How To Use Beautiful Soup With Other Python Libraries For Web Scraping
Beautiful Soup is an excellent web scraping tool that is highly compatible with a variety of XML and HTML parsers. When you integrate Beautiful Soup with diverse other Python libraries, it functions as a resourceful and productive tool for extracting or processing data from various web pages. The necessity of incorporating it with other Python libraries is crucial as it can perform various basic tasks. Still, for complicated ones, it has to be paired with libraries like pandas, Selenium, requests, etc. Each pairing performs a specific task. For instance, integrating Selenium or requests with Beautiful Soup can let you easily interact with those websites that are using JavaScript to load content onto them. Similarly, by utilizing libraries like Pandas and SQLite, you can simplify the process of data storing for further analysis. This blog will go through the step-by-step phases to guide you on how to use Beautiful Soup with other Python libraries for web scraping.
Step 1: Installing The Essential Tools
The primary step in utilizing Beautiful Soup with other Python libraries for web scraping is installing the essential tools. The elementary libraries include Beautiful Soup, requests, and a couple of others like Selenium or Pandas, which are for your particular needs.
So install Beautiful Soup and the requests library utilizing ‘pip,’ Python’s package manager. Beautiful Soup will support parsing the HTML content. Similarly, the requests library is significant for sending HTTP requests and getting the raw HTML data from web pages.
Follow the given commands in your terminal or command provoke for successful installation of these:
pip install beautifulsoup4
pip install requests
If you’re working with some dynamic websites in which JavaScript plays a part in rendering content, you should also have Selenium and a web driver such as ChromeDriver to reenact browser interactions. Follow this code to install Selenium:
pip install selenium
Finally, if you intend to process or store information in a structured format, Pandas or CSV libraries are fundamental. To install pandas, use the following:
pip install pandas
Installing these libraries, you set up the core environment required for web scraping errands, empowering you to get, parse, and manipulate information from diverse websites.
Step 2: Sending An HTTP Request
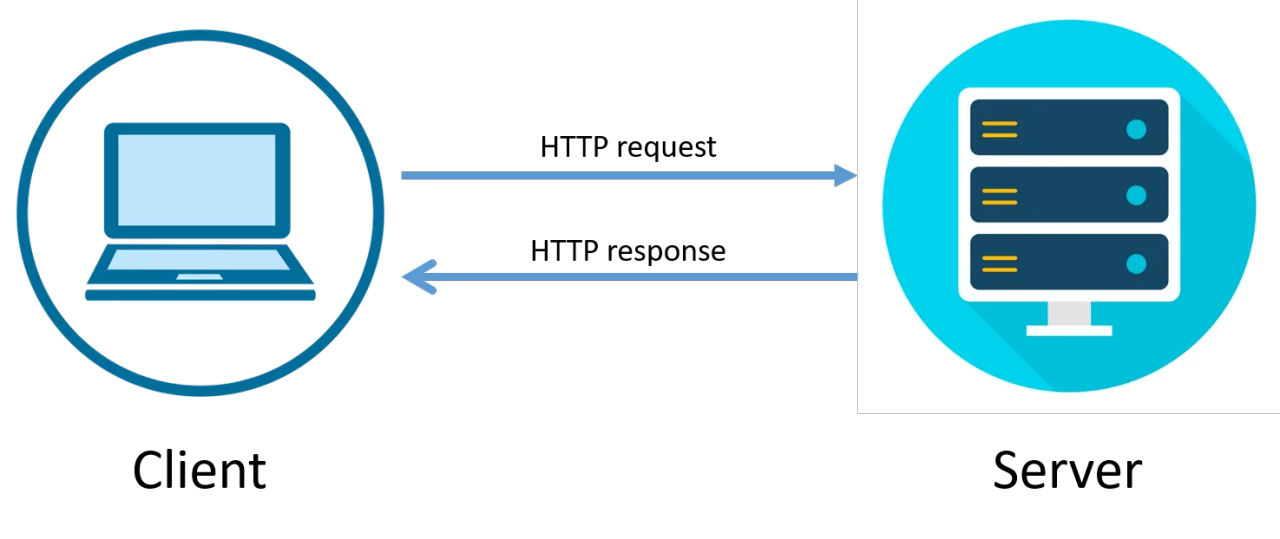
After installing the necessary libraries, you need to send an HTTP request to the site where you need to scrape. The requests library is perfect for this because it streamlines the process of making GET or POST requests for the retrieval of HTML content from web pages.
To start, import the requests library in your Python script and utilize the get() function to request the page’s content. Observe the given example:
import requests
url = ‘https://example.com’
response = requests.get(url)
html_content = response.content
In the above-given snippet, the get() method will send an HTTP request to the URL, and the server reacts with the page’s HTML, which is stored within the html_content variable. You’ll moreover have to review the status of the response to guarantee the request was productive:
if response.status_code == 200:
print(“Request Successful”)
else:
print(f”Failed to retrieve the page: {response.status_code}”)
If you opt for an additionally advanced utilization, you can tailor the request headers to imitate a browser visit, bypass restrictions, or manage with cookies and authentication. The requests library also supports timeout settings, which can stop your program from hanging if the server is slow to answer.
By utilizing requests to fetch the HTML data, you can proceed to parse it with Beautiful Soup in the successive step.
