How To Extract Images From Text
In various fields, it is common to extract images from text-based documents. It ranges from archiving chronological documents to examining legal contacts and academic files. When you see pictures and PDFs with significant text in them that you wish to extract for later use, the majority of you might type the term or phrase into a notepad or another term document. However, this procedure can take quite some time. Fortunately, an innovative method known as OCR, or optical character recognition, was created to extract text from images. Optical Character Recognition (OCR) application is user-friendly and effective at extracting text from photographs. It helps you in the conversion of scanned documents into readable text form. It is also capable of distinguishing between characters and graphical components, which is essential to spot images in text-containing documents. The programming language used for this purpose is Python, with some other essential libraries, including pytesseract, Pillow, and pdf2image. These libraries help streamline the process of image extraction from diverse file formats, especially PDFs or scanned images. To direct you on using OCR and Python for extracting images from text, the steps are as below:
Step 1: Installing Essential Libraries
Before you begin extracting images from text-based documents, you’ll have to establish your environment by installing the vital Python libraries. These libraries can facilitate Optical Character Recognition (OCR) and image processing, essential details of the extraction process.
Begin by installing pytesseract, an OCR tool that helps identify content inside images. That is often vital for differentiating between text and pictures in checked documents or PDFs. You’ll install it utilizing Python’s package manager pip, utilizing the code:
pip install pytesseract
After that, install the Pillow library, a powerful image manipulation tool that permits you to preprocess images by converting them to grayscale or binary, which enhances the OCR process. To install Pillow library, utilize:
pip install Pillow
If you’re working with PDF documents, you’ll also require pdf2image, which converts PDF pages into pictures so that you can handle them with OCR and determine the section of the picture:
pip install pdf2image
Be sure that you also install Tesseract-OCR on your working framework. For Windows, you need to download the Tesseract installer and include it in your system’s Path. For Linux and macOS, you can install it by means of the terminal utilizing package managers such as apt or brew.
Step 2: Load The Document

After the desired libraries are installed, the next step is to load the document or image from which you need to extract pictures. If the source is a PDF archive, you’ll convert each page into a picture file utilizing the pdf2image library. It is particularly valuable since numerous text documents, including PDFs, are not natively readable by image processing tools and have to be changed into an image format for further management.
To begin, import the vital modules and load the document by using the given code:
from pdf2image import convert_from_path
# Load the PDF document and convert it to images (one image per page)
pages = convert_from_path(‘document.pdf’)
That code transforms each page of the PDF into an image that can, at that point, be processed. The convert_from_path function bears the PDF file path as an argument and yields a list of pictures, one for each page. You’ll moreover indicate the DPI (dots per inch) to handle the resolution of the output images, which can be imperative for OCR precision.
For other formats like images, you’ll be able to directly load them utilizing the Pillow library as given below:
from PIL import Image
# Open the image file
image = Image.open(‘page_image.png’)
After the text source is loaded as images, you are all set to preprocess and interpret them within the next steps.
Step 3: Preprocessing The Image
Preprocessing the image may be a basic step to improve the precision of the OCR process. Raw images or PDF page transformations usually include noise, insufficient contrast, or superfluous subtle elements that can lessen the accuracy of text recognition. By preprocessing the picture, you’ll maximize it for OCR and make the subsequent steps more proficient.
To start, convert the image to grayscale, as this helps decrease noise and makes it simpler for OCR software to differentiate between text and pictures. Utilize the Pillow library to manage this conversion:
from PIL import Image
# Convert image to grayscale
gray_image = image.convert(‘L’)
In this code, the convert(‘L’) strategy transforms the picture into grayscale, where ‘L’ refers to “luminance” or brightness, lessening it to shades of gray. This action streamlines the image for text detection without changing the integrity of the visual components, such as images or graphs.
Besides grayscale conversion, you might also need to apply binarization, which converts the picture into a binary format (black and white). This further improves OCR execution by emphasizing text over background details:
# Apply binarization to further clean the image
binary_image = gray_image.point(lambda x: 0 if x < 128 else 255, ‘1’)
By executing these preprocessing stages, you guarantee the text is simpler to identify, and you decrease unnecessary clamor, which makes it easier to differentiate between the content and pictures within the document. The following step will concentrate on utilizing OCR to extricate the text from the preprocessed image.
