
How to scrape a website in C++?
In this technological world, no business can expand its horizons if it is not aware of what its rivals are doing. These days, the best method one can find to extract data from its competitor’s website is web scraping. Web scraping is a smart technique that is used to harvest a tonne of data from the target websites. The extracted data can then be saved as a spreadsheet or to a local file on your computer. Benefits of web scraping include the ability to automate the steps involved in using scripts to collect data from websites. It has become a crucial method for learning about your business and using it to produce a dataset for your decision engine due to the abundance of data available on the internet.
You can find many web scraper or web scraping tools in the online market, however, in this post, we will tell you about how one can use C++ to extract data; a very common and widely used programing language.
What is C++?
Since 1979, C++ has been a general-purpose programming language designed to handle a wide range of use cases. C++ was created with a system programming focus, according to Bjarne Stroustrup, but has undergone major advancements since its initial release.
Along with its basic features, it now includes object-oriented features and memory manipulation. Basically, C++ is a pretty versatile language that wasn’t designed from the ground up for web use but can support techniques like web scraping with ease.
Why should one use C++?
1 Commonly used: One of the top five languages in the world of programming is C++. More than 25% of all programming in the world is done in one of the C family of languages. Numerous programmers in the hundreds of thousands are already familiar with it.
2 Various libraries: Since C++ has been around for so long, you can utilize thousands of libraries alongside it. Every budget can be met because there are both free and paid libraries.
3 Lots of support: The International Organization for Standardization actively promotes, standardizes, and maintains C++. It is updated every three years with new standard libraries and functionalities because it is so crucial to the world of coding.
4 Highly scalable: The majority of the code is reusable if you start with a tiny project and determine web scraping is right for you. With a few little adjustments, you’ll be prepared for significantly bigger data quantities.
5 Object-oriented: It implies that it uses inheritance, classes, and data abstraction to make your code more adaptable to different uses. You can store and parse data more easily because it is viewed as an object.
How to scrape a website in C++?
Prerequisites
- C++ IDE. Visual Studio will be used in this manual.
- A C/C++ package manager developed and maintained by Windows is called vcpkg.
- The Python requests library served as the inspiration for the C/C++ library known as cpr, which was created as a wrapper for the original cURL.
- Gumbo is a C-based HTML parser that offers wrappers for several other programming languages, including C++.
Step 1: Setting the environment
1 Create a simple project by selecting a Console App template after downloading and installing Visual Studio.
2 We’ll now set up our package manager. A well-written guide is provided by Vcpkg to help you get started as quickly as possible.
Note: Setting an environment variable after the installation is finished will allow you to launch Vcpkg from any location on your computer.
3. The time has come to install the necessary libraries. Run the following commands in any terminal after setting an environment variable.
vcpkg install cpr
> vcpkg install gumbo
> vcpkg integrate install
Simply go to the location where you installed Vcpkg, launch a terminal window, and enter the same commands if you didn’t add an environment variable.
The first two statements set up the necessary packages for us to construct our scraper, and the third act makes it simple for us to incorporate the libraries into our project.
Step 2: Pick a website and inspect the HTML
We are now ready to go! We must choose a website and study the HTML code of that website before we construct the web scraper.
When we visited Wikipedia, we randomly selected a page from the “Did you know…” section. The Wiki article on the poppy seed defense will be today’s scraped page, and we will take some of its elements. Let’s first examine the page structure, though. Anywhere in the article, simply right-click, choose “Inspect element,” and bingo! The HTML is ours.
Step 3: Extract the title
We can now start writing the code. We must download the HTML locally in order to extract the information. Import the libraries that we just downloaded first.
#include <iostream>
#include <fstream>
#include “cpr/cpr.h”
#include “gumbo.h”
The HTML is then retrieved by sending an HTTP request to the target website.
std::string extract_html_page()
{
cpr::Url url = cpr::Url{“https://en.wikipedia.org/wiki/Poppy_seed_defence”};
cpr::Response response = cpr::Get(url);
return response.text;
}
int main()
{
std::string page_content = extract_html_page();
}
Now that the HTML for the article is stored in the page_content variable, we can use it to further extract the information we require. The gumbo library is useful in this situation.
