How to scrape data from Wikipedia?
Everyone is trying to be innovative and utilize modern technologies in the current fast-paced world. If you’re searching for an automated solution to collect structured web-based data, web scraping, also called web data extraction or data scraping offers the solution.
What is web scraping?
The process of extracting data automatically from websites onto your computer or to a database is called web scraping. The laborious process of manually copying and pasting data from websites is automated with web scraping software that scans many pages on a website.
What are the advantages of web scraping?
There are many applications for data extraction on the web, which is commonly referred to as scraping data. You can quickly and efficiently make it easier to automate information extracted from different websites through the help of data scraping software. Furthermore, it will ensure that the data you’ve collected is organized correctly and is easy to analyze and use for other tasks.
Scraping data from websites is typically employed to track competitor prices in the e-commerce industry. It’s the sole method for businesses to analyze the cost of the products and services provided by rival companies, allowing them to alter their pricing practices and gain an advantage over their competitors. Manufacturers can also use it to ensure retailers comply with the guidelines regarding pricing their products. By keeping track of online reviews, news articles, and customer feedback, analysts and market research firms depend on web scrapers to extract data for evaluating customers’ opinions.
There are other uses for data extraction from web pages. For journalism, SEO monitors, competitive analysis and monitoring lead generation, risk management, academic research, real estate, and many other areas, Web scraping is often used.
Wikipedia and Web Scraping
Wikipedia will be, without a doubt, among the most comprehensive sources on the internet for any information. It houses a variety of information, from vast topics like technology, science, politics, and even history, to the more common knowledge.
The most appealing aspect is that Wikipedia gives all the information you need for free. You can download the complete Wikipedia database if you’d like. It’s not much more than this. However, you may need help to download the complete database and article. You may want to extract information from Wikipedia in a more user-friendly format, for instance, the Excel spreadsheet.
This is where web scraping can aid.
With the aid of web scrapers, selecting the particular information you want to extract from an article to an Excel spreadsheet is possible. You can download only some of the articles.
Going one more advanced step, you could create an internet scraper to collect specific details from one article and later take the same information from various articles.
To show this, we’ll create a web scraper to collect the standings for each Premier League season from Wikipedia.
We’ll also use ParseHub, a no-cost and effective web scraper that will enable us to finish this task.
What is ParseHub?
Parsehub is an internet scraper that focuses on ease of use. It lets users collect information on all JavaScript or Ajax websites. Users can browse by using forms or open dropdowns and login to websites, use the map feature and manage websites that have infinite scrolling, tabs, and pop-ups that scrape data. The data can be gathered without any programming as the program relies on machine learning to comprehend the order of the components. Users must install their desktop application and select the website to collect data. You can also choose information from several pages with simple clicks and interact with AJAX forms, dropdowns, forms, or other. Then, they can download or download results using JSON, Excel, and API. The system is cloud-based and utilizes multiple proxy servers while crawling the web. Users can also plan data collection tasks and use regular expressions too.
Scraping a Wikipedia Article
Before beginning, we’ll have to follow the steps below.
Get your URL for the piece of content that you’ll scrape first. In this instance, we’ll start with the article from the initial game in the Premier League in 1992-1993.
Then, we’ll download and install ParseHub free in order to scrape the information we’d like.
With ParseHub in place, fully operational, and ready to go, we can begin our project.
1 In ParseHub, click on New Project and submit the URL you want to scrape. ParseHub will then render the page in the application.
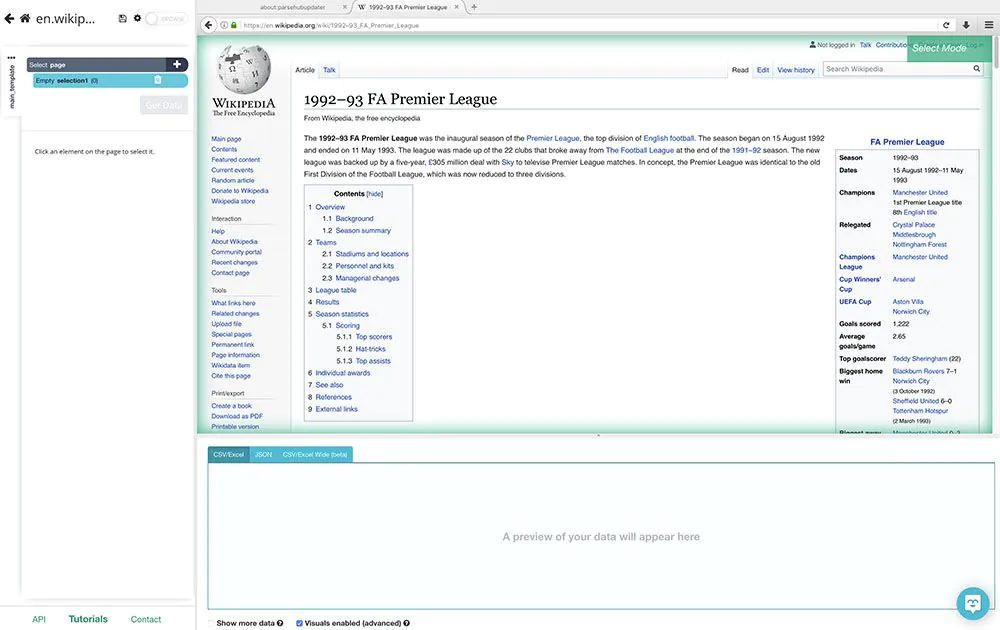
2 Our first pick would be the squads that play every season, along with their scores. Click on the League Table section of the article, then click on the team that is the first in the table (in this instance, Manchester United).
