
How to use Python libraries to design a web scraping tool?
In today’s world, technology has transformed how companies gather competitive data. Whereas earlier procedures needed manual data extraction, you can now simply obtain information using automation techniques, thanks to web scraping. With each passing day, more and more people in the business and IT sectors are inclining towards web scraping because data extraction is becoming an essential component of business growth. A brand can see how they compete with its competitors by using web scraping. Web scraping tools have also made data about the costs, goods, and analytics of well-known brands available.
Furthermore, you can find various web scraping tools that are easy to use and give you excellent output. However, among these tools, the most common and widely used are python libraries. If you are new to python libraries in web scraping, then this post is certainly for you. In this post, we will provide you with all the necessary information about how to use python libraries for designing web scraping tools. So, let’s dig into it.
What is web scraping?
The method of obtaining data from a website is called web scraping. The method entails gathering and exporting data in a way that the user will find more valuable. The most common forms for the data are CSV files, Excel, and Google Sheets. Most of the people who use web scraping are businesses that want to see competitors’ data. They’ll typically retrieve data that helps their SEO strategies. Most firms would be interested in the following information:
Market research and insight
Price intelligence and monitoring
Lead Generation
Product details
Sports stats for betting purposes
List of business locations
Content and news monitoring
Why are python libraries good for web scraping?
For developing a web scraper, many developers prefer Python over other languages for a variety of reasons. Python is a general-purpose language; thus its tools can be used to create an extremely flexible web scraper that can perform more than just data extraction. Moreover, python web scraping makes it possible to collect data, parse and import it, and even visualize it, which would be challenging to do with other computer languages. The language is highly adaptable and flexible in many aspects. Last but not least, these tools are built and executed just once and then allowed to run automatically subsequently.
How to use Python libraries to design a web scraping tool?
Make careful to select “PATH installation” when installing Python on Windows. The default Windows Command Prompt executable search receives additional executables after PATH installation. When this happens, Windows will understand commands like “pip” or “python” without users having to guide it to the directory containing the executable (such as C:/tools/python/…/python.exe). If you already installed Python but neglected to check the box, simply choose modify during installation again. Select “Add to environment variables” on the second screen.
Getting to the libraries
A wide variety of libraries for web scraping is one of Python’s benefits. There are already over 300,000 Python projects on PyPI alone, and thousands of them use these web scraping libraries. Notably, you can select from a variety of Python web scraping libraries, including:
Requests
Beautiful Soup
lxml
Selenium
1 Requests Library
Sending HTTP queries, such as POST or GET, to a website’s server and waiting for the server to respond with the required data is the first step in web scraping. Standard Python HTTP libraries, on the other hand, are challenging to use and necessitate lengthy lines of code for effectiveness, adding to an already severe problem.
With fewer lines of code than existing HTTP libraries, the Requests library streamlines the process of sending such requests, improving readability and debugging without sacrificing performance. Using the pip command, the library can be installed directly from the terminal:

Simple methods for sending HTTP GET and POST requests are provided by the Requests library. The function to send an HTTP Get request, for instance, is suitably named get():

The post() method makes forms to be posted simple if that is what is required. The form data can be supplied as a dictionary as seen below:

It is also quite simple to employ authentication-required proxies, thanks to the Requests library.
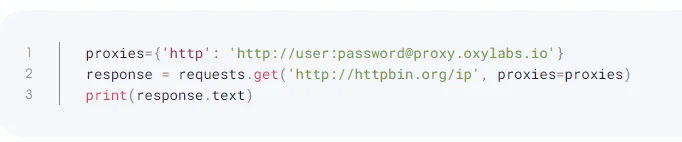
However, this library has a drawback in that it cannot parse the captured HTML data into a more understandable format for analysis because it does not do so. Additionally, it cannot be used to scrape websites created entirely in JavaScript.
2 Beautiful Soap
With the help of a parser and a Python library called Beautiful Soup, it is possible to turn even invalid markup into a parse tree and extract data from HTML. This library, however, cannot make requests for data from web servers in the form of HTML documents or files because it is only intended for parsing. It is typically used in conjunction with the Python Requests Library because of this. It should be noted that while Beautiful Soup makes it simple to query and explore the HTML, a parser is still necessary. The Python Standard Library’s HTML.parser module is used in the example that follows to show how to utilize it.
Part 1 – Get the HTML using Requests

