How To Do Data Analysis
The process of data analysis lets you unlock useful insights and help in decision making while examining data systematically. The process starts with accessing various sources for data collection, and the significant sources include web scraping, databases and different surveys. After the data collection is done, you need to do some cleaning and reorganization while removing errors and attending to missing values. The essence of data analysis involves the exploitation and restructuring of specific data to find patterns and relations. As a result, raw data is turned into a meaningful one, which is quite worthwhile for both individuals and organizations to make informed choices. Data analysis tools that operate the whole process encompass from a spreadsheet application such as Excel to advanced programming languages like Python and R. Moreover, some visualization tools like Power BI and Tableau also play their role by providing graphical forms of data to simplify intricate data analysis. This blog will go through the steps to do data analysis, from basic data extraction phases to modelling and communication.
Step 1: Extraction Of Data
The beginning step of data analysis is the extraction of data from relevant sources, which seems as easy as copying something, but it requires attention to detail. On the other hand, Inaccurately collated data may appear incomplete, which also affects the quality of analysis. Different sources to access data extraction include APIs, databases, websites, or even local files like Excel spreadsheets. Different methods for data gathering according to the nature of sources are as follows:
To extract data from different websites, Web scrapping is ideal, which uses programming languages like Python. To fetch and parse website content automatically, libraries like Requests and BeautifulSoup are used.
To extract data from databases the common method is SQL. SQL queries are facilitated by the SQLite3 library of Python with your code to access specific data sheets.
To get data from APIs, Python’s Requests library is utilized, which sends HTTP requests and gets data, often in JSON format.
Coding Aspect:
# Import necessary libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
import sqlite3
# — Web Scraping —
def web_scraping(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, ‘html.parser’)
return [item.text for item in soup.find_all(‘div’, class_=’data-class’)]
# — Database Queries —
def query_database(db_file, query):
conn = sqlite3.connect(db_file)
data = pd.read_sql_query(query, conn)
conn.close()
return data
# — API Requests —
def fetch_api_data(api_url):
return requests.get(api_url).json()
# — Reading Files —
def read_file(file_path):
return pd.read_csv(file_path) if file_path.endswith(‘.csv’) else pd.read_excel(file_path)
Step 2: Cleaning Of Data
After data extraction, the next step involves data claeaning, which helps in making the extracted data assembled for analysis. In the cleaning process, correction of errors, dealing with misisng values, removal of duplicates and formatting are covered. Cleaning data ensures that data is in proper form, aiding in a well-organized analysis process.
As data is gathered from various sources likely to contain some inconsistencies and other flaws, cleaning it dismisses all these errors and even deals with missing data so that final results are unstrained.
To deal with missing values, Python’s Pandas library is often used, which helps in filling unavailable values with others, or you can also delete columns or rows containing that missing values.
To avoid any sort of distortion in analysis, it is critical to eliminate duplicates. To help in dealing with such data, Pandas can help in identifying and removing such redundant values.
Different statistical techniques and visualization tools are also employed to handle Outliers, which often distort your final results.
Coding Aspect:
import pandas as pd
def handle_missing_values(df):
return df.fillna(df.mean())
def remove_duplicates(df):
return df.drop_duplicates()
def correct_data_types(df):
df[‘date_column’] = pd.to_datetime(df[‘date_column’])
return df
def handle_outliers(df, col):
Q1, Q3 = df[col].quantile(0.25), df[col].quantile(0.75)
return df[~((df[col] < Q1 – 1.5 * (Q3 – Q1)) | (df[col] > Q3 + 1.5 * (Q3 – Q1)))]
Step 3: Exploration Of Data
Once data cleaning is up to mark, you have to move on to the data exploration phase, in which you have to be more deeply involved in your extracted data by recognizing its patterns, relationships and various other characteristics. It begins with summing up the data set, then identifying trends and finally visualizing data to make less evident insights thoroughly obvious. This phase is beginning to deepen data analysis as you have structured data with coherent content inside.
In data exploitation, you typically have to create descriptive statistics and visualizations and perform initiatory investigations about data distributions and correlations.
