How To Build A Web Crawler Using Python And Scrapy
For the automation of information extraction from different websites, building a web crawler can be one of the most effective strategies. It helps you in many ways, including extracting data related to product prices, news articles, or social media pages. To develop web crawlers, Python is an effective language that enables you to a versatile as well as simple procedures. When it comes to tool choice, Scrapy can be chosen as a powerful framework for developers who are looking to scrap vast data from sites. Web crawlers navigate through websites to fetch and extract data according to specific patterns. Rather than paying a manual visit to each web page, they operate in an automated way to instantly copy the needed information. This blog further includes the steps to build a web crawler using Python and Scrapy, making your vast data extraction quick and precise.
Step 1: Installing Scrapy
The primary step in building a web crawler with Scrapy is to introduce the Scrapy framework on your device. Scrapy could be a capable and quick web scraping system outlined for extricating information from websites in a organized way. It’s built on top of Python and presents a range of highlights that streamline the procedure of web crawling and information extraction.
For Scrapy installation, you need to install Python on your system. You can ensure this by operating the command python –version or python3 –version in your terminal. After successfully installing Python, Scrapy can be readily installed using the Python package manager, pip. Just open your terminal and run the below-given command:
pip install scrapy
That command will download and install Scrapy in conjunction with its dependencies, guaranteeing your system is prepared to run web crawlers. If you’re performing in a virtual environment, ensure to activate it before initiating with the installation command to keep your project dependencies separated.
After the installation process is completed, you can affirm Scrapy installation by inputting Scrapy within the terminal. If the installation was fruitful, you’ll see Scrapy’s accessible commands listed. You’re presently prepared to begin building your web crawler.
Step 2: Creating A New Scrapy Project
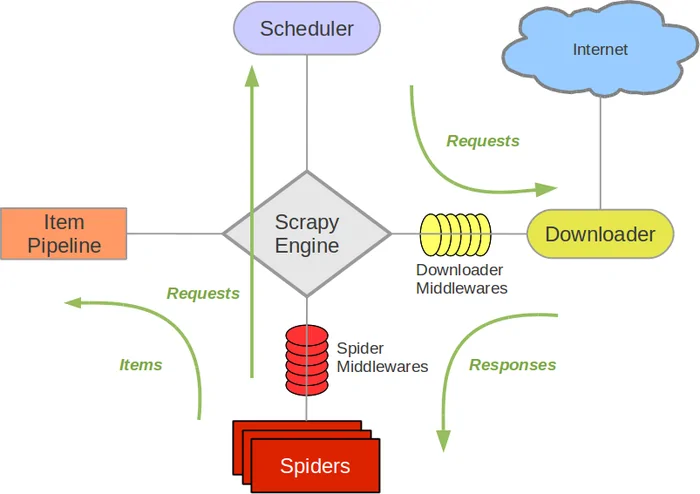
This step involves creating a new Scrapy project, which is basically a catalog structure that arranges the different components you will need to run a web crawler, like spiders, settings, and pipelines.
To make a new Scrapy project, open your terminal or command prompt and head to the directory where you need your project to reside. After within the wanted location, run the subsequent command:
scrapy startproject project_name
Replace project_name with the title you need for your project. Scrapy will yield a folder with this title, and inside that folder, you will find various substantial files and subdirectories, including:
The spiders where you’ll define your spiders. A spider could be a class used for fetching information from websites.
items.py is utilized for representing the structure of the data you need to scrape.
The pipelines.py file can be utilized to process the scraped information like saving it to a database.
Finally, settings.py contains settings that influence how Scrapy carries on during the crawling process.
This step is the standing point of your entire web crawler project. You’re now set to define your spiders and commence scraping websites.
Step 3: Defining The Spider
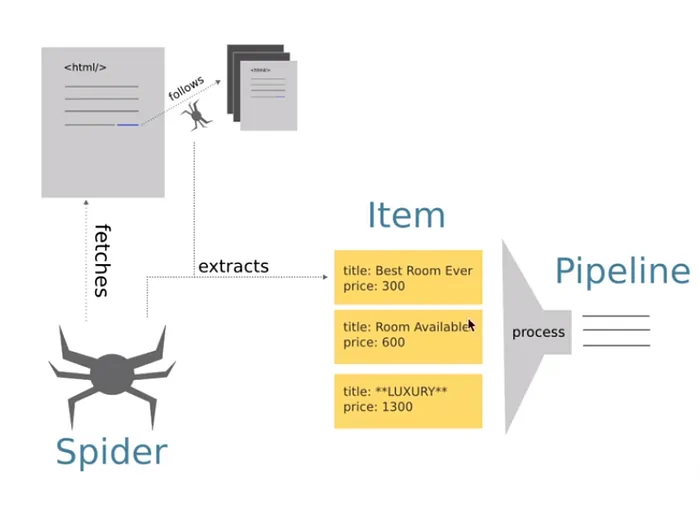
After your Scrapy project gets going, the next thing to do is to define the spider that will accomplish the actual web crawling. A spider comprises the logic for which websites to crawl, what data to extricate, and how to handle that data.
