
How To Use Proxies For Web Scraping With Python?
“Python” is a high-level programming language that is commonly used in mobile application development, web development, and seamless data extraction. Python is generally considered a well-suited programming language for web scraping owning to its large capacity to handle crawling processes and carry out data extraction smoothly. When you combine the security of a web proxy with the functionalities of Python you can increase your performance level to smoothly carry out scraping activities without the fear of IP blockage. In this blog, we will learn more about what proxies are and how they are used for efficient data extraction coupled with Python. Let us get started with a few basic terminologies that we can’t move forward without understanding.
What is Web Scraping?
Web Scraping is the method of data extraction from different websites and web pages. Usually, web scraping is carried out by an expert using a HyperText Transfer Protocol (HTTP) request or by using a web browser. The web Scraping process works by crawling the URLs and later on downloading the page data one at a time. The extracted data is collected and stored in a spreadsheet. You can save countless hours when you opt for automated web scraping solutions that can speed up the process of copy and pasting data to spreadsheets. You can easily extract loads and loads of data from hundreds of URLs based on your interest to stay ahead of your business competition.
Example of Web Scraping
Let us suppose you wish to download a list of all pet parents in Australia. You can scrape the web directory having the names and email addresses of people living in Australia who own a pet. You can use specialized web scraping software to accomplish the task. The software will crawl all the relevant information from the required URLs and then collect information in a suitable file format.
Why Use A Proxy For Web Scraping?
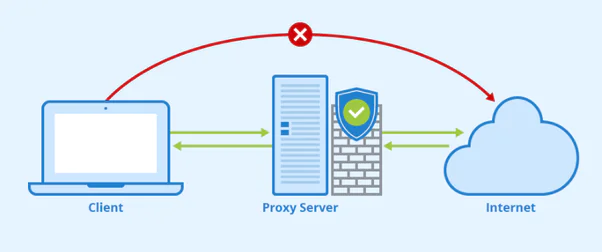
The proxy allows you to bypass any information that is otherwise impossible to get. Using a proxy you can decide the location of information of your choice. You can place a higher number of connection requests without getting your IP blocked. A proxy also increases the chances of your request to copy data being accepted without facing any complications. Overall data extraction process works smoothly and speeds up your ISP. Owning a suitable proxy server you can crawl any program and download information without getting yourself in trouble. Now that we have covered almost all the basic concepts of proxies and web scraping. Let us come to the main topic “How to perform web scraping using a proxy with Python?”
Configure a Proxy for Web Scraping with Python
Web Scraping using Python begins as soon as you send an HTTP request. The HTTP request is based on the server or client model to access the content of a web page and the server returns a response to the Python program. The simple method of sending an HTTP request is to send the request manually by opening a socket. A simplified HTTP request example is given below:
(Start of Code)
import socket
HOST = ‘www.mysite.com’ # Server hostname or IP address
PORT = 80 # Port
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = (HOST, PORT)
client_socket.connect(server_address)
request_header = b’GET / HTTP/1.0\r\nHost: www.mysite.com\r\n\r\n’
client_socket.sendall(request_header)
response = ”
while True:
recv = client_socket.recv(1024)
if not recv:
break
response += str(recv)
print(response)
client_socket.close()
(End of Code)
You can send requests using built-in modules such as urllib2 and urllib. However, using these modules requires appreciable code understanding which is why a good alternative is to use HTTP requests from the HTTP library for Python. You can easily configure proxies using HTTP requests. The code required to enable the use of proxy in HHTP requests as stated below –
(Start of Code)
import requests
proxies = {
“http”: “http://10.XX.XX.10:8000”,
“https”: “http://10.XX.XX.10:8000”,
}
r = requests.get(“http://toscrape.com”, proxies=proxies)
(End of Code)
In the proxies part of web scraping, you need to specify the port address along with the proxy address. If you wish to use a proxy and include a session at the same time then you should refer to the below-mentioned code –
(Start of Code)
import requests
s = requests.Session()
s.proxies = {
“http”: “http://10.XX.XX.10:8000”,
“https”: “http://10.XX.XX.10:8000”,
}
r = s.get(“http://toscrape.com”)
(End of Code)
In many instances, you are required to create a session to add a proxy. For this very reason, you must create a session object.
(Start of Code)
import requests
s = requests.Session()
s.proxies = {
“http”: “http://10.XX.XX.10:8000”,
“https”: “http://10.XX.XX.10:8000”,
}
r = s.get(“http://toscrape.com”)
(End of Code)
By using the HTTP requests package the overall process might become slow due to data extraction of “one URL at a time” with every request. Now imagine if you want to scrape 100 URLs then for this reason you will have to send requests 100 times only when the previous requests are accepted. To speed up the web scraping process there is yet another package known as grequests. This program allows you to send various requests at one time. It is an asynchronous API that is popularly used by developers in developing web applications.
We present to you the code which explains the processing of grequests. Let us imagine a hypothetical situation where one has to scrape 100 URLs. In this scenario, one needs to keep all 100 URLs in line and use the grequests package to manually specify the URL batch length to 10. In this way, you will require an investment of less energy in sending 10 requests at a time to complete 100 URL requests instead of sending 100 requests for 100 times which is indeed a headache.
(Start of Code)
import grequests
BATCH_LENGTH = 10
# An array having the 100 URLs for scraping
urls = […]
# results will be stored in this empty results array
results = []
while urls:
# this is the first batch of 10 URLs
batch = urls[:BATCH_LENGTH]
# create a set of unsent Requests
rs = (grequests.get(url) for url in batch)
# send all the requests at the same time
batch_results = grequests.map(rs)
# appending results to our main results array
results += batch_results
# removing fetched URLs from urls
urls = urls[BATCH_LENGTH:]
print(results)
# [<Response [200]>, <Response [200]>, …, <Response [200]>, <Response [200]>]
(End of Code)
Conclusion
Web scraping is a good option for laying your hands on your desired datasets especially if you belong to an eCommerce community having eCommerce websites. Real-time information can be extracted to make up better business formulas and decisions in time for better business growth. Python provides various frameworks and request libraries to make data extraction procedures easy. You can extract data efficiently and faster which are the two biggest concerns of data scientists. Apart from this, it is significant to use a proxy to protect your IP address from getting blocked. Python combined with a secure proxy server is the baseline for a successful web scraping process.
If you are interested in ITS Web Scraping Services, you can ask for a free quote and our representative will get back to you within 24 business hours!