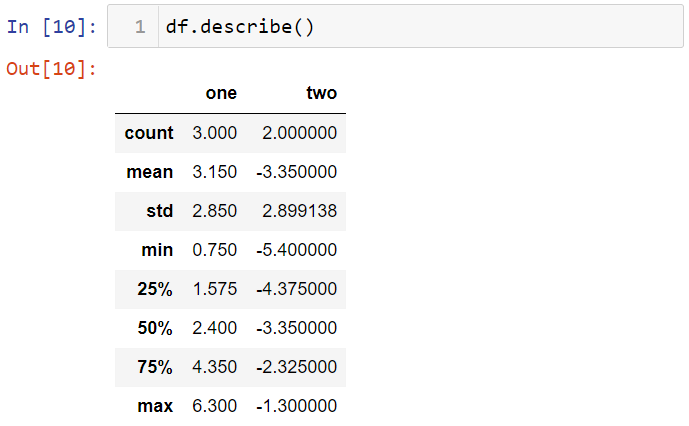
To generate descriptive statistics of your dataset, you can get the help of the Pandas library of Python, which includes median, mean, standard deviation, etc.
In data visualization, libraries such as Matplotlib and Seaborn can provide graphs and plots to enhance data distribution and relationship understanding.
For analyzing the corelations of various variables, Pandas libraries can help with correlation matrices.
Moreover, Pandas libraries also help in data grouping and aggregation via various specific functions, and they disclose essential patterns and trends.
Coding Aspect:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def descriptive_statistics(df):
return df.describe()
def plot_histogram(df, col):
df[col].plot(kind=’hist’)
plt.show()
def plot_scatter(df, x_col, y_col):
sns.scatterplot(x=df[x_col], y=df[y_col])
plt.show()
def correlation_matrix(df):
return df.corr()
def aggregate_data(df, group_col, agg_col):
return df.groupby(group_col)[agg_col].mean()
Step 4: Modelling of Data
The fourth step of data analysis is the modelling of explored data with the help of statistical or machine learning models, which can unlock patterns and make predictions on hypotheses generated previously. It is crucial to pick an appropriate data modelling approach in this step. The data set is used to train models, and also those models’ performance is evaluated to ensure their compatibility with the insights they provide.
As a result, effective data modelling can create models which can turn exploratory data into meaningful and usable ones.
To begin data handling via modelling, choose a proper framework like Python’s Scikit-learn library, which poses a number of algorithms like regression, clustering, classification, etc., so you can apply and evaluate different models.
The model’s performance must be tuned enough for which hyperparameters are to be tuned, and tools such as GridSearchCV can help with getting the most suitable parameters.
To further increase the model’s potency, the k-fold technique is used for cross-validation.
Once the model is trained, it’s time to assess its performance, which is done with metrics. To check classification problems, metrics like accuracy, precision, recall, and F1 score are helpful. Likewise, a mean squared error metric is used to evaluate for regression problems, if any.
Coding Aspect:
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
def apply_linear_regression(df, features, target):
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2)
model = LinearRegression().fit(X_train, y_train)
return model, mean_squared_error(y_test, model.predict(X_test))
def apply_svr(df, features, target):
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2)
model = SVR().fit(X_train, y_train)
return model, model.predict(X_test)