To make a new spider, head to the spiders folder inside your project catalog and make a new Python file. For instance, in case you need to crawl example.com, you might title the file example_spider.py. Inside that file, define a class that was acquired from Scrapy.Spider. Observe the following code:
import scrapy
class ExampleSpider(scrapy.Spider):
name = “example”
start_urls = [‘http://example.com’]
def parse(self, response):
# Parsing logic here
pass
In this code, “name” is usually a special identifier for the spider. It is utilized while running the spider. The “start_urls” is a list of URLs that the spider will start crawling. Scrapy sends requests to all of these URLs.
The “parse method” is typically where you define how the spider ought to handle the response from the site. You can extricate information utilizing Scrapy’s selectors, such as XPath or CSS selectors, and keep it in Python dictionaries, which Scrapy can afterward process or preserve.
This spider will begin crawling the desired URL(s) and parse the content concurring with your directions. You can alos customize the spider by including more rules or logic for following links for scraping numerous pages.
Step 4: Scraping The Content
Along with your spider defined, the next stage is to scrape the content you would like from the site. It includes extracting the pertinent data from the HTML content of the internet pages. Scrapy supplies robust tools to assist you in selecting and extracting information utilizing XPath or CSS selectors.
Within the parse method of your spider, you can utilize response—which includes the HTML of the page—and apply selection strategies to target particular components. Following is an example to demonstrate how you may scrape the title of a page with its content:
def parse(self, response):
# Extracting the page title
page_title = response.css(‘title::text’).get()
# Extracting all paragraph text
paragraphs = response.css(‘p::text’).getall()
# Storing the scraped data
yield {
‘title’: page_title,
‘content’: paragraphs
}
In this illustration, response.css(‘title::text’) chooses the tag and extracts its content.
response.css(‘p::text’) selects all the (paragraph) tags and extricates their text data.
Yield takes back the extracted information as a dictionary, which Scrapy collects and processes afterward.
You can moreover utilize XPath for further complex queries:
page_title = response.xpath(‘//title/text()’).get()
At this level, the spider crawls the target URLs, scrapes the desired information, and yields it in an organized form. You’ll be able to extract any sort of information, like text, links, images, or attributes, per your scraping requirements.
Step 5: Saving The Information
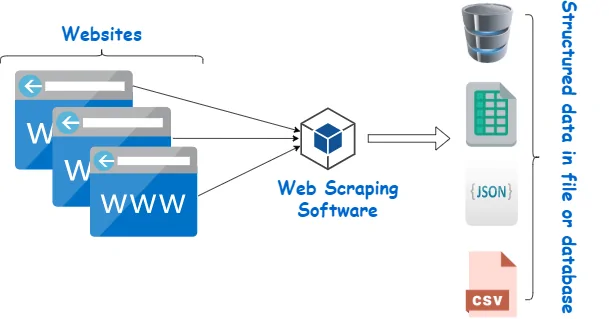
Once you are done scraping the essential information from the site, the next is to save it in a structured format for further examination or use. Scrapy presents many built-in alternatives for saving scraped information, including exporting to formats such as JSON, CSV, or XML. It permits you to effortlessly store and recover the data afterward.
To save the scraped information, you can utilize the command line options when running your insect. For instance, to save the output in JSON, you’ll perform the ensuing command in your terminal:
scrapy crawl example -o output.json
In this command:
crawl example indicates which spider to run.
-o output.json option implies Scrapy to yield the scraped information to a file named output.json.
In case you need to save the information in CSV form, simply alter the file extension using the following:
scrapy crawl example -o output.csv
On the other hand, if you need better control over how data is processed and saved, you’ll define a custom pipeline in pipelines.py, which permits you to include additional logic for preparing the data before saving it, like cleaning up content, filtering duplicates, or saving to a database.
The following is a simple case of a pipeline that will let you preserve the information in a JSON file:
import json
class JsonWriterPipeline:
def open_spider(self, spider):
self.file = open(‘items.json’, ‘w’)
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(item) + “\n”
self.file.write(line)
return item
According to this pipeline, open_spider will open a file when the spider begins. close_spider will close the file when the spider wraps up. process_item will write each object to the file in JSON format.
By saving the information in an organized way, you’ll be able to effectively get to and analyze it later, empowering you to infer insights or utilize it in diverse applications.