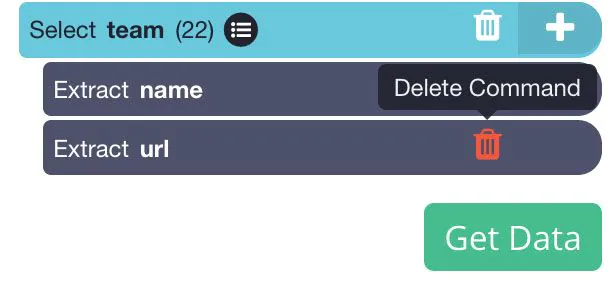
3 The team’s name will change to green to signal that it was selected. The remaining team’s names are highlighted in Yellow. Select the second option in this list (in this instance, Aston Villa) to pick them all.
4 In the left-hand sidebar, change the name of your new selection to the team. It will be apparent that ParseHub is removing the team’s name along with the URLs of their respective articles. In this instance, we’ll remove the URL of the article since we don’t require it. You can do this by clicking the trash bin next after the removal.
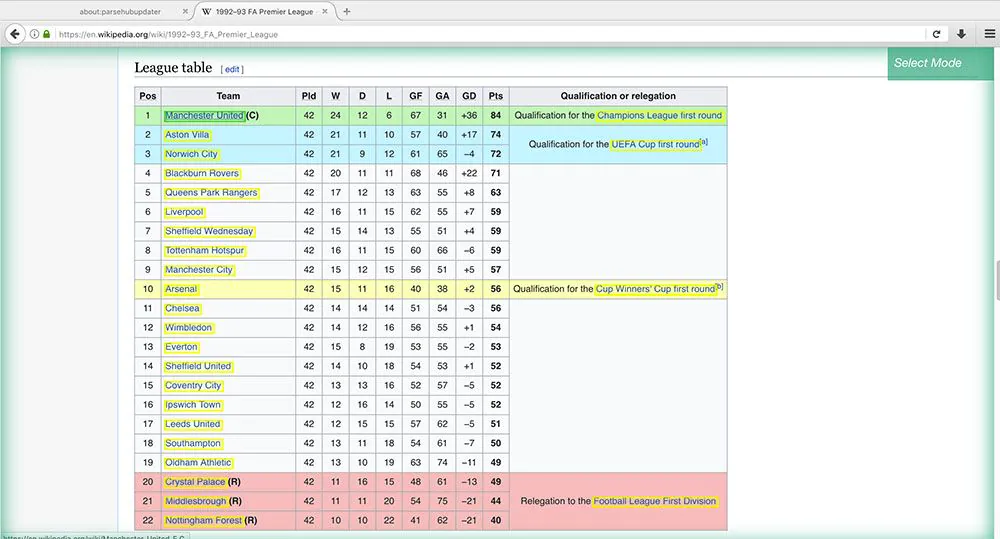
5 We will now extract each column from the table. (Note the tables on every page of Premier League Wikipedia articles are constructed in the exact method. If tables on every page were different, it could damage any scrape.)
6 Begin by clicking the PUS(+) sign beside your team’s choice and then select the Relative Select option.

7 Using the Relative Select command, Click on your name on the initial team, then click on the number right next to the name. In this instance, it’s the number of games played. An arrow will be visible to show the affiliation you’ve created.
