
How To Scrape Amazon Best Seller List Using Python?
By writing only a few lines of Python, you can develop your web scraping tools to help monitor stores for better product analysis. I think this is quite plausible that we all have a bookmarked product page from the best-selling platform ‘Amazon’, which we frantically looked at times and again hoping for the price to go down. This blog is especially to enable you to write a simple yet effective Python script that you can use to achieve your Amazon product data objectives. We begin by following the below-mentioned set of rules:
Begin by creating a CSV file with product links included along with product price.
Now we need to write a Beautiful Soup function that can cycle past the links into the CSV file and can access all the information about the products.
After this, it is essential to store the information in a secure database to keep track of the product prices over passing time. This proves helpful in assessing the historical trend.
Now you need to schedule the script to run at selected instances during the day.
You can also create an email alert whenever the prices are dropped as per your limit.
Getting Started:
If you need to scrape the prices from different house listings, In this case, your favorite tool is going to be Beautiful Soup. With the help of Beautiful Soup, you can easily access specific tags via an HTML page.
TRACKER_PRODUCTS.csv consists of the product links which you want to stalk. After running the code script you can save your data results in a differently named file such as ‘search_history_(date).xlsx’.
This proves to be a good time to get our CSV file named TRACKER_PRODUCTS.csv and place it in the ‘trackers’ folder from the repository. After this, we can run the file through Beautiful Soup. This can help tame the HTML to make it even more accessible. We can name it ‘soup’.
Which Ingredients Should We Pick?
When you come across soup.find, it simply means that you are trying to locate an element using an HTML tag such as span or div, etc. Attributes can also be included in these elements just like name, class, and id. In association with soup.selectors we need to use CSS selectors. Inspect feature can also be used in its place to support your browser and to navigate the page. Chrome extension called SelectorGadget can come in quite handy for this purpose, as it can safely guide you towards the right HTML codes.
De-constructing The Soup

Following the code, getting the accurate product title can become a piece of cake. However, the price portion can be a bit challenging to obtain but it can also be accomplished by adding a two to three-liner code at the end. In the final version of the script, you can find that there is an addition to the code to get to the functionality of the prices in USD.

Increasing trying out every time is a testing part of a web scraper. Every professional can face this situation to write and test a web scraper for the same choice. The idea is to get the exact piece of HTML that is capable to get the right part of the page every time. Web Scraping Tools provide us with different advanced features with which we can access the target HTML page for data within less time.

Script in Action
Getting access to all the individual ingredients is quite simple as perfectly portrayed in the attached images. After testing, it is now time to write down a script (proper) which can:
Access URLs from the CSV file.
Use a loop to scrape every product detail and store the product data within a suitable format.
All previous results collected must also be included in the excel file.
To write the script you need a code editor, you can also use any code editor if you want, For this reason, Spyder version 4 is quite useful. You can now create a new file by calling it Amazon_Scraper.py.
Tracker Products
Here are a few things which need to be kept in mind about the TRACKER_PRODUCTS.csv file. It is very simple to access and consists of three columns mainly: URL, buy_below, and code. Here is where you must be adding your product URLs to monitor the price listings.
Search History
The same instruction goes for the SEARCH_HISTORY file. For the very first run, you should be adding an empty file into the repository to the search_history. You must map the folder inside the search history in line 116 of the script. You can easily replace the text in the folder just like Amazon Scraper in the given example.
Price Alert
In the above-mentioned script, line 97 includes a section where you can send an email with an alert if the price drops lower than your set limit. This will happen each time the price hits the target value.
Setting Up A Scheduled Task To Run The Script
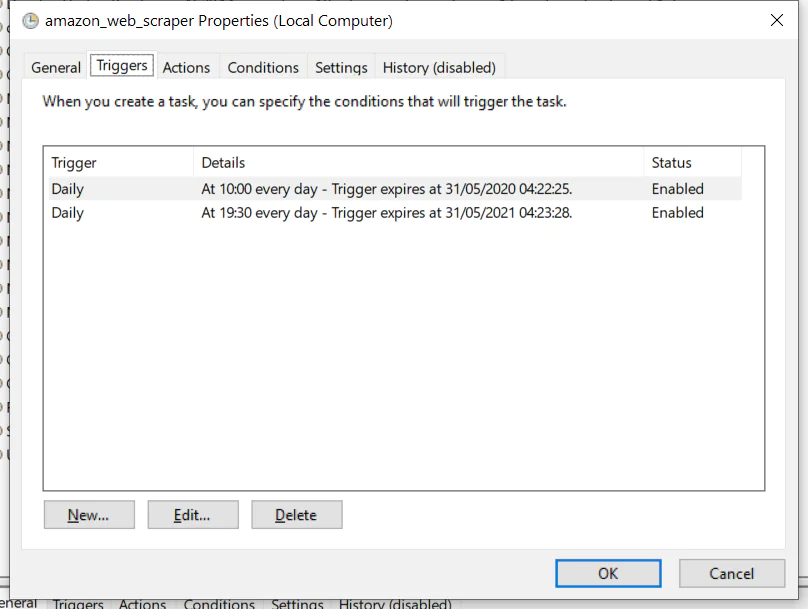
To execute the given script, it is required to set up an automated task. You can schedule a task by following the below-mentioned steps one by one:
You must begin with opening the ‘Task Scheduler’. It can be done with a simple press on the window key and by typing it. You may then chose the option ‘Create Task’ afterward select the ‘Triggers’ tab. Mine run at 10hoo and 19h30 each day every day.
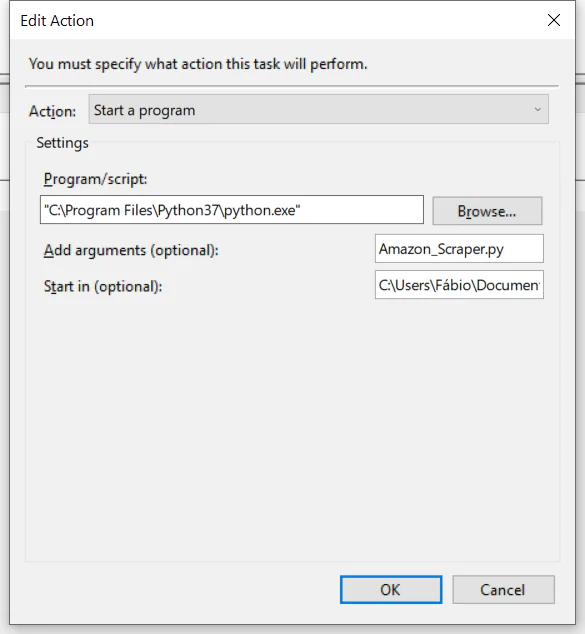
In this next step, you can move forward to the action tab. In this section, you can add an action by picking the location of your Python folder for the ‘Script/Program’ box. Mine is located within the program files directory (look at the above image for your reference).
Within the argument box, you can easily type in your file name with its function.
By doing this, we tell our system to begin with the inserted command action in the file where the Amazon_Scraper.py file is placed.
From right here the task is ready to run. With this, you can explore many new options to test run the script and make it work for your better business. This is the most basic method to schedule your script, a script that can run automatically with a Window-based task scheduler.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
