How To Automate Data Mining Processes With KNIME
Data mining is a mighty process that can extract useful data from vast data sheets, and with added automation, it runs more smoothly. Konstanz Information Miner, or KNIME, an open-source data analytics tool, can enable users to go through an effortless data mining task. KNIME has a vast library with pre-built nodes and a user-friendly interface, which facilitates data analysts and scientists in the automation of repetitive tasks, workflow streamlining, and practical insight derivation. Your data mining automation, when integrated with KNIME, becomes time-saving with minimal human error chances and maximum accuracy. With the help of KNIME’s Visual Programming Environment, users without needing any complex coding, can generate intricate workflows. KNIME’s user ease makes it approachable for a range of users, from rookies to adept analysts. Additionally, this platform can support various kinds of data sources, such as databases, cloud services, and CSV files, which helps in incorporating numerous data types. This blog will further proceed with the steps essential for automating data mining processes with KNIME, enhancing the productivity of your mining projects.
Step 1: Gathering And Importing Information From Different Sources
The initial step in automating data mining with KNIME involves effectively gathering and importing information from different sources. KNIME presents an assortment of nodes custom-made for this purpose, like CSV Reader, Excel Reader, and Database Connector, permitting clients to effortlessly ingest information from files, spreadsheets, or social databases. With the help of these nodes, you can design how data is read, containing specifying delimiters, header rows, and information types.
To improve automation, consider utilizing the KNIME Scheduler to execute workflows at predefined intervals, guaranteeing that the most recent information is continuously accessible for examination. Also, the utilization of the File Watcher node can consequently initiate a workflow when new information files are identified in indicated registries. This approach dispenses with manual input and permits for a more dynamic and responsive information collection phase.
By establishing proficient data input mechanisms, you make a strong foundation for the consequent steps within the data mining workflow. It guarantees that your examinations are continuously based on the most current and significant data, which is crucial for creating precise insights and making educated choices.
Step 2: Preprocessing And Cleaning The Information
After the data collection, the following pivotal step in automating data mining processes with KNIME is preprocessing and cleaning the information. Crude data frequently includes irregularities, lost values, and unessential data, which can hinder examination and lead to inaccurate results. KNIME gives a vigorous set of nodes to foster this cleaning process.
Begin by utilizing the Missing Value node to recognize and handle gaps within the data. That node permits you to fill in missing values utilizing different techniques, like mean, median, or mode, or even to remove rows or columns that include excessive lost data. After that, employ the String Manipulation and Date&Time nodes to formalize data designs, securing consistency over your dataset.
Furthermore, utilize the Duplicate Row Filter node to expel any repetitive entries that might skew your results. To encourage streamlined preprocessing, consider implementing workflow loops, which permit you to apply the same cleaning processes over numerous datasets automatically.
By contributing time to data preprocessing and cleaning, you establish the stage for more precise analysis and model training, eventually progressing the quality of insights inferred from your information mining efforts. This stage is fundamental for confirming the integrity and reliability of your discoveries.
Step 3: Engineer Data Features
![]()
Once your data is preprocessed and cleaned, next you need to engineer features. This process includes assembling new features or adjusting existing ones to progress the execution of your machine learning models. Compelling feature designing can altogether improve model precision and empower better experiences.
Start by utilizing the Math Formula node to create new features according to mathematical operations applied to existing columns. Suppose you may create ratios, differences, or combined metrics that sufficiently express connections inside the data. The GroupBy node can also be beneficial for aggregating information, permitting you to outline metrics such as averages or counts, in this manner making informative features.
Another helpful node is the One-to-Many node, which supports transforming categorical factors into different binary columns, making them more appropriate for modeling. This transformation is fundamental for algorithms that cannot operate categorical data specifically.
For a smooth workflow, automate repetitive feature engineering tasks utilizing workflow loops. By consolidating these steps, you’ll make sure that your models are trained on the most pertinent and informative features, eventually driving to superior predictive execution and more actionable insights. Successful feature engineering is pivotal to accessing the full potential of your information mining efforts.
Step 4: Training And Selection Of The Model
The step involves the training and selection of the model. At this stage, you have to apply machine learning algorithms to the arranged dataset and decide the most excellent model for your particular data mining errand. KNIME presents various algorithms through its nodes, facilitating different operations such as classification, regression, and clustering.
Begin by picking suitable modeling nodes per your analysis objective. For instance, in the case of classification tasks, nodes including Decision Tree Learner, Random Forest, and Support Vector Machine are generally utilized. Similarly in the case of regression, consider utilizing nodes such as Linear Regression or Gradient Boosted Trees. Each algorithm has its own grades, so it is imperative to assess multiple choices.
