
How to scrape Amazon using Python?
How do you define web scraping?
Web scraping, also known as Web Content Extract, is a method of extracting vast data from websites and saving it in a suitable format.
Why do we scrape the web?
Web scraping is a popular method in the marketing industry as businesses use scraping data from competitors’ websites to gather details, such as price or articles, or new sales items, to develop the latest strategy to help them improve their offerings and earn profits. Web scraping can include but is not restricted to the market.
What are the advantages of data scraping?
The world is rapidly becoming digital, which means more data available for companies to study. Data scraping is an excellent method of obtaining details. It is a method of collecting information via the Internet and then putting the information into one central area to be analyzed. Data scraping offers many benefits, which make it a desirable alternative in the current digital age.
Time Efficient
The primary benefit of Data Scraping is that it’s efficient in time. For instance, downloading gigabytes worth of data could take many hours, and then looking at it by hand, one row at a time, is worth the time you spend for a whole month. However, with data scraping, you can let your computer complete all these manual tasks in a matter of seconds, meaning you’ll have more time to accomplish what you want.
Complete Automation
Many scraping and data mining services are now automated because of Big Data Analytics and Machine Learning. While humans can benefit in specific tasks using brute force, running an algorithm over a vast amount of data is much faster and more efficient than having someone scan through every document one at a time.
The advantages of automation are that it isn’t tiring or boring and doesn’t require breaks to drink or eat, and doesn’t get distracted. Data scrapers do not require special abilities; they follow instructions.
Cost Efficiency
Data scraping is cost-effective as it’s much less expensive than hiring a professional to complete the same task. This is especially true for companies that need regular access to this information since they’ll reduce time and money by performing the entire process themselves.
Data scraping is an affordable method to collect information. You can use the Internet to scrape at no cost or employ paid software that helps you locate data quickly. It’s worth it when you save around $50 per hour compared to manual research methods.
Doesn’t affect the user experience
One benefit of scraping information is it creates no problems in the event of an error-related timeout issue on your website or server. The site will not suffer from any delay in loading time, mainly because it does not have human interaction with users.
Data Accuracy
There are no human beings involved in web management or data extraction processes. Data scraping is a method to extract information from different websites and remove information for various uses. It assists users in understanding the report and its context to make better decisions based on the insights.
Limitation of web scraping
Web scraping certainly brings benefits for us. It’s fast, affordable, and can gather information from websites with a precision of 90% or more. It eliminates the need to copy-and-paste of chaotic layouts. But something could be missed. There are dangers and limitations in web scraping.
Websites’ structures change frequently
The data scraping is organized according to the layout of the site. You may go back to a site, and you will see the layout altered. Designers regularly update sites to improve the user experience or be doing so to prevent scraping. It could be as minor as a change in the position of an icon or radical changes to the overall layout. A slight change could cause data loss. Since the crawlers are constructed based on the previous site, you must adjust your crawlers every couple of weeks for accurate information.
It’s more complicated to handle complicated websites
Another technical problem. If you look at web scraping as a whole, most sites are simple to scrape, while 30 percent are moderate, and the remaining 20% are difficult to scrape. Specific scraping tools are made to collect data from simple websites using numbers for navigation. However, nowadays, more and more and more websites are beginning to use dynamic elements like AJAX. The most popular sites, such as Twitter, use infinite scrolling, and some websites require users to click the “load” and “load more” buttons to continue loading content. In this instance, users will need an improved scraping tool.
Learn curve
Even the most basic scraper takes some time and effort to learn. Specific tools, such as Apify, require some knowledge of programming to operate. Specific tools that are not coder-friendly may require a long time to master. Knowing XPath, HTML, and AJAX is essential to scrape websites successfully. The most efficient method to scrape websites is to utilize pre-built templates for web scraping to extract information with a couple of clicks.
Getting data at an enormous scale is much more difficult
Specific software tools cannot pull millions of records because they can only handle tiny scraping. This can cause problems for eCommerce entrepreneurs who require thousands of rows of daily data feeds directly into their databases. Cloud-based scrapers, such as Octoparse and Web Scraper, perform well regarding large-scale data extraction. Tasks run on multiple cloud servers, and you can enjoy fast speeds and massive data storage capacity.
How to scrape Amazon using Python?
Here’s how to scrape Amazon product information from Amazon product pages.
Markup data fields that need to be scraped with Selectorlib.
Copy and execute the code
Set up your computer to work with Amazon Scraping
We will be using Python 3 for this Amazon scraper. The program will not work in the case of Python 2.7. To begin, you’ll require an operating system that supports Python 3 and PIP installed on it.
Packages to be installed to enable Amazon scraping
Python Requests, for making requests and downloading the HTML contents of Amazon product pages.
