
How To Create A Web Crawler Using Python?
To create a web crawler you must be aware of what a web crawler is, its types, and what it is meant for. This blog essentially focuses on bringing closer your questions and our answers for the development of an effective web crawler using Python. Every bit of information that we want in our daily routine or business can be achieved through web scarping using web crawlers from Internet sources. Web extraction is an incredibly growing technique for the fulfillment of data desires. Let us unravel all the basic notions of web scraping and web crawlers firstly.
Demystifying Both ‘Web Scraper’ and ‘Web Crawler’ Terms
Web Scraping is entirely a systematic and technical way of extracting intended data from the website. The data can be any type and about anything, you so ever can think about. Like for instance, one needs to scrape prices from popular retail websites, To do so, we can design a customized scraper to pull out information from such websites say Amazon or eBay.
A web crawler also commonly announced as a ‘Spider’ is a more generic representation. It is a bot that works by scanning the Internet for pulling and indexing information. It locates internal links on the website and web pages. It can navigate or surf through all information for a defined objective. Hence, it is more exploratory. Popular Search Engines like Bing and Google and others often use web crawlers to search relative content on the web. Search Engines extract content for a specific URL or any other links.
Types of Web Crawlers
A web crawler consists of a code of a few verses. The program or code operates as a bot. The process is to index content on the intended website or web page on the Internet for gathering information. Web pages consist of Keywords and HTML structures. The only work that needs to be done is to enter the specific HTML tag category for the web crawler to look up for in the web page and scan all the relevant data available on the web page to your advantage.
There are various types of web crawlers.
Namely, General purpose web crawler, focussed web crawler, incremental web crawler, and deep web crawler. All such categories are defined and described in detail below:
1. General-Purpose Web Crawler
A General Purpose Web Crawler gathers as many web pages as it can for certain URLs to crawl a huge amount of data. The only thing you need is faster Internet access and large storage capacity. A general-purpose web crawler is commonly built to scrape a tremendous amount of data for web service providers and search engines.
2. Focussed Web Crawler
Focussed Web Crawler is identified as a certain focused topic. As it crawls web pages very selectively according to the pre-defined topics. Just like the product information on a specific eCommerce site can be crawled for relevant and useful data. Thus, you can efficiently run smaller storage spaces for data entry and safety. A slower speed Internet can also do the trick. Mostly, search engines like Yahoo, Google, and Baidu employ focused web crawlers for unique information gathering.
3. Incremental Web Crawler
Consider you have been surfing or crawling or extracting information from a certain page regularly. Now, you need to index and update the existing piece of information with the updated version of the site. Do you need to crawl the entire site for that? This seems humungous computational cost overruns. The best alternative to this is using an Incremental Web Crawler. It can get you only the updated version of the information available on the site. This not only saves the extra amount of computational cost but blesses you with more time and memory for more information.
4. Deep Web Crawler
Mostly the web pages on the Internet can be categorized into Deep Web and Surface Web. You can very easily index a surface page with any traditional web crawler you like. It is eventually a static web page whose information can be retrieved by using a hyperlink.
However, the real deal is to get the invisible web page crawled. All the information is hidden behind the search bars. Such information is highly secure and not be accessed without a certain suitable keyword. Just like there are web pages out there that only show themselves after you register there, Deep Crawlers help to crawl such web page information very quickly.
How can you build a Web Crawler from scratch?
There are significant open-source and certain paid subscriptions for customizing web crawlers. However, you can also devise one suiting your specific project data requirements. Python is a widely employed program and can be used in any language. Let us dive into the web crawler building mechanism via Python.
Building a Web Crawler using Python
Python is an efficient computational language. It is most deliberately used to build up competitive web crawlers and web scrapers to draw unique information from sources on the Internet. The most common action is ‘Scrapy’ in Python.
Use the below code to import Scrapy:
import scrapy
class spider1(scrapy.Spider):
name = ‘Wikipedia’
start_urls = [‘https://en.wikipedia.org/wiki/Battery_(electricity)’]
def parse(self, response):
pass
The class constitutes the following components:
- A ‘Name’ to identify the crawler (spider), Such as “Wikipedia”.
- A ‘Start_URLs’ will act as a variable for a list of URLs to begin the action of crawling. IT will serve as the starting point. Here we are specifying the URL for the “Wikipedia Page”, on Clustering of algorithms.
- A ‘Parse ()’ method to process the intended webpage to extract content.