The previous page_content string is transformed into an HTML tree using the gumbo_parse method before our implemented function search_for_title is called for the root node.
int main()
{
std::string page_content = extract_html_page();
GumboOutput* parsed_response = gumbo_parse(page_content.c_str());
search_for_title(parsed_response->root);
// free the allocated memory
gumbo_destroy_output(&kGumboDefaultOptions, parsed_response);
}
The called function will make recursive calls in order to thoroughly search the HTML tree for the h1 tag. When the title is located, the execution will end and the title will be displayed in the console.
void search_for_title(GumboNode* node)
{
if (node->type != GUMBO_NODE_ELEMENT)
return;
if (node->v.element.tag == GUMBO_TAG_H1)
{
GumboNode* title_text = static_cast<GumboNode*>(node->v.element.children.data[0]);
std::cout << title_text->v.text.text << “\n”;
return;
}
GumboVector* children = &node->v.element.children;
for (unsigned int i = 0; i < children->length; i++)
search_for_title(static_cast<GumboNode*>(children->data[i]));
}
Step 4: Extracting the links
For the remaining tags, the same fundamental idea applies: we navigate the tree to find the information we want. Let’s gather every link and take note of its href attribute.
void search_for_links(GumboNode* node)
{
if (node->type != GUMBO_NODE_ELEMENT)
return;
if (node->v.element.tag == GUMBO_TAG_A)
{
GumboAttribute* href = gumbo_get_attribute(&node->v.element.attributes, “href”);
if (href)
std::cout << href->value << “\n”;
}
GumboVector* children = &node->v.element.children;
for (unsigned int i = 0; i < children->length; i++)
{
search_for_links(static_cast<GumboNode*>(children->data[i]));
}
}
See? Except for the tag we’re looking for, the code is quite identical. Any attribute we specify can be extracted using the gumbo_get_attribute method. You can therefore use it to search for classes, IDs, etc.
It is imperative to do a null check on the attribute’s value before displaying it. This is unneeded in high-level programming languages because it just displays an empty string, but in C++, the application will crash.
Step 5: Write to CSV file
There are several links available, scattered all around the text. Additionally, this article was incredibly brief. So let’s externally save them all and see if we can distinguish between them.
We create and open a CSV file first. This is done outside of the function, quite close to the imports. Our code is recursive, so if it generates a new file each time it is invoked, we will have a LOT of files.
std::ofstream writeCsv(“links.csv”);
The first row of the CSV file is then written in our main function before the function is first called. Keep in mind to close the file once the execution is finished.
writeCsv << “type,link” << “\n”;
search_for_links(parsed_response->root);
writeCsv.close();
We are now writing its content. When we locate a <a> tag in our search for links function, we now do the following instead of displaying it in the console:
if (node->v.element.tag == GUMBO_TAG_A)
{
GumboAttribute* href = gumbo_get_attribute(&node->v.element.attributes, “href”);
if (href)
{
std::string link = href->value;
if (link.rfind(“/wiki”) == 0)
writeCsv << “article,” << link << “\n”;
else if (link.rfind(“#cite”) == 0)
writeCsv << “cite,” << link << “\n”;
else
writeCsv << “other,” << link << “\n”;
}
}
With this code, we take the value of the href element and divide it into three categories: articles, citations, and everything else.
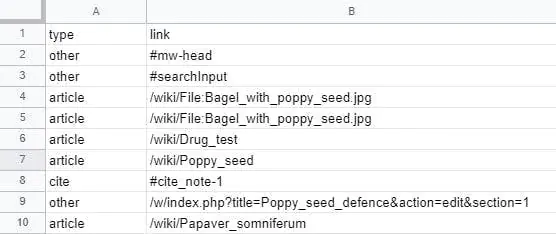
Obviously, you may go even further and create your own link categories, such as ones that resemble articles but actually files.
Conclusion
An HTTP client that is handling a user request for data utilizes an HTML parser to search through the data in a process known as web scraping. It makes it simpler for programmers to access the data they require for their projects.
Fortunately, web scraping has improved and is supported by several computer languages, including C++. The widely used system programming language has a variety of advantages for web scraping, including speed, strong static typing, and a standard library with type inference, generic programming templates, concurrency primitives, and delta functions.