Step 6: Running The Spider
Presently, as you have established your spider and defined how to scrape and preserve the information, the ultimate step is to run your spider to begin the crawling process. This is often the minute when all the previous arrangements come together, and Scrapy starts to gather the information based on your specifications.
To operate your spider, open your terminal, move to your Scrapy project directory, and utilize the taking after the command:
scrapy crawl example
Replace the example with the title you indicated for your spider within the name attribute. On the off chance that you need to save the yield to a file at the same time, you can unite the crawl command with the output option just like:
scrapy crawl example -o output.json
Once you conduct this command, Scrapy will:
Begin sending requests to the URLs specified within the start_urls list.
Utilize the parsing strategy to manage the responses, extracting the desired information as depicted.
Save the scraped information to the required output file within the chosen format like JSON, CSV, etc.
In the crawling process, Scrapy gives real-time logs within the terminal, displaying the advancement of the spider, including any blunders or the number of items scraped. After the spider has wrapped up running, you’ll be able to check the output file to see the collected information structured and concurring with your specifications.
In case you wish to halt the spider before it ends, you can basically interrupt the method utilizing Ctrl + C. Together with your spider effectively operating; you now have an effective instrument to automate web scraping and accumulate information as required.
Conclusion
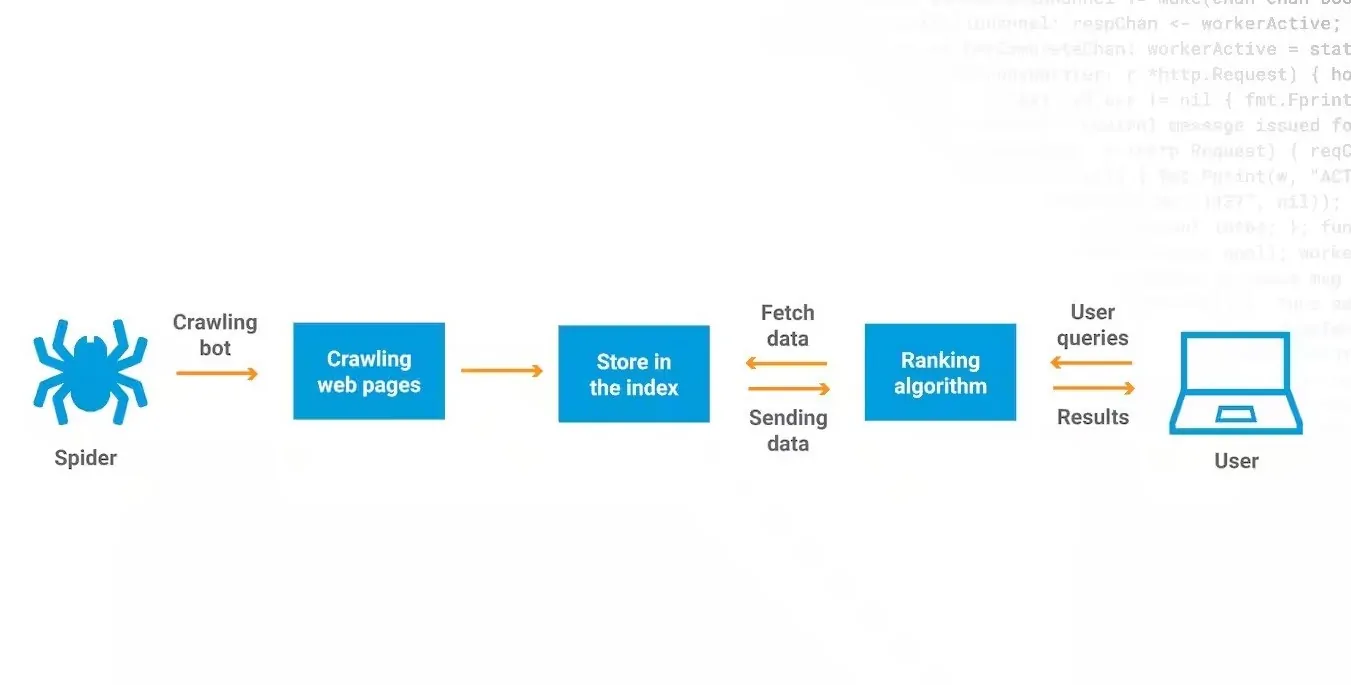
In sum, a web crawler, a reliable tool, helps search and automatically index website content and other information over the internet. They can create entries for a search engine index via automatic navigation. Web crawlers systematically scan webpages, discovering what each page on the website is about, so these details can be indexed, updated and retrieved for various individual or corporate applications. Businesses also use web crawlers to update their own web content. You, too, can benefit from this reliability, employing a web crawler with a combination of Python and Scrapy tools to acquire large amounts of valuable data.
