
How To Build A Web Scraper With JavaScript?
Web Scraping is the process of data extraction from online web pages based on personal or business incentives. The acquired data can be analyzed to perform various tasks including an easy comparison of eCommerce product prices with your market competition, collection of customer contact details like phone numbers and email addresses for future sales outreach, automating social media marketing efforts by extracting data from leading websites, and to conduct a thorough market analysis on a larger scale to make better market competitive decisions.
All businesses whether big or small can use web scraping to achieve long-term business objectives. JavaScript is a popular and high-level web programming language to carry out complex web scraping processes along with Node.js code outside a web browser. In this blog, we will shed light on the workflow of web scraping using Node.js and JavaScript. In addition, other important facts will also be covered at the end of this blog. When you reach the last word of this read you will be able to make the web scraping task more manageable.
What is meant by Web Scraping?
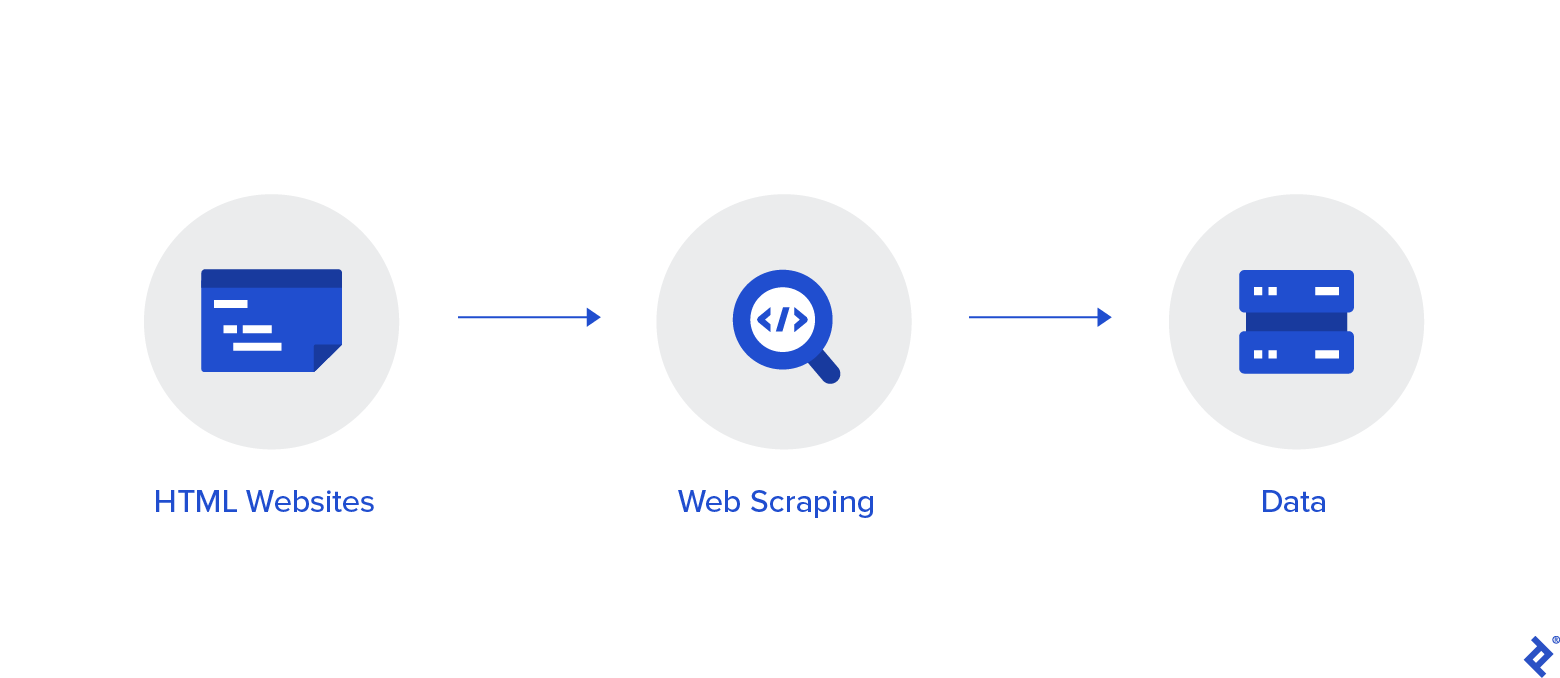
Web scraping commonly known by other names such as data extraction, data scraping, web harvesting, etc is a technique to extract data from a website via automated means and store it in a portable format to be accessed when required for further analysis.
