How To Use XPath For Data Extraction
XPath or XML Path Language is a potent tool that helps to navigate and extract data from structured documents like XML and HTML. It offers a flexible way to query specific elements or attributes inside the tree structure of a document. All such attributes of XPath make it inevitable for tasks including web scraping, automated testing, and data transformation. With the definition of precise paths, this tool authorizes the users with efficient data identification and retrieval to deal with both complex as well as nested structures. That ability of XPath is quite useful for contexts like extraction of target information, such as if a user wants to extract goods prices from e-commerce pages or wants to get headlines from different websites; all such tasks become effortless. An XPath tool works by traversing nodes in a document using path-like syntax comparable to navigating a file system. That syntax involves myriad selectors and functions for elements’ identification according to their names, attributes and so on. This blog will move on with the step-by-step process of using XPath for data extraction.
Step 1: Understanding The Structure Of The HTML Or XML Document
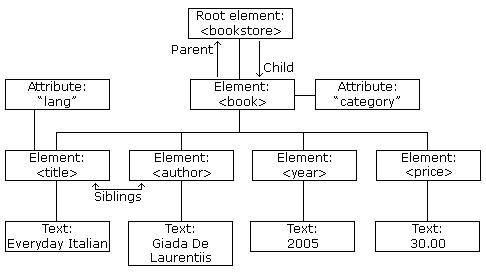
Before we beging with the process of utilizing XPath for data extrcation, it is necessary to understand the structure of the HTML or XML document you are dealing with. Both HTML and XML have a hierarchical character comprising nested elements or nodes organized in a tree structure. Each component can have different qualities and text content. Comprehending this structure will assist you in writing precise XPath expressions to target the information you would like.
To start, review the document’s source code. In web scraping, you can do that by right-clicking on a webpage and choosing Inspect or View Source. That action permits you to investigate the HTML structure and recognize key components such as <div>, <span>, <a>, and others and their linkages with one another.
After that, acquaint yourself with the essential XPath concepts, such as nodes, attributes, and relationships between components. For instance, learning how to get to a parent, child, or sibling element is fundamental. By understanding the layout and relationships of the information within the document, you will be able to form more exact XPath queries that retrieve the specified data proficiently.
Step 2: Determining The Target Elements
The second step in utilizing XPath for data extraction is to determine the particular components you need to extract from the document. It needs to closely analyze the HTML or XML structure and highlight the pertinent tags, attributes, or text content that keeps the information you need.
Begin by finding the component that includes the required data. For instance, on the off chance that you need to scrape the cost of a product from an e-commerce website, you might have to locate the <span> or <div> element that carries the price. Seek for unique identifiers like class, id, or other attributes that can indicate the component from others. If the component has a distinct class or ID, it can make your XPath query more accurate and productive.
In some cases, elements might not have unique identifiers, but their location inside the document’s structure can still help you distinguish them. For example, you could target the first <h1> heading on a page or choose a list item according to its placement in a list. Specifying these components precisely is significant to creating XPath queries that will return the proper data.
Step 3: Writing The Suitable XPath Expressions
Once done with the target elements identification, the following stage is to write the suitable XPath expressions to find and extract the information. XPath expressions utilize a path language structure that indicates how to explore through the hierarchical design of the document.
A fundamental XPath expression begins with a forward slash (/), suggesting the root node. For instance, to choose all <div> elements, the expression could be /div. To target a particular tag with a special attribute, like a product cost in a <span> with a class of “price,” you’ll utilize the XPath:
//span[@class=’price’]
Also, XPath expressions can incorporate conditions to filter components. For instance, to discover the first <p> tag within a distinctive <div> with an ID of “content,” the expression should be:
//div[@id=’content’]/p[1]
You can also go through relationships among elements. To choose the child of an element, use /, and for siblings, utilize the following-sibling axis. Incorporating these highlights permits you to create exceedingly specific XPath queries that extract information efficiently. Practice is key to grasping XPath syntax for different contexts.
Step 4: Setting Up An Extraction Tool Or Library
In the fourth step of the process of using XPath for data extraction, you are required to set up an extraction tool or library that features XPath queries support. Prevalent libraries incorporate Python’s lxml, BeautifulSoup, and Selenium, each presenting diverse functionalities for web scraping and data extraction.