Step 4: Extricate The Content
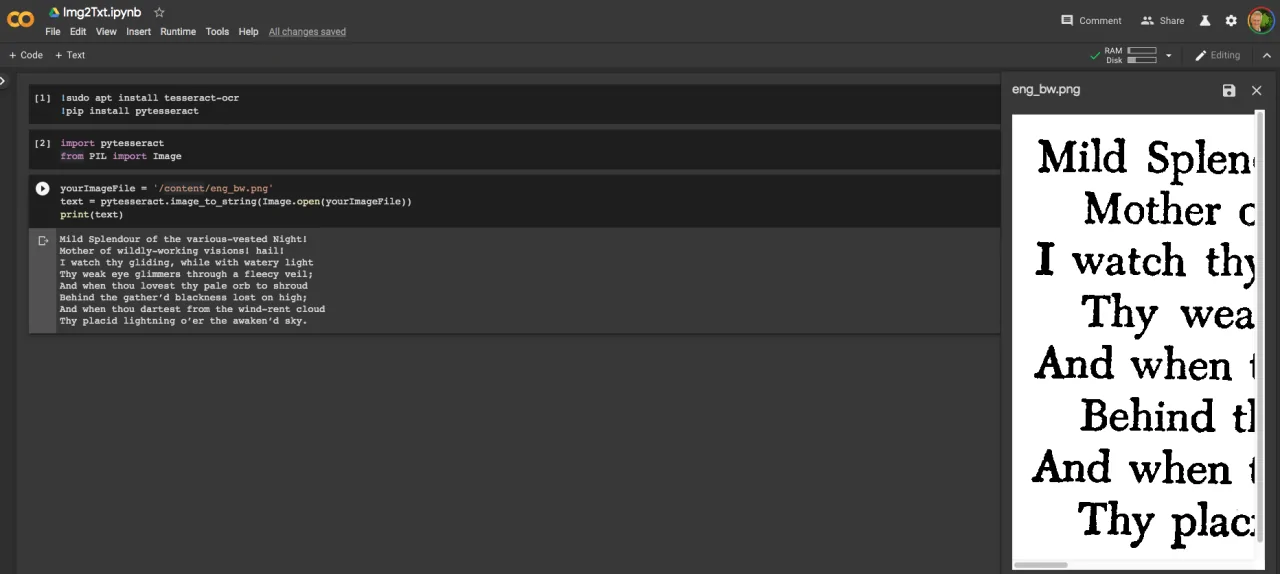
With the image preprocessed, it’s time to extricate the content utilizing Optical Character Recognition (OCR). This can be where pytesseract, a Python wrapper for Google’s Tesseract OCR engine, comes into play. pytesseract studies the preprocessed picture and identifies the text, leaving behind any graphical components, such as images, which you’ll target for extraction later.
Begin by importing pytesseract and running the OCR on the preprocessed image using the following:
import pytesseract
# Extract text from the preprocessed image
extracted_text = pytesseract.image_to_string(binary_image)
The image_to_string function processes the picture and yields the recognized text. It’s vital to keep in mind that OCR isn’t immaculate and works competently when the image is obvious and well-preprocessed because of which grayscale conversion and binarization in Step 3 are significant for progressing precision.
You can also indicate the language for way better acknowledgment in the event that the text is in a non-English language, like:
extracted_text = pytesseract.image_to_string(binary_image, lang=’eng’)
The text output is presently reserved within the extracted_text variable, permitting you to programmatically examine it. Yet, as you’re centering on extracting images, this step helps you isolate textual content from non-text components. Through parsing the results of pytesseract, you can more effectively recognize areas of the document that contain pictures, graphs, or other visual elements.