def tune_hyperparameters(df, features, target):
return GridSearchCV(SVR(), {‘kernel’: [‘linear’, ‘rbf’], ‘C’: [1, 10]}).fit(df[features], df[target]).best_params_
def perform_cross_validation(df, features, target):
return cross_val_score(LinearRegression(), df[features], df[target], cv=5).mean()
Step 5: Interpretation Of Data
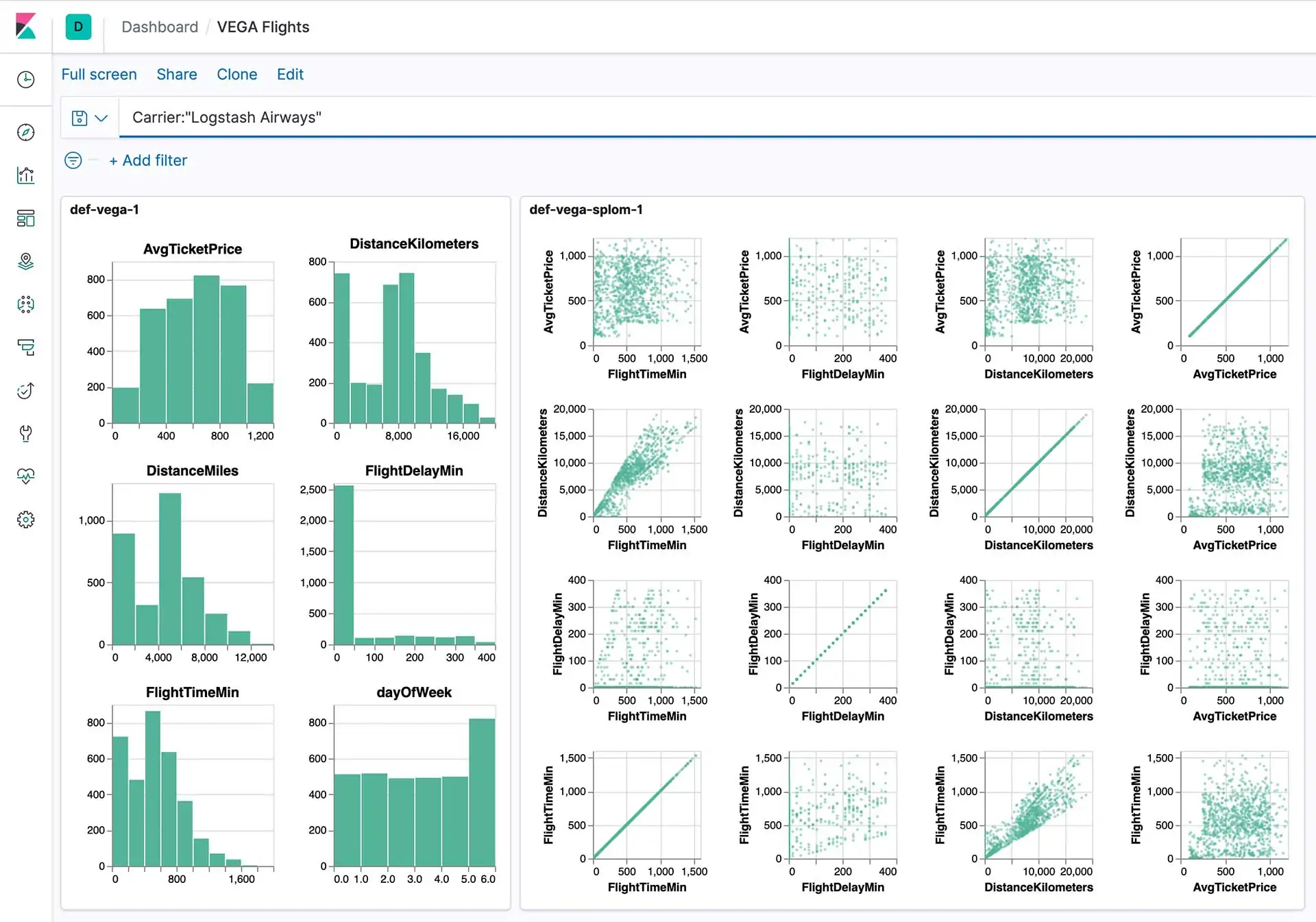
The last step of data analysis is interpreting the modelled or structured data to further refine it enough to be easily understandable and actionable. This step includes comprehending what the model results suggest within the setting of the initial problem or research question. It moreover incorporates communicating discoveries successfully to decision-makers.
The data interpreting phase, as the ultimate step of the data analysis process, does not only include a conscientious understanding of results, but it is also meant to apply results to real-world situations. The model’s results are compared with the businesses or research goals to enhance decision-making or strategy design.
To present outputs and results more vividly, visualization tools, including Matplotlib or Seaborn, are used, which make the model’s results clear and visible.
To see through the model’s performance, metrics are utilized including interpreting metrics of accuracy, precision, recall, and confusion metrics for detecting areas of improvement.
To sum up the final outcomes, codes are used which further simplify the process through aggregation and identification of key trends.
At last, reports are created reports with Dash or Jupyter Notebooks libraries. These libraries help you to demonstrate the analysis results and insights to stakeholders more effectively.
Coding Aspect:
import pandas as pd
import matplotlib.pyplot as plt
def generate_report(df):
return df.describe()
def plot_bar_chart(df, x_col, y_col):
df.groupby(x_col)[y_col].sum().plot(kind=’bar’)
plt.show()
def plot_pie_chart(df, col):
df[col].value_counts().plot(kind=’pie’)
plt.show()
def save_to_excel(df, file_name):
df.to_excel(file_name, index=False)
Conclusion
In conclusion, data analysis is a promising approach for assessing raw data and drawing insights regarding data. It can benefit both individual and business researchers in getting avenues to performing better, maximizing profit or making more strategically sound decisions. This potential for growth and success is particularly crucial since it helps them operate better. By finding more effective ways to do business, firms can contribute to cost reduction by incorporating it into their business strategy. Data analysis can process data and compile information using a variety of analytical procedures and techniques, which makes it possible to cover a variety of data regardless of the complexity level.