For instance, in case you’re utilizing Python with lxml, install the library utilizing the below-mentioned command:
pip install lxml
After installation, you’ll utilize it to parse HTML/XML documents and execute XPath queries. Below is a basic Python code snippet that illustrates the way of setting up lxml for XPath extraction:
from lxml import html
import requests
# Get the webpage content
url = ‘https://example.com’
response = requests.get(url)
# Parse the HTML content
tree = html.fromstring(response.content)
# Use XPath to extract data
result = tree.xpath(‘//span[@class=”price”]/text()’)
# Print the extracted data
print(result)
The above code will fetch a webpage, parse it with lxml, and run an XPath query to extract the content of elements with the class “price.” Additionally, options like Selenium can be utilized for dynamic pages where content is loaded by means of JavaScript. Installation of these tools is basic for applying XPath successfully in real-world data extraction projects.
Step 5: Using The XPath Expressions To Extract The Information
After you have your extraction tool or library in place, the following phase is to use the XPath expressions to extract the information you desire. It includes operating the XPath queries inside your tool, which can search through the HTML or XML document and yield the targeted elements or values.
For example, in case you are utilizing Python with lxml, you’ll apply the XPath expression directly to the parsed document to extract particular information. The following is an illustration to indicate the extraction of an item cost from a webpage:
from lxml import html
import requests
# Fetch the webpage content
url = ‘https://example.com’
response = requests.get(url)
# Parse the HTML content
tree = html.fromstring(response.content)
# Apply the XPath expression to extract the product price
price = tree.xpath(‘//span[@class=”price”]/text()’)
# Print the extracted price
print(price)
In the above case, the XPath query //span[@class=”price”]/text() searches for all <span> elements having the class “price” and retrieves their text substance, which could be the price. You can polish your XPath expressions per the complexity of the information or the document’s design.
While dealing with dynamic content or JavaScript-rendered pages, you might utilize Selenium to communicate with the page before extracting information. By applying XPath accurately, you can be guaranteed that the extraction process is both precise and productive.
Step 6: Refining The Results
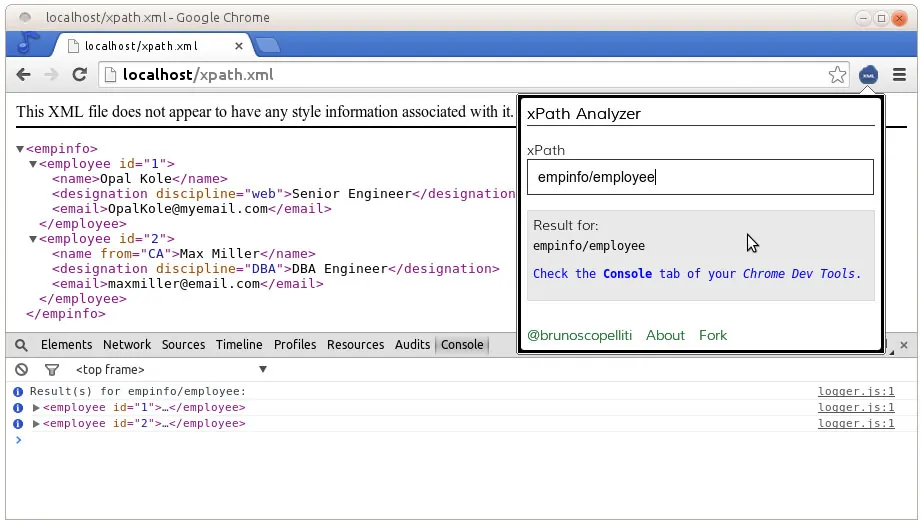
After XPath expressions application and data extraction, the ultimate step is to approve and refine the results. That can be crucial since XPath queries can occasionally return irrelevant or inadequate information if the expressions are not accurate or in case the structure of the document varies. The following phases can ensure the quality of your extraction:
Review the Results:
Audit the data you have extracted to guarantee it fits the expected format. In case you are extracting costs, confirm that the results are in numbers and not empty strings or inaccurate values.
Regulate Missing Information:
If your XPath query yields empty or null outcomes for certain objects, you might have to polish the XPath expression or account for missing information. You’ll be able to handle missing elements with conditions such as if statements or utilize default values when needed.
Regulate the XPath:
As per the results, you may have to adjust your XPath queries to be more precise. For instance, you may find that the class or ID attributes of elements need to be adjusted or that sibling or parent nodes ought to be utilized for more exact targeting.
Experiment on Multiple Pages:
If you are scraping various pages or a large dataset, try the XPath expressions on diverse pages to confirm consistency over the whole dataset. Web structures may vary somewhat over pages, so minor alterations might be vital.
Conclusion
To conclude, XPath allows users to extract data not just from page layout but also from the structure of documents, such as the contents of text elements. Thus, XPath might be your savior if you are web scraping and facing a website that is challenging to scrape. With the help of XPath Queries, a potent web scraping tool, you can quickly traverse and pick particular web page elements. It is crucial to understand the fundamental syntax and features of XPaths and to use certain adequate practices and tips to polish the overall scraping results.
