
How To Scrape Infinite Scroll Websites
While extracting web data, users have to encounter various opportunities and challenges simultaneously, which makes the scraping process a fruitful and fussy experience at the same time. One of the significant challenges is to scrape infinite scroll websites. Such websites’ structure offers users ease as the user doesn’t have to click to go to the next page; the content loads at the bottom of the page automatically as they scroll. But this web design, which relies upon JavaScript to fetch data, makes it difficult to use conventional scraping techniques to gather all its data at once. Even if you attempt to scrape an infinite scrolling site with common tools, the data will only be collected for the first segment that is visible. To deal with such websites and attain a smooth scraping process, tools like Playwright and Sleenium are utilized by developers, which can imitate genuine user behavior like scrolling, clicking or waiting and help you access vast dynamic data. This blog will go through a detailed step-by-step process that employs advanced scraping techniques to help users scrap data from an infinite scroll website.
Step 1: Analyzing The Website’s Behavior
Before beginning with the process of scraping an infinite scroll website, it is rudimentary to first understand the way it loads content. Far from conventional pages, infinite scroll websites dynamically get information as the user scrolls, usually utilizing JavaScript to load content in small increases. It makes the content unreachable through typical HTML scrapers.
Start by analyzing the website’s conduct. Unlock the browser’s Developer Tools by pressing F12 or right-clicking on Inspect and heading to the Network tab. Reload the page and begin looking over, giving consideration to the network requests activated as new data loads. Seek for XHR (XMLHttpRequest) or Fetch requests, as these frequently conform to the background information loading process.
Look at the request URLs, query parameters, and responses. By indicating the endpoints that are responsible for fetching new data, you’ll be able to reach the information more straight. That understanding will direct you in recreating the scroll behavior programmatically and permit you to scrape content effectively. Getting insights into how the site loads data is pivotal for choosing the proper tools and procedures for scraping.
Step 2: Inspecting The Network Requests
After you have the essential understanding of how the site loads content, the following step is to examine the network requests that are created during scrolling. Those requests are critical to approach the dynamic information. During your scrolling, the browser will send asynchronous requests, usually XHR or Fetch, to recover additional content. Determining these requests is significant for productively scraping information.
Open the site in your browser and tap on F12 to access Developer Tools. Proceed to the Network tab and be sure that it is recording activity. As you scroll, watch the network requests that show up, particularly focusing on those marked as XHR or Fetch. These are generally utilized to load fresh content without refreshing the page.
Search for patterns within the request URLs, such as query parameters that alter with each scroll. Usually, the data is returned in JSON or XML format, which is more effortless to parse than HTML. After you are done with identifying the API endpoint, you can compose code to connect with these requests specifically and recover the data without requiring to simulate scrolling. For instance, utilizing Python’s requests library, see the given example:
import requests
url = ‘https://example.com/api/data’
params = {‘page’: 2, ‘limit’: 50}
response = requests.get(url, params=params)
data = response.json()
The above approach permits you to bypass the requirement for browser automation and specifically reach the information.
Step 3: Founding An Appropriate Scraping Environment
Scraping data from an infinite scroll site mandates setting up an appropriate scraping environment. It includes the installation of the fundamental libraries and automation tools for the scrolling process and effective data extraction.
Begin by selecting a scraping tool. Selenium and Playwright are prevalent options to scrape dynamic websites as they permit you to oversee a browser and mimic user interactions such as scrolling. Look into the following example to install these libraries, utilizing Python’s package manager, pip:
pip install selenium
Or for Playwright:
pip install playwright
After that, you will require a web driver for Selenium. For instance, to utilize Chrome with Selenium, download the suitable adaptation of ChromeDriver from here and confirm that it is open from your system’s Path.
Once the tools are installed, import the vital libraries in your script. Look into the following representation:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
It will establish your environment to start automating browser actions. As you have Selenium or Playwright in place, you can now control the browser for simulating scrolling, holding up for new data to load, and scraping the content programmatically. That environment will permit you to oversee interactions with the site and extract the information consistently.
Step 4: Simulating The User’s Scrolling Behavior

The fourth step of scraping data from an infinite scroll site involves simulating the user’s scrolling behavior to start the dynamic loading of content. That is where automation tools such as Selenium or Playwright offer convenience. These tools permit you to automate browser activities, like scrolling, to load new data without needing manual intervention.
With Selenium, you’ll be able to simulate scrolling by utilizing JavaScript to scroll the webpage down progressively. The following example shows how you will execute it in your script:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get(“https://example.com”) # Replace with the target URL
# Scroll down until the end of the page
while True:
driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”) # Scroll down
time.sleep(2) # Wait for new data to load
# Optional: Add a condition to stop after loading a specific amount of data or reaching the bottom
The above code can persistently scroll the page till the end, loading additional content as it proceeds. The time.sleep(2) line confirms that there is sufficient time for the new content to load before the following scroll activity happens.
Using Playwright, the method is similar:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(“https://example.com”) # Replace with the target URL
while True:
page.mouse.wheel(0, 1000) # Scroll down
time.sleep(2) # Wait for content to load
The above code will simulate a mouse scroll activity and wait for new information to come into view. With automation of the scroll behavior, you can guarantee that you grab all the information that gets loaded dynamically while you scrape.