You can also run the spider aka ‘Crawler’ to the command “scrappy runspider spider1.py”. The output must look something like this:
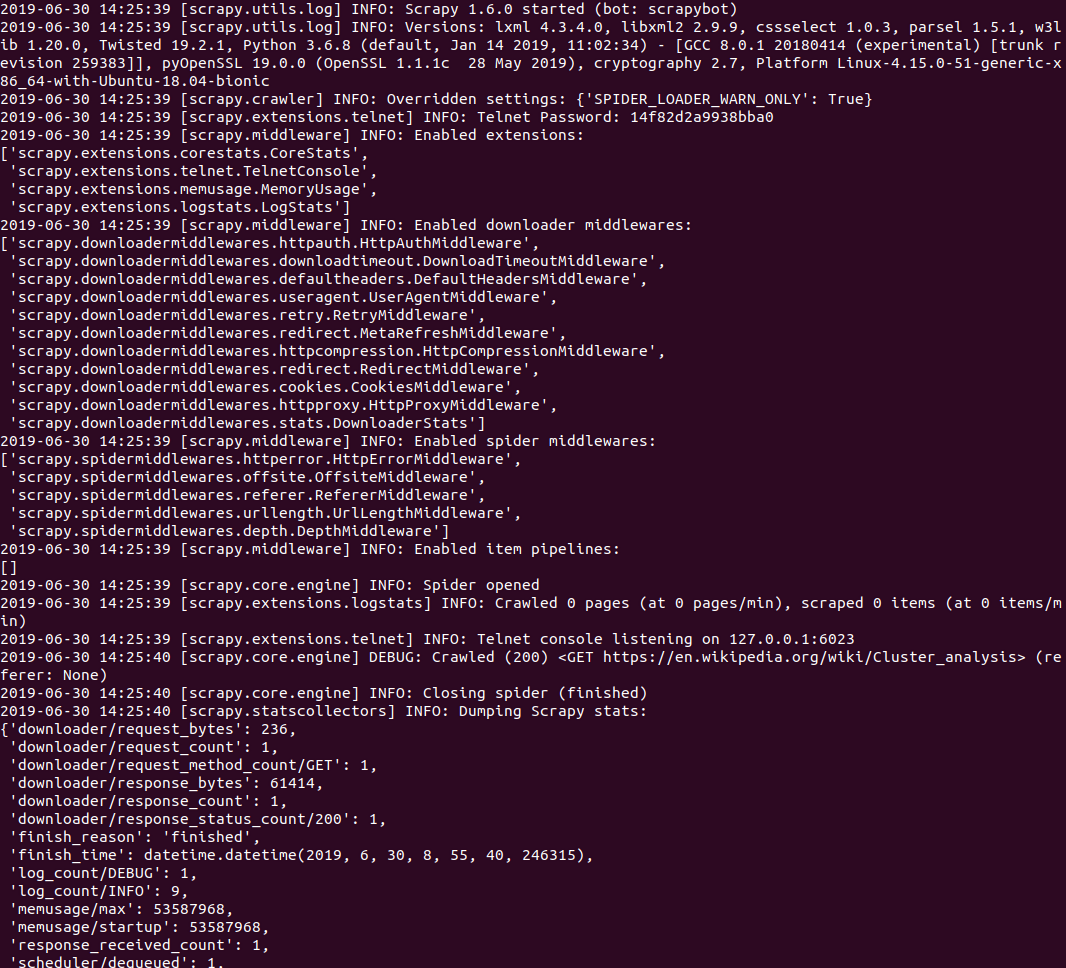
The output contains all the information including the links within the text in the form of a wrapped-up format. The use of a focussed web crawler to pull the product information must look like:
import requests
from bs4 import BeautifulSoup
def web(page,WebUrl):
if(page>0):
url = WebUrl
code = requests.get(url)
plain = code.text
s = BeautifulSoup(plain, “html.parser”)
for link in s.findAll(‘a’, {‘class’:’s-access-detail-page’}):
tet = link.get(‘title’)
print(tet)
tet_2 = link.get(‘href’)
print(tet_2)
web(1,’https://www.amazon.in/mobile-phones/b?ie=UTF8&node=1389401031&ref_=nav_shopall_sbc_mobcomp_all_mobiles’)
This snippet gives out the product information output in the following format:
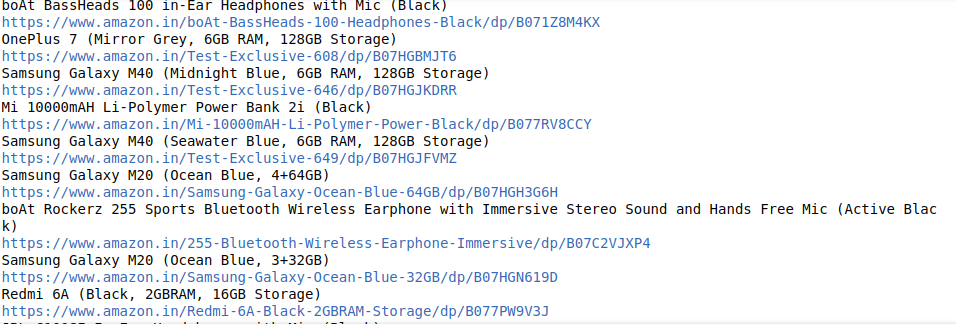
The output shows that all the product names and the product links have been enlisted properly. This is all on how you can smoothly extract your intended and relevant piece of information from any website’s web page using a customized web crawler.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are work upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