SelectorLib Python program to extract information using the YAML file that we have created using the web pages we download.
Utilizing pip3,
pip3 install requests requests selectorlib
Scrape the product’s details off Amazon Product Page
It is the Amazon Product Page. Scraper scrapes the following information from the page of the product.
Product Name
Price
Short Description
Full Product Description
Image URLs
Rating
Number of Reviews
Variant ASINs
Sales Rank
Link to all Reviews Page
Markup the fields of data by using Selectorlib
| name: | |
| css: ‘#productTitle’ | |
| type: Text | |
| price: | |
| css: ‘#price_inside_buybox’ | |
| type: Text | |
| short_description: | |
| css: ‘#featurebullets_feature_div’ | |
| type: Text | |
| images: | |
| css: ‘.imgTagWrapper img’ | |
| type: Attribute | |
| attribute: data-a-dynamic-image | |
| rating: | |
| css: span.arp-rating-out-of-text | |
| type: Text | |
| number_of_reviews: | |
| css: ‘a.a-link-normal h2’ | |
| type: Text | |
| variants: | |
| css: ‘form.a-section li’ | |
| multiple: true | |
| type: Text | |
| children: | |
| name: | |
| css: “” | |
| type: Attribute | |
| attribute: title | |
| asin: | |
| css: “” | |
| type: Attribute | |
| attribute: data-defaultasin | |
| product_description: | |
| css: ‘#productDescription’ | |
| type: Text | |
| sales_rank: | |
| css: ‘li#SalesRank’ | |
| type: Text | |
| link_to_all_reviews: | |
| css: ‘div.card-padding a.a-link-emphasis’ | |
| type: Link |
Let’s save this code as the file selectors.yml in the same directory in which we have our code.
name:
css: ‘#productTitle’
type: Text
price:
css: ‘#price_inside_buybox’
type: Text
short_description:
css: ‘#featurebullets_feature_div’
type: Text
images:
css: ‘.imgTagWrapper img’
type: Attribute
attribute: data-a-dynamic-image
rating:
css: span.arp-rating-out-of-text
type: Text
number_of_reviews:
css: ‘a.a-link-normal h2’
type: Text
variants:
css: ‘form.a-section li’
multiple: true
type: Text
children:
name:
css: “”
type: Attribute
attribute: title
asin:
css: “”
type: Attribute
attribute: data-defaultasin
product_description:
css: ‘#productDescription’
type: Text
sales_rank:
css: ‘li#SalesRank’
type: Text
link_to_all_reviews:
css: ‘div.card-padding a.a-link-emphasis’
type: Link
Here’s a preview of the markup.
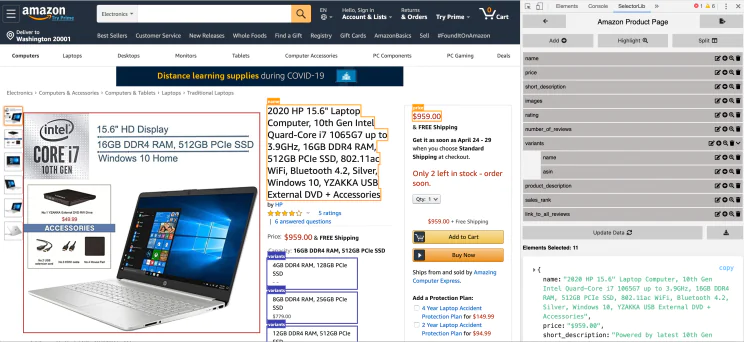
Selectorlib is a collection of tools designed for developers that allow making marking up and extracting data from web pages simple. Its Selectorlib Chrome Extension lets you mark the data you want to remove and generates an array of CSS Selectors or XPaths needed to extract the data; then, it shows what the data will look like.
The Code
Create a folder named amazon-scraper. Copy and paste your selectorlib template file in the form of selectors.yml.
Let’s make a file named amazon.py and paste the following code into it.