Part 2 – Find the element
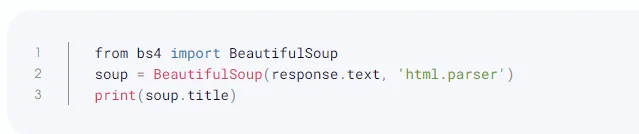
The title element will appear in the following format:

Beautiful Soup is perfect even for beginners and typically saves developers hours of labor due to its simple methods of navigating, searching, and modifying the parse tree. The findAll() method, for instance, can be utilized to print all of the blog titles from this page. Every blog title on this page is contained in an h2 element with the class attribute set to blog-card content-title. The following details can be provided to the findAll method:
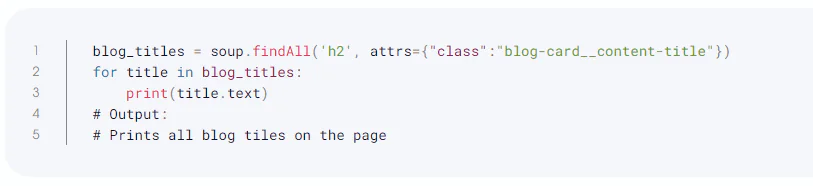
Working with CSS selectors is also made simple with Beautiful Soup. A developer does not need to understand the find() or find all() methods if they are familiar with CSS selectors. An identical example is shown here, but CSS selectors are used:

While broken-HTML parsing is one of this library’s key characteristics, it also performs a wide range of other tasks, such as the ability to recognize page encoding, which improves the accuracy of the data taken from the HTML file. Additionally, it is simple to configure and can be used to extract any custom publically available data or to recognize particular data types with just a few lines of code.
3 lxml
lxml is a parsing library. It is a quick, efficient, and simple-to-use library that supports both XML and HTML files. IXML is also perfect for extracting data from huge collections. But unlike Beautiful Soup, this library’s parsing powers are limited by HTML that isn’t well written.
The pip command can be used to install the lxml library from the terminal:

This library includes the HTML module for working with HTML. However, the HTML string is required by the lxml library first. The Requests library, which was covered in the previous part, can be used to retrieve this HTML string. The tree can be constructed using the fromstring technique once the HTML is provided as shown below:

With XPath, you can now query this tree object. Keeping with the example from the previous section, the XPath would be as follows to obtain the titles of the blogs:

This XPath can be given to the tree.xpath() function. All of the elements that match this XPath will be returned by this. Take note of the XPath’s text() function. By doing this, you may extract the text from the h2 elements.

4 Selenium
As previously mentioned, some websites are created in JavaScript, a language that enables programmers to dynamically fill fields and menus. This poses a challenge for Python libraries that can only extract data from static web pages. In reality, as indicated, JavaScript does not support the Requests library. Selenium web scraping thrives in situations like this.
An open-source web driver (browser automation tool) for Python, this library enables you to automate tasks like logging into social media sites. For running test cases or test scripts on web applications, Selenium is frequently used. Its advantage during web scraping comes from its capacity to start displaying web pages by executing JavaScript — a computer language that standard web crawlers are unable to execute. However, developers currently use it a lot.
Selenium requires three components:
Web Browser – Supported browsers are Chrome, Edge, Firefox, and Safari
Driver for the browser
The selenium package
The selenium package can be installed from the terminal:

The proper class for the browser can be imported after installation. The class object must be created after being imported. Keep in mind that the driver executable’s path will be necessary. Here is an illustration using the Chrome browser:

The get() method can now be used in the browser to load any page.

With Selenium, you can extract elements using XPath and CSS selectors. Using CSS selectors, the following example prints each blog’s titles:

In short, Selenium handles any dynamically displayed content by running JavaScript, making the web page’s content accessible for parsing using built-in techniques or even Beautiful Soup. It can also imitate human behaviour.
The only drawback to utilizing Selenium for web scraping is that it takes longer because each page’s JavaScript code must be executed before it can be parsed. It is therefore not the best option for extensive data extraction. Selenium is an excellent option, but, if you want to extract data on a smaller scale or the lack of speed is not a problem.
Final words
Python is the ideal language for web scraping, as can be seen from the way that web scrapers are created and developed using various Python tools. These Python web scraping solutions often have excellent performance and are simple and clear to code.
The adaptability and flexibility of the language are also used practically when creating tools that do tasks other than data extraction. Additionally, these tools are created and run only once before being permitted to continue operating automatically.
