you to explore and compile information from the HTML structure proficiently.
Step 3: Detecting And Preventing From CAPTCHAs

CAPTCHAs are a prevalent anti-scraping benchmark that is devised to guarantee that people, instead of bots, make requests. To handle CAPTCHAs viably, you have to identify their existence and utilize procedures to dodge them.
To detect CAPTCHAs, you can use particular HTML components or patterns within the web page’s source code, which frequently arise as pictures or intuitive devices. Utilize BeautifulSoup to examine the page and scan for CAPTCHA-related components, like image sources or iframes.
Some significant approaches you can adopt to bypass CAPTCHAs are:
For basic CAPTCHAs, you might have to unravel them manually. However, it may not be so helpful for large-scale scraping.
Look into utilizing third-party CAPTCHA tackling services such as 2Captcha or Anti-Captcha; they give APIs to solve automated CAPTCHA. These services can be coordinated into your scraping workflow, permitting you to submit CAPTCHA images and get keys programmatically.
In case of more complex CAPTCHAs, utilize headless browsers such as Selenium with BeautifulSoup. These browsers can associated with CAPTCHAs similar to a genuine user, possibly sidestepping them by recreating user activities.
By consolidating these procedures you can address CAPTCHAs successfully and guarantee your scraping chores move smoothly.
Step 4: Dealing With JavaScript-Loaded Data

Numerous trendy sites are utilizing JavaScript to load content powerfully, which can make scraping formidable. As a result, it is often seen that BeautifulSoup alone cannot operate JavaScript, so scrapers have to utilize extra tools or strategies to reach and extract the information. Some possible alternatives are as follows:
Using Headless browsers like Selenium or Playwright can generate JavaScript and communicate with the web page just like a real user would. The following code will help you to utilize Selenium to manage the content containing JavaScript:
from selenium import webdriver
from bs4 import BeautifulSoup
# Set up the Selenium WebDriver
driver = webdriver.Chrome() # or use another browser driver
driver.get(‘http://example.com’)
# Wait for JavaScript to load
driver.implicitly_wait(10) # wait up to 10 seconds
# Extract page source and parse with BeautifulSoup
soup = BeautifulSoup(driver.page_source, ‘lxml’)
# Perform your scraping
data = soup.find_all(‘your_element’)
# Close the browser
driver.quit()
You can also use JavaScript Execution Libraries libraries, like Pyppeteer that can manage JavaScript to scrape assertive content, which refers to the specific data or information you are targeting for extraction. They proffer comparable usefulness to headless browsers.
In some cases, JavaScript-loaded content is gotten from API endpoints. You can Utilize browser developer tools to recognize these endpoints and create direct requests utilizing requests or identical libraries.
Eventually, utilizing these strategies, you’ll be able to approach and extract data from pages that depend on JavaScript to load their content.
Step 5: Employing Proxies To Prevent IP Blocking
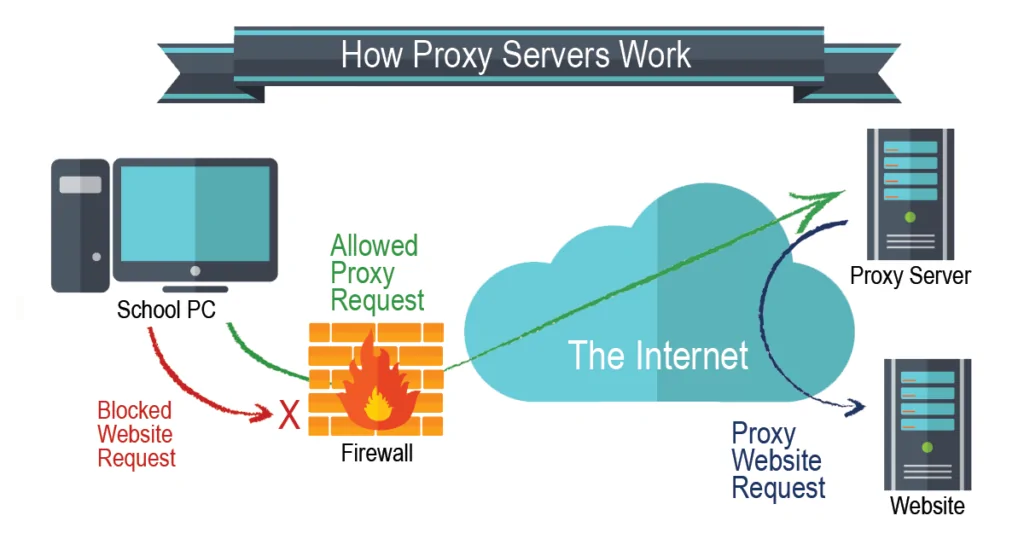
In some cases, websites can block your IP address if they catch anything abnormal or overblown scraping action. For dodging IP blocking, you can utilize proxies that assist you in distributing your requests over numerous IP addresses.
consider purchasing or getting a list of proxies from a trustworthy supplier. Proxies can be residential that are related to genuine user IPs or datacenter that are usually faster but simpler to detect. Different services offer rotating proxy solutions, to alter automatically your IP address intermittently.
Design your scraping script to utilize proxies by giving proxy particulars to the requests library. You can consider this code example:
import requests
from bs4 import BeautifulSoup
# Define proxy settings
proxies = {
‘http’: ‘http://username:password@proxyserver:port’,
‘https’: ‘https://username:password@proxyserver:port’,
}
url = ‘http://example.com’
response = requests.get(url, proxies=proxies)
soup = BeautifulSoup(response.text, ‘lxml’)
# Perform your scraping
data = soup.find_all(‘your_element’)
In the matter of larger-scale scraping, rotate proxies to avoid detection. A few proxy services present APIs to rotate proxies, permitting you to either alter IP addresses with each request or after a specified number of requests.
Frequently monitor your scraping activity and alter proxy utilization as required. Do not make multiple requests in a short time, and confirm that your proxy settings are accurately configured to play down the threat of IP blocking.
With the effective use of proxies, you’ll be able to decrease the chance of IP blocking and keep up reliable access to the data you want.
Step 6: Working On HTTP Headers And User Agents

