
How To Collect Big Data Sets Using A Web Scraper?
There are countless resources available on the online platform to acquire the required sets of data for your business incentives and projects. It is always a better idea to extract information that is constantly shape-shifting in the current scenario. Just say, COVID-19, for instance, the statistics related to the virus are changing daily. The number of cases, number of tests being performed, those who have closed their cases, so on and so forth!
The information regarding the virus is updated regularly, so if you are as I am interested in this information you can extract it and make your dataset. In this mission, your tools are going to be basic Python Libraries, Numpy, Pandas, and Beautiful Soup. In this blog, we are going to scrape the entire COVID-19 related data into my dataset.

Before diving in, you must have a good idea about what web scraping is and what it does. Web scraping is the procedure of extraction and collection of information from multiple web pages. This information can be utilized for several personal and professional reasons. Web Scraping is the most commonly employed practice within data science and e-commerce these days. All data industries are in dept to web scraping technology for its marvelous big data achievements.
A larger amount of data can be collected manually but ultimately with the same amount of time and effort is involved in this traditional schematic approach. This is quite intensive when you need to collect daily. Imagine it yourself!
To minimize workload and stress, web scraping is going to be our tool for the day. As it is always a wise decision to conform to technological use and prepare a script, which can extract data from web pages automatically and also store it in our usable format.
All you require is a ‘Python Package’, which can parse HTML data from dozens of websites and arrange the data in a tabular format, and also function in data cleaning. There are various packages which are available for this kind of job. In this blog let us continue with Beautiful Soup.
Beautiful Soup
It is a well-known Python Library that allows the scraping of all web content from web pages. Let us consider that there is a web page that we need to scrape data from as it is rich in updated and interesting content. However, there is no way to download the data by direct means. In this case, Beautiful Soup provides a significant set of tools that help to provide easy access to the web page data and specifically locates the content hidden inside the HTML structure.
Let us begin with the process of data extraction and the creation of our dataset.
Step 1: Install the required Packages
For the action, you need ‘requests package’ which will enable you to send HTTP requests via Python. If you have it pre-installed, you will only need to import it. Otherwise, you can install it readily via a pip installer.
pip install requests
pip install beautifulsoup4
In this blog, we are using a Python HTML parser. It is already built-in Python and helps transform the input text data which is extracted from the website into a parse tree. This data can be further processed to result in the target data.
After you install the package, you need to import it to your script.
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
Step 2: Beautiful Soup Constructor
Beautiful Soup constructor takes in only 2 input arguments. These are mentioned as following:
String: It is a markup that we want to parse. The markup is attained via the get () method of Python requests. This get method () returns the requests.Response () object. Hence, it continues to the server response to the HTTP request. Also, the text method of the response object attains the content. This serves as the first argument of the Beautiful Soup constructor.
Parser: It is the method with which we parse the markup. You can expect to provide the name of the parser.
website_url=requests.get(website).text
soup = BeautifulSoup(website_url,’html.parser’)
This is all you need, a simple three-liner code to extract all content from the target web page in your dataset.
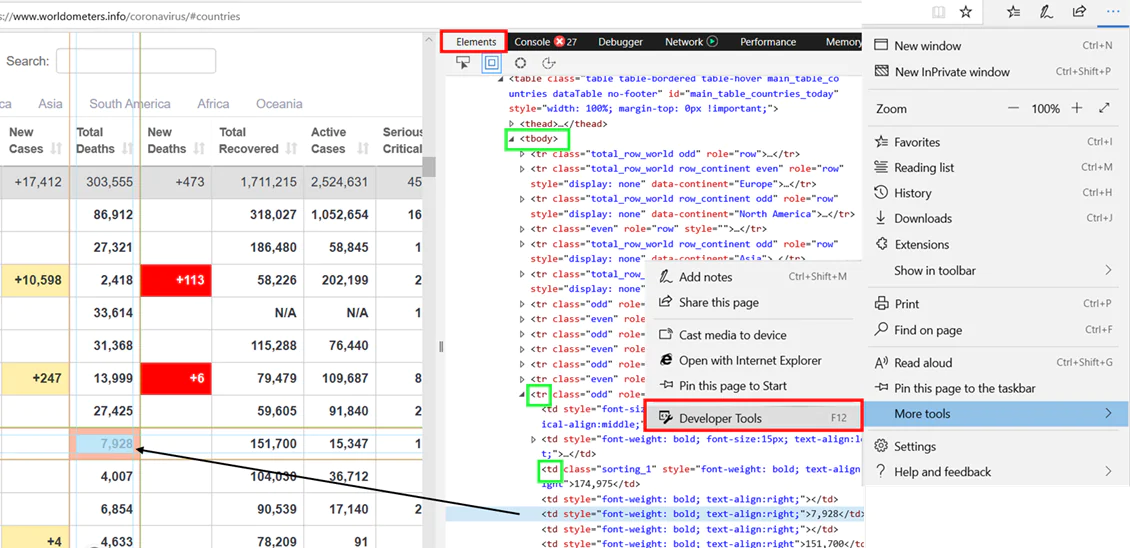
Step 3: Pandas Data Frame
To make a Pandas Data Frame, all you need is to transform the text content in object soup into a tabular format. As you can see in image 1 (as reference) 3 green rectangles are marked. The following terms are needed to be found in soup:
<tbody> : It specifies the content table on given web page.
<tr> : It points out specific rows within the table.
<td> : It points out the particular peculiar cells in the row.
In the Python Script, you will employ methods of object soup that help find the above-mentioned terms in the text which is parsed.
my_table = soup.find(‘tbody’)
variable my_table will consist of the table which is on the web page but still is in HTML format. It should consist of two significant terms such as <tr> and <td>
This points out the individual cells and rows, in the below-mentioned code, we can transform the my_table into an actual table containing values and columns.
table_data = []for row in my_table.findAll(‘tr’):
row_data = [] for cell in row.findAll(‘td’):
row_data.append(cell.text) if(len(row_data) > 0):
data_item = {“Country”: row_data[0],
“TotalCases”: row_data[1],
“NewCases”: row_data[2],
“TotalDeaths”: row_data[3],
“NewDeaths”: row_data[4],
“TotalRecovered”: row_data[5],
“ActiveCases”: row_data[6],
“CriticalCases”: row_data[7],
“Totcase1M”: row_data[8],
“Totdeath1M”: row_data[9],
“TotalTests”: row_data[10],
“Tottest1M”: row_data[11],
}
table_data.append(data_item)
Now you can get table_data in the format of values and columns. The table can now be upgraded into Pandas Data Frame df.
df = pd.DataFrame(table_data)
Note that all columns are in the form of object type within the Data Frame. There are several unwanted characters within these objects just like /, \n, |, +
All the used data is run through the cleaning processes for getting rid of all nonsensical variants. Such a large collection of data can be used in assessments, transformation, and cleaning incentives. This is more commonly termed as the Data Wrangling Process.
Step 4: Export to Excel
The transformed and cleaned data frame can also be exported to an excel sheet via pandas.
df.to_excel(‘Covid19_data.xlsx’, index=True)
Concluding the whole narrative, we have successfully created our own COVID-19 Data Set. You can create multiple data sets by scraping various websites or web pages and combine them all into one data set.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