To automate the method of discovering the ideal model parameters, operate the Parameter Optimization Loop node. This node permits you to systematically alter hyperparameters for each model and assess their execution. Via running cross-validation through the Cross-Validation Loop, you’ll be able to evaluate model strengths and make sure that the chosen model generalizes well to discreet data.
An automated model training and selection lets you productively identify the most useful model for your dataset. It confirms that your insights are determined from a well-tuned model, upgrading the steadfastness and precision of your data mining results.
Step 5: Assessment And Approval Of Model
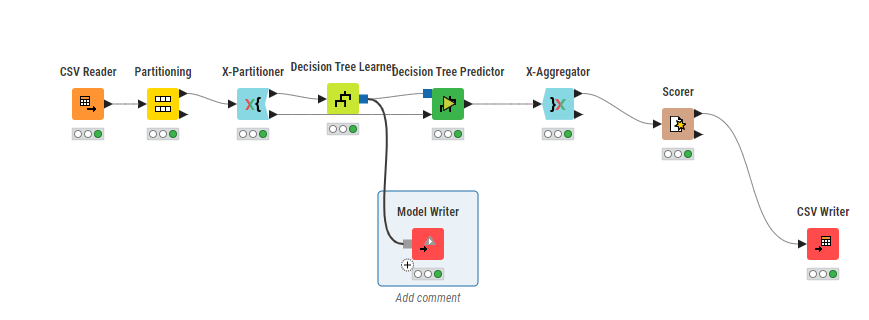
This step is about the assessment and approval of your data mining process, which is significant for assessing the performance of your trained models and guaranteeing that they convey precise and solid predictions. KNIME gives a variety of tools and nodes to encourage intensive assessment.
Begin by utilizing the Scorer node to gauge fundamental performance metrics like accuracy, precision, recall, and F1-score for classification tasks. For regression models, nodes, including Numeric Scorer, help assess metrics like Mean Absolute Error or Root Mean Square Error. These metrics give insights into how satisfactorily your model is enacting and spotlight zones for improvement.
To guarantee the model’s strength, execute cross-validation utilizing the Cross-Validation Loop. This process isolates your dataset into different training and testing subsets, permitting you to evaluate the model’s performance on distinctive data splits.
Also, look into utilizing the ROC Curve node for classification tasks to speculate the trade-offs between true and false positive rates.
Step 6: Implementing The Trained Model
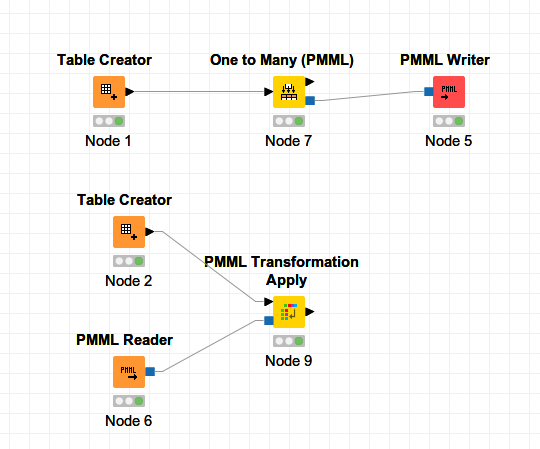
The ultimate step in automating data mining processes with KNIME is deployment and workflow automation. After your model is trained and validated, it is time to implement it in a production environment and automate the complete data mining pipeline for continuous analysis.
For your model deployment, consider utilizing the KNIME Server, which permits you to publish your workflows and make them accessible to other users or systems. It ensures that your insights can be employed in real-time and incorporated into more comprehensive decision-making processes. Moreover, you have a choice to export models to different formats, like PMML, empowering compatibility with different apps.
To attain workflow automation, operate the KNIME Scheduler to establish regular execution of your data mining processes. It permits your workflows to run at indicated intervals, like daily, weekly, or monthly. It ensures that your analyses stay current. By integrating triggers, like file arrivals or data upgrades, you’ll make your workflows responsive to varying data situations.
Furthermore, automate reporting using nodes such as the Table to Report or Image to Report nodes, which can automatically create visualizations and summary reports. It regulates the process of expressing insights to stakeholders.
With an effective deployment of your model and automated workflows, you can make sure that your data mining processes are not only proficient but also versatile. This last step enables you to continuously derive insights and accommodate new information, boosting the value of your data mining endeavors.
Conclusion
In sum, errors can occur in data mining processes, particularly when working with spreadsheets. By automating the mining process, you can thoroughly eradicate human error and establish a transparent, consistent process that boosts your confidence in the data and the insights you may gain from it. For instance, in each data mining project, cleaning and altering raw data into a format suitable for analysis is a must-have but time-consuming step. That being said, data analysts dedicate much of their time to it. You can make data preparation and cleaning an easy, automated process using tools like KNIME, following the steps mentioned earlier and ensuring that your data is always available for analysis.
