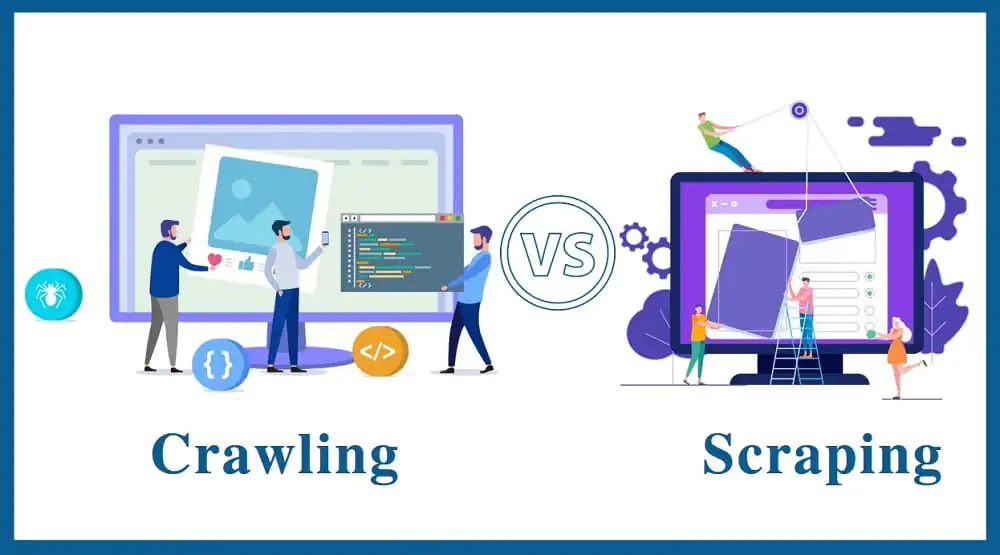
Data Scraping Vs Data Crawling
Are you someone who has struggled over the past few years distinguishing between web scraping and web crawling? This blog essentially states all facts regarding web scraping and web crawling to save you from this problem. Many people find it difficult to fully draw a line between these two popular terms. However, there is a very visible difference between them. Web scraping and web crawling are not at all identical terminologies but are in fact cousins. We have tried to keep things simpler for you to make you understand all key differences and applications of web scraping and web crawling for your better business advantage.
What Is Web Scraping?
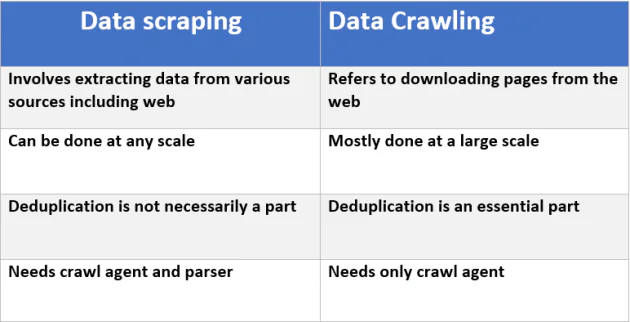
Web Scraping is defined and described as the extraction of data from any intended website in an automated manner. Due to the reason, that high-end bots are utilized for the process to draw information from the websites, the programmatic analysis further downloads the available web page content. Data Scraping is best to locate and extract data more quickly.
Web Scraping Example
For extraction of data like product prices to drive more sales intelligence web scarping can be used. Websites such as Amazon or any other E-commerce site can be scraped for various product prices.
What Is Web Crawling?
By crawling, an idea pops in our minds of something which consists of crawling thingies like a spider. That is the reason why web crawling is often termed as a spider. It is a bot that runs by systematically browsing through the Internet. The purpose of web crawling is generally web indexing. It utilizes all the information or content available on the web pages via bots called crawlers. Crawling is data surfing through every crevice and nook of the World Wide Web. As spiders are good at making closed webs similarly web crawlers retrieve information that lies deeper penetrated within the databases of the web page.
Web Crawling Example
What Google, yahoo, and Binge do is a significant example of web crawling.
How Does Web Scraping Work?
Web Scraping Process involves the below mentioned three key steps:
Request-Response
The foremost basic step is to make a request to the target website for the information via URL. Afterward, the scraper extracts all the target content in HTML file format.
Parse and Extract
Parsing is an important function within web scarping. It can be applied to any computer language. It draws code as text and produces the structure in the memory of the computer. In this way, information becomes easier to work with. In simple terms, HTML parsing enables the HTML code and draws all related information such as page title, the basic structure of the content, headings, sub-headings, and incorporated links, etc.
Download Data
The final step is to download and save all the content which is extracted in CSV, JSON, or database.
How Does Web Crawling Work?
Web Crawling Process is described in simple doable steps:
Select a target URL.
Add the URL in the frontier.
Now shift the URL from the frontier.
Fetch the web-page with the corresponding URL.
Now you need to parse the web page for new URL links.
You can add the newly found URL links in the frontier.
Repeat step 3 and continue until the frontier hits completion.
Web Scraping Tools
There are many web scraping tools and techniques available in the market about which you should be aware. A few are mentioned below for your concern:
ProWebScraper
ProWebScraper helps extract all the data from any website which assists in scraping larger volumes of data from any website. It designs the web scarping method as an all-new effortless data exercise. The point-and-click user interface is extremely potent to all who are not blessed with the technical knowledge of complex web scraping tasks.
Webscraper.io
Webscraper.io is a chrome-based extension that makes data accessible from any website. Using Webscraper.io you can easily create a plan on how to traverse a website and what kind of data can be extracted for better business solutions. Scraped data is convertible to CSV file format for direct use.
Web Crawling Tools
Web Crawling Tools that are most commonly applied during the process are listed below:
Scrapy
Scrapy is a well-known web crawling tool or scraping framework which is widely employed by all professional crawling websites. The tool can be helpful for several data objectives such as data monitoring, data mining, automated data testing, and much more. The tool operates perfectly fine with Python. Scrapy also runs fabulous on Linux, Windows, and Mac OS.
Apache Nutch
Apache Nutch is an authentic web crawler tool that efficiently scales data for your scraping projects. The tools are immensely popular in Data Mining and are frequently used by data scientists, developers in developing web scraping applications and web text mining. The cross-platform solution is well written in JAVA.
Application of Web Scraping
Retail marketing
In the E-commerce business, there are many kinds of new spaces where web scraping is largely used. Whether you want to monitor your competitor’s website or want to go for compliance monitoring MAP, Web Scraping can yield perfect results in the form of high-end valuable data.
Equity Research
Equity research was limited in the beginning days to only financial statements of business company’s investing in the stock. Now the trends have changed with new items being brought up each day. It has now become important to identify the right path of investment and take part in the current setup. This is where web scraping does its magic and fetches all important data aggregation which is every relatable to the investment market and business needs.
Application of Web Crawling
Have you ever imagined! Without the web crawling or crawler, there would have been no Google giving us so much information which we need to carry out our day-to-day tasks more efficiently and effortlessly. It is estimated that Google alone crawls up to 25 Billion pages per day.
Web crawlers can access almost thousands or millions of web pages at a time. To search and generate more desired results web crawlers are made to adapt as well.
Simple or complex web-based crawlers sort through the web pages and get access to quality data and perform indexing for better search results.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
