
How To Scrape Data With An API?
In a computer Programming language, API is referred to as an application programming interface which is a set of tools for constructing various software applications. In simple words, API is defined and described as a method of efficient communication between various components of software; A Web API is a set of rules for professional developers which are required to be followed whenever they interact within the programming language. Just like Harry Potter would have to say ‘Alohomora’ to unlock the door, similarly, the developer needs to follow the prescribed set of rules set as standard.
One of the biggest misconceptions out there in the data world is that people believe that API can extract data. This statement is not true and nor is completely falsified! Data can be retrieved via dedicated resources and in certain case scenarios you only get what you request and other information available on the web page is not accessible to you.
For Example: If you need to conduct sentiment analysis and for this, you require a bunch of comments and reviews. In this case, a Web API is more commonly used to send in a request for a specific keyword to the webserver. In return, the webserver offers the reviews which you wanted in the first place. Hence, this is more of a target information retrieval in raw data format. What a raw data format looks like, you can collect the idea by looking at the reference image given below, which is without rows and columns.

In this case, to consume data from any product page you need to follow a certain set of steps for extraction in intact format, transformation, and storage of data. At times you might as well need to convert the raw data into your desired format for business suits, which is easy for experienced programmers and developers but for a layman or beginner, the task can be mind-boggling.
To lessen the complexity rate of data extraction for a starter, it is better to employ a web scraping software tool with an already API integration. This is to gather as much data and transforming it into a desirable format at the very instance. If coding is not your strong point then you can simply read the highlighted sections. The code makes use of Google’s JSON Custom Search API.
To begin, just assume that we have already surfed through the corresponding email addresses, and first to last names are extracted which land in the search bar. API will search each item within the list and will save the first 10 occurring show results. Change the variable number again and again if you want more hits.
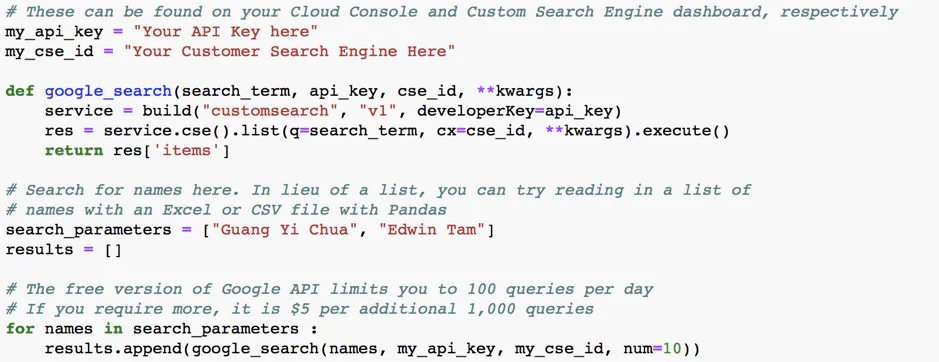
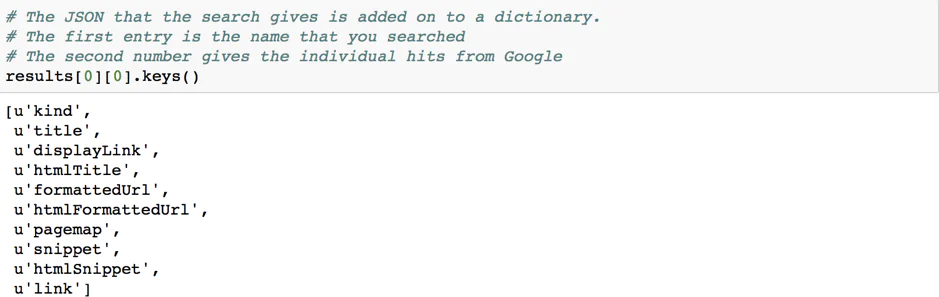
After your search comes to an end, Python saves the result in JSON format.
Now we need to extract the ‘Dictionary Keys’ in the form of relevant rows or columns of our own choice into Pandas DataFrame.

