How To Apply Natural Language Processing To Unstructured Data
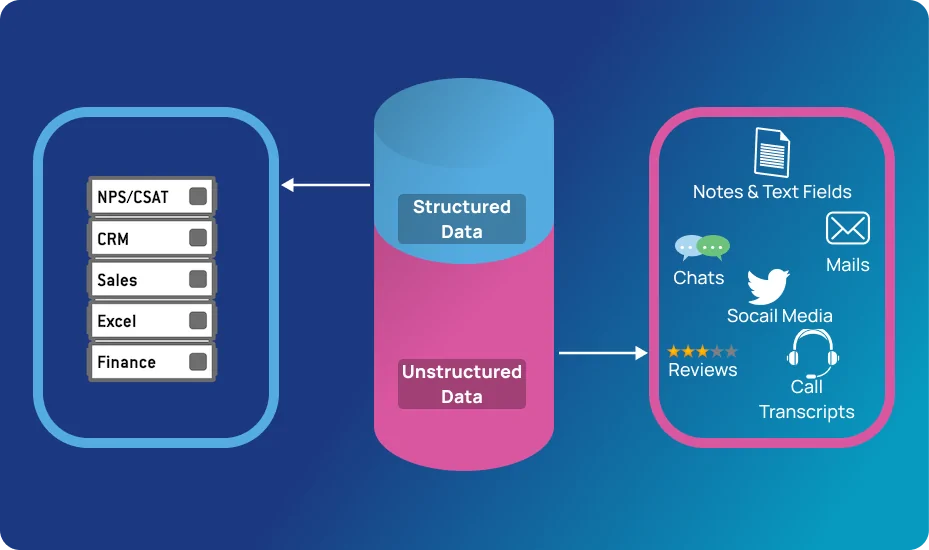
NLP, or Natural Language Processing, is an important aspect of AI that is concerned with the analysis and understanding of human language. The main aim of NLP is to process and handle information from a large set of text with very little manual intervention. With the expanding data in the form of emails, customer reviews, social media content, website data or any other source containing unstructured yet valuable data, it has become challenging for businesses to get significant insights from such data. The use of Natural Language Processing eases the difficulty faced in analyzing raw data. It redefines the unstructured and un-understandable data into a structured and coherent form using influential techniques like tokenization, text classification, sentiment analysis, named entity recognition and more. Organizations can employ NLP to boost text processing automation and customer service, enriching across-the-board decision-making. Nevertheless, when applying Natural Language Processing to structure raw data, there is a need to follow an incremental approach from data extraction to model deployment, resulting in effective outcomes. This blog provides a step-by-step process to successfully structure the unstructured data using NLP.
Step 1: Collect The Pertinent Data

The first step is about gathering unstructured data from various sources, including social media, different sites, PDF files, customer reviews, etc. After identifying the required data, you can use APIs, scraping tools and direct database queries to collect the information.
Once extracted, you will need to clean unnecessary elements or special characters, like extra space, symbols or numbers, from that data. You need to convert all text into lowercase to make it consistent and avoid any mismatches. To correct spelling errors, you can use the tools such as TextBlob or Hunspell.
Utilize NLP libraries like NLTK or SpaCy to filter out the common words with no significant meanings like the, is, and etc.
Subsequent to the filtering of stopwords, you will make use of lemmatization and stemming approaches that turndown the words into their root or dictionary-based forms to get regularity in word demonstration.
Store and process the text carefully using cloud storage or databases. Entertain the idea of using Apache Spark NLP or a similar framework to preserve the text’s scalability as well as speed.
Step 2: Operate Tokenization To Split Text

Splitting text into small components, like words or short sentences, is a useful strategy that can lead to proficient data management, arranging the shapeless data into a suitable and processable layout.
You can operate tokenization for work splitting and rearranging using libraries like NLTK or SpaCY, which also handle the specific rules of language.
You need to keep check of components like dates, mailing addresses, and specific terms, and also avoid inaccurate splitting of words, which you can attain using regex patterns and tokenization rules.
After that, convert the words to numerical forms using BoW or Word2Vec to make them acceptable for machine learning models, which, on the other hand, cannot get raw information.
In closing, you will store the text that you have tokenized using sparse matrices or any other data structures based on the tokenization approaches you employed.
Step 3: Use POS And NER To Tag And Label Words
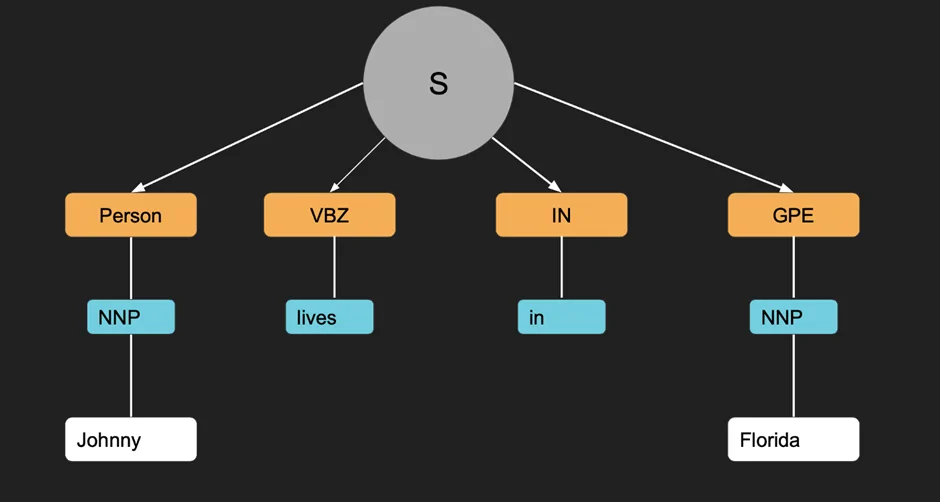
The third step is to use POS tagging and Named Entity Recognition (NER), which label words and identify specific identities, respectively.
For POS tagging, you will use the pre-trained models of NLTR or SpaCy libraries to assign labels according to the words’ role as a part of speech. This operation can enhance the understanding of the meaning and structure of a word.