The web scraping process functions in two notable ways:
Fetching: The web page is acquired using a headless browser or an HTML request library. Web crawling is an essential element required to download a web page successfully.
Extracting: once the page is crawled by a web crawler data extraction takes place. Data extraction is the process by which parsing and restructuring of data take place. The information is stored in a spreadsheet or any pre-existing file format that contains all web scraping data.
What is a Proxy Server?
A proxy server is used to mask IP addresses to secure them from being detected by the target websites. A website sees your proxy server as a primary IP address thus allowing it to browse through the information anonymously.
Why is a Proxy Server essential before you run your Scraping Program?
You should begin web scraping by using a proxy server that can help you to access and extract information easily. A proxy server plays an important role in saving your IP address from being blacklisted. Popular websites have a greater organic traffic rate this is the reason they employ highly efficient anti-scraping mechanisms. When you use a scraping program to get access to their platform data they can easily trace your scraping program using JavaScript. As a result, your bot is traced and your IP address gets blacklisted from the program. When you use a proxy server all the sent requests by the scraping program go through the proxy server. It is always advised to use residential proxies due to anonymity. Moreover, the proxy server provides a collection of IP addresses & IP rotation technique that manipulates the IP address linked with each browser request. The anti web scraping tools allow browsing websites because the requests come from various locations and mimic regular user activity.
Building a Web Scraper using JavaScript and Node.js
JavaScript is an advanced programming language that adds more interactive components to a website. Although the program does not directly interact with the computer. It more specifically interacts with your JavaScripts browser engine to run the code. However, the use of Node.js with JavaScript enables you to run scripts on both sides including the server-side and the client-side.
Here are a few steps you need to consider when scraping the web using Node.js and JavaScript:
Step 1: Identify the URL that you wish to crawl.
Step 2: Download dependencies such as Cheerios and Axios by using the code given below;
$ mkdir scraper && cd scrapper
$ npm init -y
$ npm install –save axios cheerio
Step 3: Now add them to your index.js file by using this code as written below;
const siteUrl = “https://addurlyouwishtoscrape.com/”;
const axios = require(“axios”);
const fetchData = async () => {
const result = await axios.get(siteUrl);
return cheerio.load(result.data);
};
Step 4: You can investigate all the elements that you wish to target by using the chrome developer tool “Inspect option”. Moving onwards just add the respective codes to the main folder to scrape the intended data directly.
Step 5: You can save the scraped information in your favorite file format. For instance you can save the extracted data in JSON file using the reference code given as under;
const fs = require(‘fs’);
const getResults = require(‘../scraper’);
(async () => {
let results = await getResults()
let jsonString = JSON.stringify(results);
fs.writeFileSync(‘../output.json’, jsonString, ‘utf-8’);
})()
This is pretty much all that is required to scrape a website using Json.js.
Effective Ways to Build a Web Scraper

There are various ways by which you can build a portable and useful web scraper from Node.js and JavaScript. Two methods prove highly useful in this regard, which are chiefly discussed as follows;
Combining the Power of Python and Selenium
You can make use of the popular web programming language i.e. Python for web scraping. A good Python library is Selenium as it assists web browsers to automate various functions. You just need to install Selenium and access its official website using Python (A high-level programming language). You will need to locate the XPath element to scrape the pinpoint element.
Using Puppeteer for Web Scraping
By using a puppeteer which is a node library you can easily control Google Chrome. You can utilize Puppeteer to automate and generate submissions. You can even format the screenshots of web pages. To begin your experience with Puppeteer you will need to install the program. You can combine Puppeteer with Node.js to extract various websites for unique data. However, keep in mind to use a Proxy when scraping with Puppeteer.
Conclusion –
Web Scraping has become crucial for every business in this increasingly advanced digital era. Data becomes outdated and evolved at the same time therefore the need for data is never enough. There are various ways by which you can scrape a web notably, JavaScript and Node.js. You can use powerful automated tools or data mining programs to copy information from websites of your concern. You can use any method described in this blog for efficient data harvesting. To hide your IP addresses make sure to use a proxy server. It will work as an anonymous web scraper for faster results and keep your business reputation secure.
How ITS Can Help You With Web Scraping Services?
Information Transformation Service (ITS) offers a variety of exceptional web scraping services. With a leading team of data scientists, we ensure high-quality data solutions for your web scraping projects. We are an ISO-Certified company that works to address all of your big and reliable data concerns. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