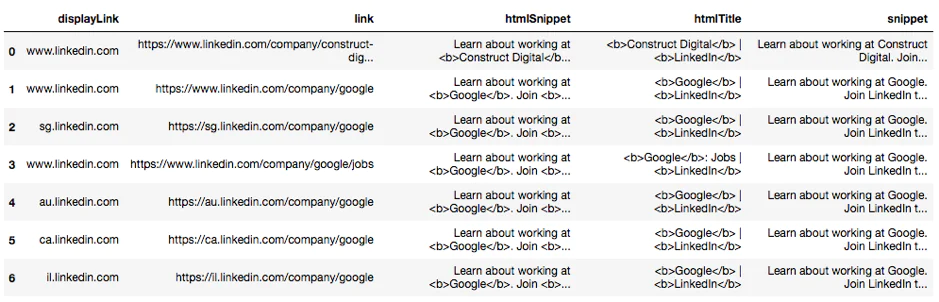
Now you have successfully found out the top 10 search output based on your interest. You can use this newfound information for conducting further rigorous analysis and can target more customers as well as be the use this data for generating future business leads. This kind of script also operates successfully with company names present in email addresses.
We have limited our search options to LinkedIn Company Profiles; as such company pages have a lot more useful information than the rest. Just like company headquarters, located city, number of employees, etc.

After some filtering and formatting, the results look like this:
From here you can export the extracted data into subsequent databases. Remember to use as many queries as Google’s API is investigated payment schedule. Do congratulate yourself for successfully achieving your first data extraction target. Before setting out to scrape the whole Internet, do keep in mind that there are certain ethical limitations concerning web scarping.
Considerate and Ethical Scraping
If the company or the website provides you with a certain API, then the information which is accessible via API is considered public. Here a popular question arises, what happens to the information if there is no API, or the API does not yield the desired amount of target information? This is where we need to consider our ethical considerations concerning web scraping. Our primary responsibility is to not stick our nose violating other’s privacy! Keeping this in your mind you can check these points before running the web scraper:
Check the Robots.txt File
You can find the page by adding ‘/robots.txt’ at the end of the URL. More often, any of the mining tools we state will directly fall under the ‘user-agent part of the web page. The most common types of listings are mentioned below:

Enough Time between Requests
You should limit the rate of queries, charging hundreds of requests per second towards the target website are tantamount to cyber-attack and your IP eventually at the very spot will get blocked. It is advised to send just (1 query every 5 to 10 seconds), to avoid any failed attempt.
Identify Yourself
You only need to double-check this step if you are accessing any website without the use of an API. However, if you are using an API then you have already identified yourself to the website, and no need for further identification.
Just to make things more crystal clear, identifying yourself is crucial for two main objects. Number one, it tells the website administrator that you are no intruder trying to barge into the website, and secondly, it provides them a significant way to contact you which is always essential as it is theirs information which you are interested in the first place!
The following script provides an excellent example about how to format your identity and as a result, use it as a part of your queries:
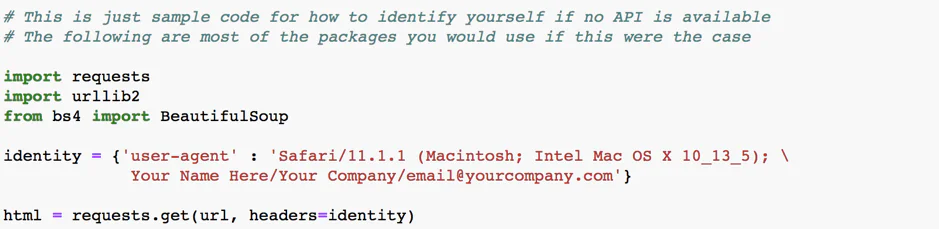
Just by closely following these simple steps you can scrape various websites instantly and your responsible web scraping will lead to open data access for all data lovers.
Final Disclaimers
Web Scraping must be utilized responsibly and must be done by conforming to ethical standards for driving more efficient means of repository knowledge for both Marketers and Developers. There are many websites such as Facebook, LinkedIn, eBay and Taobao, and more which do not let your scrape their data. Hence, it is always best to be strong advocates of data privacy and data protection within commercialized sectors.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