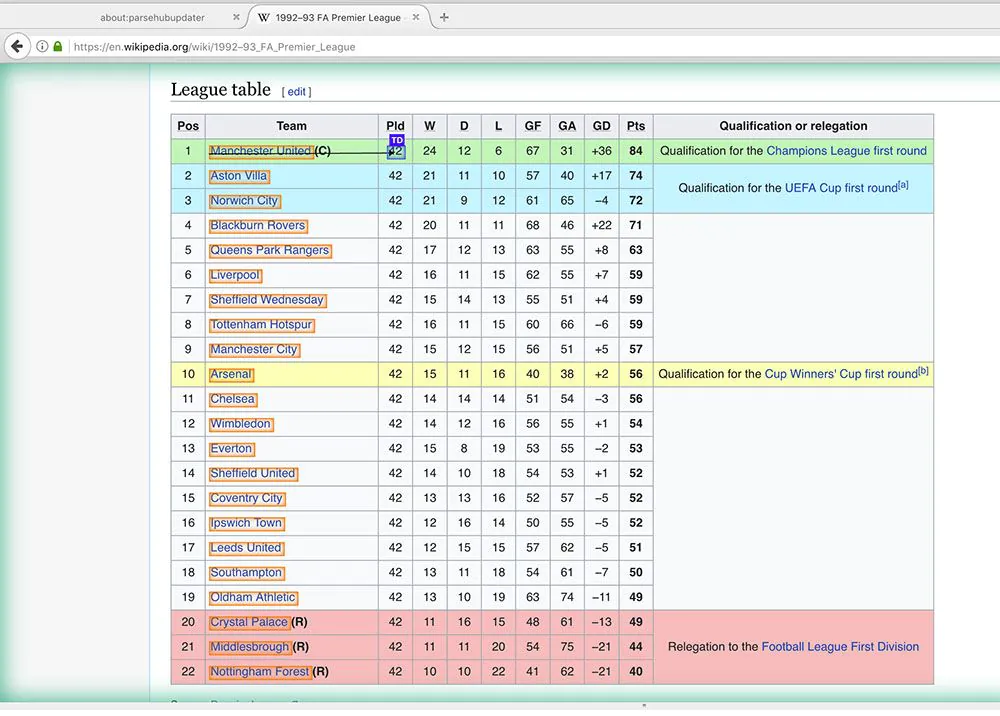
8: Change the name of your selection to the played.
9: Repeat steps 6-8 to get data for every column in this table (except for the “Qualification or Relegation” column and) the “Qualification or Relegation” column). Be sure to name your choices accordingly.
10: Then, you can create a final Relative Select option under the team selection. Click on the team that is first on the table, and then click to select the name of the whole article (in this instance, “1993-94 FA Premier League”). Name this team in the season. This will enable us to identify which season the information we have extracted comes from.
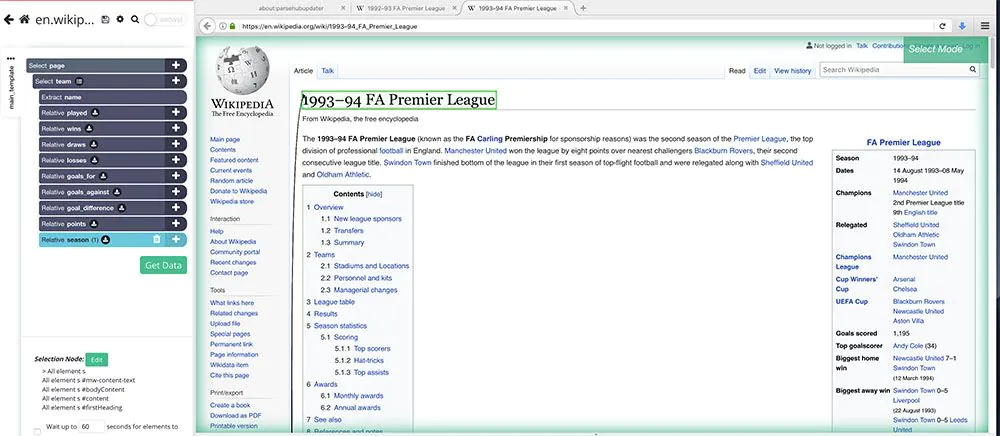
Working with Paginated Articles
We’ll now instruct ParseHub to use the same information for each team season. Luckily, this is simple to set up.
Begin by clicking the PLUS(+) sign on the page selection and then select the option Select.
Utilizing the select command, look for that link in the article chronologically and click the link.
In this instance, it is located in the lower part of the information box at the top of the text.