- Read the listing of Amazon Product URLs from a file known as urls.txt
- Scrape the data
- Save the data in a JSON Lines file
- from selectorlib import Extractor
- import requests
- import json
- from time import sleep
- # Create an Extractor by reading from the YAML file
- e = Extractor.from_yaml_file(‘selectors.yml’)
- def scrape(url):
- headers = {
- ‘authority’: ‘www.amazon.com’,
- ‘pragma’: ‘no-cache’,
- ‘cache-control’: ‘no-cache’,
- ‘dnt’: ‘1’,
- ‘upgrade-insecure-requests’: ‘1’,
- ‘user-agent’: ‘Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36’,
- ‘accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9’,
- ‘sec-fetch-site’: ‘none’,
- ‘sec-fetch-mode’: ‘navigate’,
- ‘sec-fetch-dest’: ‘document’,
- ‘accept-language’: ‘en-GB,en-US;q=0.9,en;q=0.8’,
- }
- # Download the page using requests
- print(“Downloading %s”%url)
- r = requests.get(url, headers=headers)
- # Simple check to check if page was blocked (Usually 503)
- if r.status_code > 500:
- if “To discuss automated access to Amazon data please contact” in r.text:
- print(“Page %s was blocked by Amazon. Please try using better proxies\n”%url)
- else:
- print(“Page %s must have been blocked by Amazon as the status code was %d”%(url,r.status_code))
- return None
- # Pass the HTML of the page and create
- return e.extract(r.text)
- # product_data = []
- with open(“urls.txt”,’r’) as urllist, open(‘output.jsonl’,’w’) as outfile:
- for url in urllist.readlines():
- data = scrape(url)
- if data:
- json.dump(data,outfile)
- outfile.write(“\n”)
- # sleep(5)
Running the Amazon Product Page Scraper
Start your scraper by entering the following command:
python3 amazon.py
After completing the scrape, you will see the file output.jsonl with your information. Here’s an example of the URL.
{
“name”: “2020 HP 15.6\” Laptop Computer, 10th Gen Intel Quard-Core i7 1065G7 up to 3.9GHz, 16GB DDR4 RAM, 512GB PCIe SSD, 802.11ac WiFi, Bluetooth 4.2, Silver, Windows 10, YZAKKA USB External DVD + Accessories”,
“price”: “$959.00”,
“short_description”: “Powered by latest 10th Gen Intel Core i7-1065G7 Processor @ 1.30GHz (4 Cores, 8M Cache, up to 3.90 GHz); Ultra-low-voltage platform. Quad-core, eight-way processing provides maximum high-efficiency power to go.\n15.6\” diagonal HD SVA BrightView micro-edge WLED-backlit, 220 nits, 45% NTSC (1366 x 768) Display; Intel Iris Plus Graphics\n16GB 2666MHz DDR4 Memory for full-power multitasking; 512GB Solid State Drive (PCI-e), Save files fast and store more data. With massive amounts of storage and advanced communication power, PCI-e SSDs are great for major gaming applications, multiple servers, daily backups, and more.\nRealtek RTL8821CE 802.11b/g/n/ac (1×1) Wi-Fi and Bluetooth 4.2 Combo; 1 USB 3.1 Gen 1 Type-C (Data Transfer Only, 5 Gb/s signaling rate); 2 USB 3.1 Gen 1 Type-A (Data Transfer Only); 1 AC smart pin; 1 HDMI 1.4b; 1 headphone/microphone combo\nWindows 10 Home, 64-bit, English; Natural silver; YZAKKA USB External DVD drive + USB extension cord 6ft, HDMI cable 6ft and Mouse Pad\n› See more product details”,
“images”: “{\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX425_.jpg\”:[425,425],\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX466_.jpg\”:[466,466],\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SY355_.jpg\”:[355,355],\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX569_.jpg\”:[569,569],\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SY450_.jpg\”:[450,450],\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX679_.jpg\”:[679,679],\”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX522_.jpg\”:[522,522]}”,
“variants”: [
{
“name”: “Click to select 4GB DDR4 RAM, 128GB PCIe SSD”,
“asin”: “B01MCZ4LH1”
},
{
“name”: “Click to select 8GB DDR4 RAM, 256GB PCIe SSD”,
“asin”: “B08537NR9D”
},
{
“name”: “Click to select 12GB DDR4 RAM, 512GB PCIe SSD”,
“asin”: “B08537ZDYH”
},
{
“name”: “Click to select 16GB DDR4 RAM, 512GB PCIe SSD”,
“asin”: “B085383P7M”
},
{
“name”: “Click to select 20GB DDR4 RAM, 1TB PCIe SSD”,
“asin”: “B08537NDVZ”
}
],