Step 5: Find The Image Sections
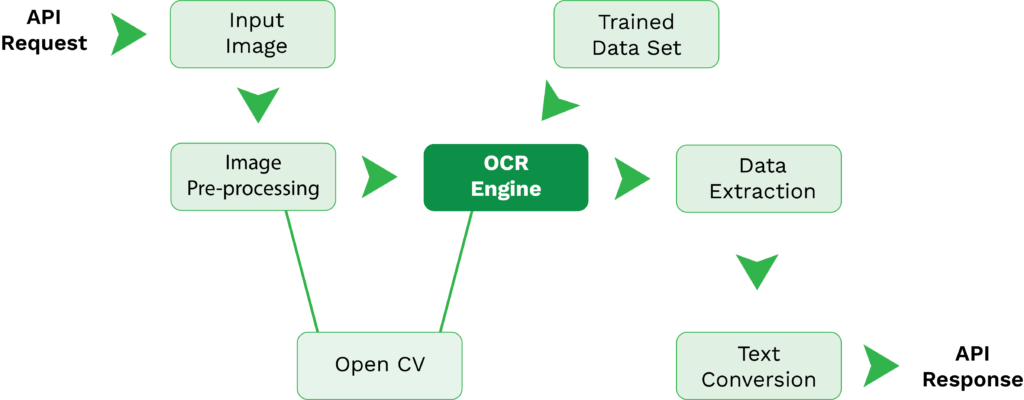
Once you are done with extracting the text utilizing OCR, the following step is to find the image sections in your document. as pytesseract recognizes and extracts only the content, the non-text regions remain. These locales can be distinguished either programmatically or physically, according to the intricacy of the document.
For easy image extraction, particularly in structured documents such as PDFs, you’ll be able to compare the content that was extracted by pytesseract to the whole document. Any regions of the picture that were not caught by OCR are probable to be images or graphics.
For automating this process, you can take benefit of the document layout. Utilize bounding boxes given by pytesseract to catch regions where text is missing. In case there’s a large gap between content blocks or a segment that OCR does not identify, that zone may contain an image.
# Use image_to_boxes to get bounding box info for text regions
boxes = pytesseract.image_to_boxes(binary_image)
# Manually define regions where images might be located
# You can use this information to define non-text regions
In case the layout of the document is more complex, you can also manually specify areas by their position and dimensions. For example, pictures might show up in predefined areas, like in headers, footers, or centered sections, so you can programmatically focus those zones.
This identification stage is critical to isolating non-text components, helping you prepare the image extraction. After the areas containing images are distinguished, you’ll continue to the ultimate step: preserving these extracted images.
Step 6: Saving The Images
The ultimate step is to extract and save those pictures for further use. If you’re working with a PDF, you’ll be able to directly extract pictures from the non-text areas. For scanned documents or other image-based sources, you may need to crop out the identified image regions manually or programmatically.
For image-based documents, you can utilize the Pillow library to edit and save the areas that were recognized as containing pictures. The following example explains how you can do it:
# Crop the region that contains the image
image_section = binary_image.crop((left, top, right, bottom))
# Save the cropped image to a file
image_section.save(‘extracted_image.png’)
Within the crop method (left, top, right, bottom), indicate the coordinates of the region where the image is found. These coordinates can either be decided manually or programmatically based on the OCR results.
For PDFs, in case the pictures are embedded, you’ll extract them directly utilizing libraries such as PyMuPDF, as given below:
import fitz # PyMuPDF
# Open the PDF and extract images
pdf_document = fitz.open(‘document.pdf’)
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
images = page.get_images(full=True)
# Save extracted images
for img_index, img in enumerate(images):
xref = img[0]
base_image = pdf_document.extract_image(xref)
image_bytes = base_image[“image”]
with open(f”image_{page_num}_{img_index}.png”, “wb”) as img_file:
img_file.write(image_bytes)
This strategy extracts the embedded images specifically from PDF pages. After the pictures are saved, you’ll be able to review or utilize them as required.
Conclusion
In closing, extracting photos from a text file can be a helpful and functional operation in a variety of contexts. The ability to extract images from text can save you time and effort, whether you need to use the images for a presentation, make a digital photo book, or just store the images for later use. The approaches described in this blog post are workable and simple ways to extract images from various texts. However, OCR output results are not always as exact as we would want. For this reason, it is highly recommended that you verify the outcome after processing, particularly if the information contains multiple languages or a specific typeface.