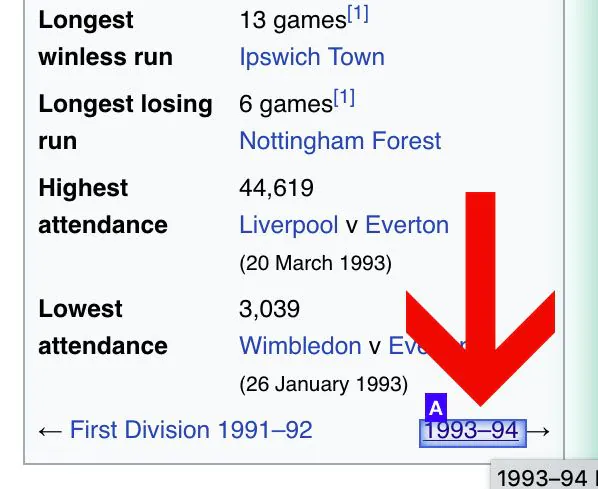
Change the name of your new selection to the next. Expand it by clicking the icon beside it and then remove the extract commands.
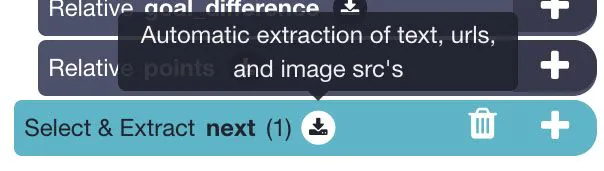
Use the PLUS(+) sign next to the next option and click the button.
A pop-up asks you if this is a “next page” link. Enter Yes and how many times you’d prefer to repeat the procedure. In this instance, we’ll repeat the process 26 times. Click the “Repeat Current Template” button to confirm.
Running your scrape
You’re now prepared to start your Scrape. In the sidebar on your left, press the “green “Get Data” button.
Here is where you can run your Scrape, try it, or schedule it for future times.
Tip for the Pro: It is recommended to run a test on your scrapes before running them for larger scrape jobs. In this instance, we’ll start running it immediately.
ParseHub will begin to collect all the information you’ve chosen and will notify you once the Scrape is completed. Then, you’ll be able to download the data in the format of an Excel worksheet and a JSON file.
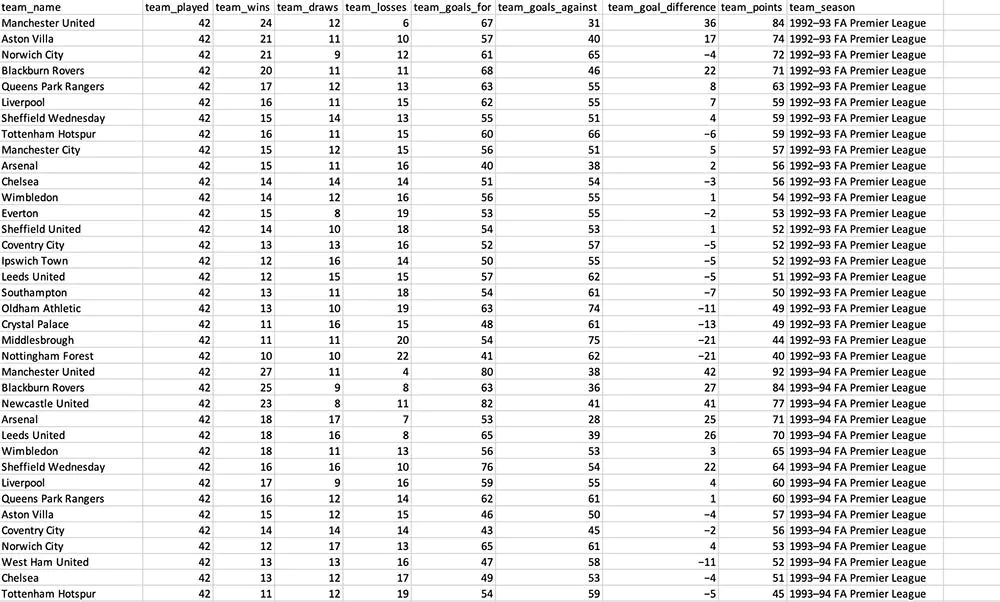
So here you are! You’re now allowed to utilize your collected data to analyze further.
Final words
The entire world’s information, whether it’s media, text, or different kinds, is stored on the internet. Data are displayed in some way or another on every web page. The performance of the majority of businesses globally today relies on accessing this information. Unfortunately, the majority of these data are not available. The majority of websites do not offer the option to save the data they show to your local computer or on a site that is your own. In this case, web scraping can help you immensely. Web scraping is a vast field of applications that can be used for both professional and personal requirements. Each person or company needs data collection.
In this tutorial, we showed you ways to get data scraped from Wikipedia with the help of ParseHub. We hope that this guide has helped you to collect data using Wikipedia.