Overseeing HTTP headers and user-agent strings is basic to make your scraping requests show up authentic, as websites regularly inspect these headers to distinguish bots. You need them set accurately to assist you in bypassing this layer of security.
The foremost critical header is the User-Agent, which implies the server about the type of browser or gadget that is making the request. Libraries like requests utilize a non-specific user agent by default, which eases sites to discern scrapers. You can customize it by mimicking an authentic browser using:
import requests
from bs4 import BeautifulSoup
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64)’,
‘Accept-Language’: ‘en-US,en;q=0.9’,
}
url = ‘http://example.com’
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, ‘lxml’)
Additional headers, such as Referer and Connection, can be incorporated to improve authenticity. Utilize requests.Session() to oversee cookies and uphold session persistence, which supports reduced detection:
session = requests.Session()
session.headers.update(headers)
response = session.get(url)
Step 7: Preventing Rate Limiting Issues
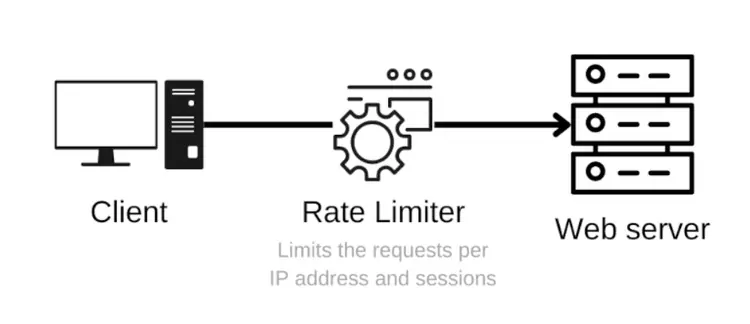
The scraping challenge of Rate limiting is also a big issue, which is a measure websites employ to restrict the number of requests a user can make for a particular period. You can avoid reaching rate limits by executing request throttling with the time.sleep() function to add pauses between requests:
import time
time.sleep(5) # Delay for 5 seconds between requests
In extensive scraping, rotating IPs by employing proxy servers could be a great approach. With rotating proxies, you spread your requests over distinctive IP addresses, reducing the possibilities of hitting rate limitations:
proxies = {
‘http’: ‘http://username:password@proxyserver:port’,
}
response = requests.get(url, proxies=proxies)
Finally, you must also be considerate of rate-limiting headers such as X-RateLimit-Remaining or Retry-After.
These headers can definitely help you effectively adjust the number of requests and bypass bans.
Conclusion
In ending, businesses employ various strategies at their disposal to thrive in this age of intense competition. Web scraping is a must-have tool that they are using to reach this position of power. Yet there are barriers to this vocation as well. Websites use many anti-scraping strategies to prevent users from scraping their content. However, there’s always an alternative route. You can overcome these anti-scraping measures by using the specific strategies which are also highlighted in this blog. Overcoming these hurdles coming in the way of scrapping, you can extract reliable data with smooth scraping.