Step 5: Data Extraction And Storage

After simulating scrolling and loading additional content on the infinite scroll site, the following step is to extricate and store the information. At this phase, the content will be displayed within the page source or the response from the network request, based on the strategy you utilized to load it. You will utilize libraries such as BeautifulSoup to parse HTML or JSON to structured data to extract and save the pertinent data.
The data extraction utilizing BeautifulSoup is as follows:
If you are scraping HTML content with Selenium, you’ll extract the page source and parse it with BeautifulSoup to find and organize the information like this.
from bs4 import BeautifulSoup
import csv
# Get the page source after scrolling
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
# Extract the desired data
items = soup.find_all(‘div’, class_=’data-class’) # Replace with appropriate class or element
# Store data in a CSV file
with open(‘scraped_data.csv’, ‘w’, newline=”, encoding=’utf-8′) as file:
writer = csv.writer(file)
writer.writerow([‘Title’, ‘URL’]) # Write the headers
for item in items:
title = item.find(‘h2’).text # Extract the title
url = item.find(‘a’)[‘href’] # Extract the URL
writer.writerow([title, url]) # Write the data
Data extraction via API Responses:
If you are scraping structured data like JSON from network requests, you’ll directly connect with the API and save the results in a structured format, including JSON or CSV.
import requests
import json
# Make a request to the API endpoint (URL and parameters may vary)
url = ‘https://example.com/api/data’
params = {‘page’: 2, ‘limit’: 50}
response = requests.get(url, params=params)
# Assuming the response is in JSON format
data = response.json()
# Save the data to a JSON file
with open(‘data.json’, ‘w’, encoding=’utf-8′) as file:
json.dump(data, file, indent=4)
# Optionally, store the data in a CSV
import csv
with open(‘data.csv’, ‘w’, newline=”, encoding=’utf-8′) as file:
writer = csv.writer(file)
writer.writerow(data[0].keys()) # Write header row from JSON keys
for item in data:
writer.writerow(item.values()) # Write rows of values
In both of the above cases, you must be sure that the data is parsed accurately, particularly when you have to deal with nested structures like in JSON responses. As you store the scraped data in CSV or JSON formats, you make it simple to process and examine the results afterward. This step also incorporates the option to store information in a database for more vast projects.
Step 6: Error Handling And Performance Optimization
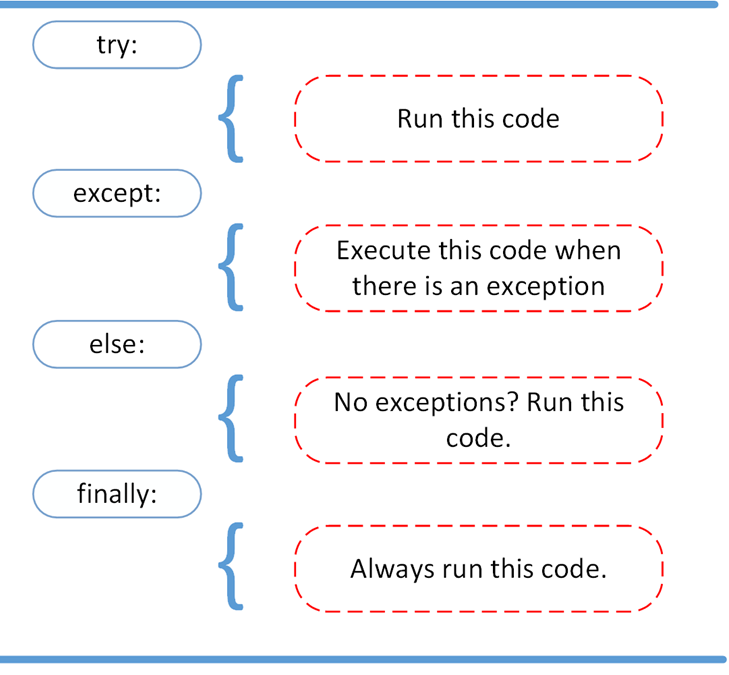
In the process of scraping infinite scroll websites, dealing with errors and optimizing execution is pivotal for reliable and proficient scraping. Web scraping frequently includes going through inconsistent network conditions, waits in loading, and periodic page structure shifts. Executing error handling guarantees that your script does not break halfway.
Employ try-except blocks to capture potential abnormalities like timeouts or missing components:
try:
driver.get(‘https://example.com’)
except Exception as e:
print(f”Error: {e}”)
In case your script is sluggish, you can optimize it by altering the time delay between scroll actions or utilizing explicit waits in Selenium to wait for particular components before continuing. It reduces pointless delays and makes the method faster.
Also, consider including logic to stop scraping once sufficient data is gathered or if the page has no more content to load. For instance, in case no new information is discovered after a scroll, exit the loop this way:
if len(new_data) == 0:
break # No new content, exit the loop\
Finally, all the above measures will progress the reliability, speed, and proficiency of your scraping operation.
Conclusion
In conclusion, understanding the target website’s structure and utilizing appropriate techniques to get beyond anti-scraping measures are essential for successful web scraping. Additionally, dealing with dynamic web pages with an infinite scroll or Load more function can make your scraping project twice as difficult. One of the best ways to scrape sites of this kind can be by simulating human behavior with particular tools, such as Selenium or Playwright. Similarly, the steps addressed in this blog can provide you valuable insights to go through the painstaking scrapping tasks involving infinite scroll sites with ease.