“product_description”: “Capacity:16GB DDR4 RAM, 512GB PCIe SSD\n\nProcessor\n\n Intel Core i7-1065G7 (1.3 GHz base frequency, up to 3.9 GHz with Intel Turbo Boost Technology, 8 MB cache, 4 cores)\n\nChipset\n\n Intel Integrated SoC\n\nMemory\n\n 16GB DDR4-2666 SDRAM\n\nVideo graphics\n\n Intel Iris Plus Graphics\n\nHard drive\n\n 512GB PCIe NVMe M.2 SSD\n\nDisplay\n\n 15.6\” diagonal HD SVA BrightView micro-edge WLED-backlit, 220 nits, 45% NTSC (1366 x 768)\n\nWireless connectivity\n\n Realtek RTL8821CE 802.11b/g/n/ac (1×1) Wi-Fi and Bluetooth 4.2 Combo\n\nExpansion slots\n\n 1 multi-format SD media card reader\n\nExternal ports\n\n 1 USB 3.1 Gen 1 Type-C (Data Transfer Only, 5 Gb/s signaling rate); 2 USB 3.1 Gen 1 Type-A (Data Transfer Only); 1 AC smart pin; 1 HDMI 1.4b; 1 headphone/microphone combo\n\nMinimum dimensions (W x D x H)\n\n 9.53 x 14.11 x 0.70 in\n\nWeight\n\n 3.75 lbs\n\nPower supply type\n\n 45 W Smart AC power adapter\n\nBattery type\n\n 3-cell, 41 Wh Li-ion\n\nBattery life mixed usage\n\n Up to 11 hours and 30 minutes\n\n Video Playback Battery life\n\n Up to 10 hours\n\nWebcam\n\n HP TrueVision HD Camera with integrated dual array digital microphone\n\nAudio features\n\n Dual speakers\n\nOperating system\n\n Windows 10 Home 64\n\nAccessories\n\n YZAKKA USB External DVD drive + USB extension cord 6ft, HDMI cable 6ft and Mouse Pad”,
“link_to_all_reviews”: “https://www.amazon.com/HP-Computer-Quard-Core-Bluetooth-Accessories/product-reviews/B085383P7M/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews”
}
Scrape Amazon products from the Search Results Page
This Amazon Search result scraper scrapes the following information from results pages.
- Product Name
- Price
- URL
- Rating
- Number of Reviews
The procedure and code to scrape search results are similar to the page scraper.
Markup the fields of data by using Selectorlib
Here’s our selectorlib yml file. Let’s call it search_results.yml
products:
css: ‘div[data-component-type=”s-search-result”]’
xpath: null
multiple: true
type: Text
children:
title:
css: ‘h2 a.a-link-normal.a-text-normal’
xpath: null
type: Text
url:
css: ‘h2 a.a-link-normal.a-text-normal’
xpath: null
type: Link
rating:
css: ‘div.a-row.a-size-small span:nth-of-type(1)’
xpath: null
type: Attribute
attribute: aria-label
reviews:
css: ‘div.a-row.a-size-small span:nth-of-type(2)’
xpath: null
type: Attribute
attribute: aria-label
price:
css: ‘span.a-price:nth-of-type(1) span.a-offscreen’
xpath: null
type: Text
The Code
The code is similar to the scraper we used previously, but we loop through each item and save them on distinct lines.
Create an image file called searchresults.py and paste the below code into it. This is how the code does.
- Open a file called search_results_urls.txt and read the search result page URLs
- Scrape the data
- Save to a JSON Lines file called search_results_output.jsonl
from selectorlib import Extractor
import requests
import json
from time import sleep
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file(‘search_results.yml’)
def scrape(url):
headers = {
‘dnt’: ‘1’,
‘upgrade-insecure-requests’: ‘1’,
‘user-agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36’,
‘accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9’,
‘sec-fetch-site’: ‘same-origin’,
‘sec-fetch-mode’: ‘navigate’,
‘sec-fetch-user’: ‘?1’,
‘sec-fetch-dest’: ‘document’,
‘referer’: ‘https://www.amazon.com/’,
‘accept-language’: ‘en-GB,en-US;q=0.9,en;q=0.8’,
}
# Download the page using requests
print(“Downloading %s”%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if “To discuss automated access to Amazon data please contact” in r.text:
print(“Page %s was blocked by Amazon. Please try using better proxies\n”%url)
else:
print(“Page %s must have been blocked by Amazon as the status code was %d”%(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
# product_data = []
with open(“search_results_urls.txt”,’r’) as urllist, open(‘search_results_output.jsonl’,’w’) as outfile:
for url in urllist.read().splitlines():
data = scrape(url)
if data:
for product in data[‘products’]:
product[‘search_url’] = url
print(“Saving Product: %s”%product[‘title’])
json.dump(product,outfile)
outfile.write(“\n”)
# sleep(5)
Running the Amazon Scraper to Scrape Search Result
Start your scraper by entering the following command:
python3 searchresults.py
Once the scrape is complete, you should see a file called search_results_output.jsonl with your data.
Conclusion
Many businesses now depend upon Data scraping technologies or services to gather market analysis. Data scraping is now an essential tool for collecting data from numerous websites. Because of Big Data analytics, data can be compiled into one spreadsheet, which is easy to use and access. Data scrapers can locate up-to-date data online and are much more helpful than others.
In this article, we’ll learn how to extract data from Amazon using Python. I hope that this article has helped you in the right direction.