Likewise, using NER or Named Entity Recognition helps in the identification of different entities, including locations, organizations, dates, names, etc. For that purpose, trained models like CoNLL-2003 can be employed.
Within this task, you will also need to handle the contextual meanings and ambiguities related to words. Since words can have multiple meanings per context, you will need context-aware models like spaCy’s dependency parsing or deep learning-based transformers. It will help resolve ambiguities and improve the text’s understanding of objectives like sentiment analysis.
Step 4: Assigning Labels And Identifying Emotions
We will assign text with predefined labels like spam detection, intent recognition or topic categorization in text classification. For text classification, traditional methods like Naïve Bayes or Support Vector Mechanisms And deep learning techniques like LSTMs, CNNs, or BERT are utilized.
Before you feed data into a machine-learning model, it is essential to convert that data into numerical forms with the help of TF-IDF, BoW or word embeddings. The use of advanced models like GPT and BERT that employ contextual embedding to get deeper language understanding.
For sentiment analysis, pre-trained models like DistilBERT or VADER are utilized to identify positive, negative or even neutral emotions. It is particularly helpful when the text contains customer feedback or social media comments.
To deal with sarcasm and subjectivity modern models that employ context-aware embeddings are used. The Fine-Tuning Transformer-Based can amplify the detection of real-world sentiment.
After training, classification, and sentiment examination, the models can now be deployed with the help of APIs, cloud services, or edge-combusting solutions.
Step 5: Using Topic Modelling And Summarization
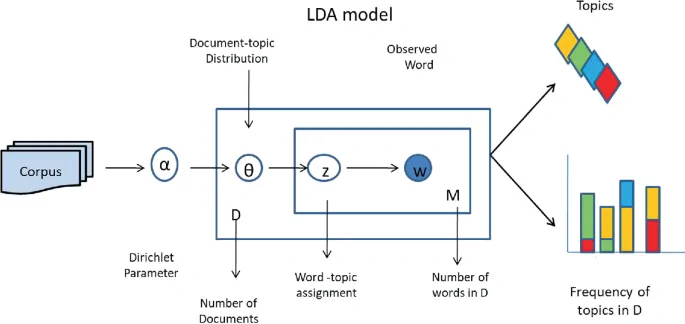
Topic modelling is used to detect the critical themes in the text. The LDA strategy is used to assign each document a distribution of themes, adding to the categorization of text into significant groups. For instance, in news articles, LDA might recognize subjects like politics, sports, or innovation.
Topic modelling is also utilized to bunch identical documents per extracted themes. Strategies such as K-means or DBSCAN can group content based on the topics, empowering way better content organization or recommendation frameworks.
The aim of summarization is to condense a document to its key points. It has two primary sorts.
Extractive type can select critical sentences, and abstractive type creates new sentences. BART or GPT-3 models can be utilized for abstractive summarization, whereas for extractive summarization, TF-IDF or TextRank are functional.
Refine the transformer models such as BERT or T5 for domain-specific text summarization, increasing the pertinence and accuracy of summaries.
The deployment of summarization models is common in news aggregation, content generation, or customer service to consequently condense lengthy text into edible data for the end-users.
Step 6: Embedding The Model
In this concluding step, you will move on to the final phase, which is to embed the model into web applications and business tools with the aid of API’s and microservices. To do that, tools such as Flask and FastAPI can be a helping hand. Moreover, cloud services like AWS or Google Cloud AI can also serve the same purpose.
Once the model is deployed, you need to keep track of its performance, considering factors like speed, precision and user feedback. It also assists you in specifying the areas that require further refinement.
It is a casual happening that the model tends to lose track of accuracy, so you need to update it with new and diverse data in between.
Finally, you can run the NLP models on varying datasets to make sure that they perform neutrally, ensuring that they handle sensitive data efficiently.
Conclusion
To conclude, NLP has an ever-expanding position in corporate solutions that help simplify and automate business operations, raise employee productivity and streamline business approaches. Though this blog content focuses on the role of NLP in processing and structuring raw data, it also serves various other benefits. NLP makes it more manageable for humans to communicate and band with machines by letting them do so in the natural human language they use daily. This tool proposes benefits across many industries and applications, like the automation of repetitive tasks, data analysis, research work content generation, etc., all proving NLP operations’ vast potential.