Step 3: Parsing The HTML Data
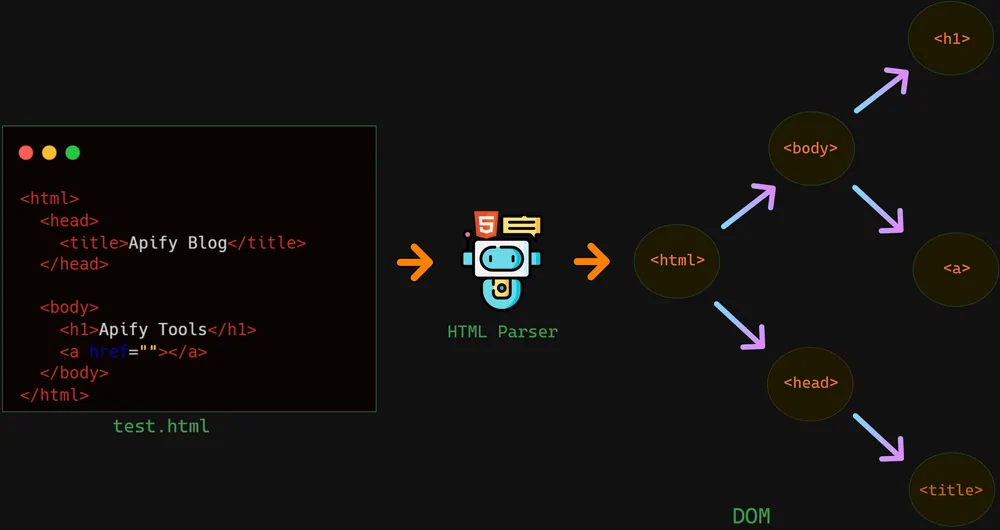
After retrieving the HTML data utilizing the requests library, the next thing you have to do is parse it using Beautiful Soup. Beautiful Soup makes it simple to explore and extract information from HTML or XML documents by making a parse tree that denotes the structure of the document.
Begin by importing the Beautiful Soup library and feeding it the HTML content retrieved within the previous phase:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, ‘html.parser’)
According to the example, html_content is the raw HTML you fetched utilizing the requests library, and ‘html.parser’ is the built-in parser utilized by Beautiful Soup. On the other hand, you can utilize parsers like lxml or html5lib for more progressive usage, though for most of the tasks, the built-in parser performs adequately.
After parsing the HTML, you can now get access to particular components using strategies like find() and find_all(). Look at the given example in case you are extracting all paragraph () tags from the page:
paragraphs = soup.find_all(‘p’)
for p in paragraphs:
print(p.text)
With Beautiful Soup, you can seek components by tag, class, ID, or even attributes, getting flexibility in focusing on the particular data you would like. It is perfect for extracting text, links, or other HTML components to gather the information required for your web scraping project.
Step 4: Handling Dynamic Data With Selenium
Various advanced websites utilize JavaScript to load or update substance vigorously, which implies that the inactive HTML fetched by the requests library might not include all the information you would like to have. If you have to deal with any of such cases, you can get help from Selenium, which is a web automation tool. It can simulate a browser and render the JavaScript content before moving to scraping.
Begin by importing Selenium and setting up a web driver like ChromeDriver to direct the browser. Following is an illustration:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Set up the Chrome browser
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# Open the webpage
url = ‘https://example.com’
driver.get(url)
Once the webpage is opened, Selenium waits for the JavaScript to load and renders the whole page. You will, at that point, retrieve the full page source along with dynamically loaded data:
html_content = driver.page_source
After the full page is loaded, you can pass the html_content to Beautiful Soup for further parsing with the help of this code:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, ‘html.parser’)
Selenium can also recreate user interactions, such as clicking buttons or filling out forms to scrape substance that demands user input or interaction. This step guarantees that you can manage websites with dynamic substance, making your web scraping skills more extensive.
Step 5: Precise Extraction With Regex
In spite of the fact that Beautiful Soup is fabulous for accessing and extracting data from HTML components, regular expressions (regex) give an extra layer of accuracy when managing particular patterns in content. Regex can be especially valuable for extracting strings like e-mail addresses, phone numbers, costs, or any information that observes an anticipated pattern inside the HTML content.
To utilize regex, you have to import Python’s built-in re-module, and then you can apply regex to extract particular information from the HTML content or from components parsed by Beautiful Soup. Following is a case of extracting all e-mail addresses from a web page:
import re
html_text = soup.get_text() # Extracts the plain text from the HTML
email_pattern = r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}’
emails = re.findall(email_pattern, html_text)
for email in emails:
print(email)
In this case, re.findall() searches for all occurrences of the e-mail pattern inside the HTML content and yields them as a list. You can so also extract other kinds of information, such as phone numbers or product IDs, by altering the regex pattern.
Regex works effectively apace with Beautiful Soup when particular information has to be extracted from a large amount of content, making it an effective device for polishing your scraping results and confirming precision in information assemblage.
Step 6: Storing Data Using Pandas
Once you have extracted the data, the ultimate step is to reserve it in a structured format for examination or future utilization. You can either preserve the data in a CSV file or utilize pandas to make data frames for more elaborate data manipulation.
For basic CSV storage, Python’s built-in CSV module operates satisfactorily. The following illustration is about storing data in the form of a CSV file:
import csv
data = [(“Product 1”, “$10”), (“Product 2”, “$15″)] # Example data
with open(‘scraped_data.csv’, mode=’w’, newline=”) as file:
writer = csv.writer(file)
writer.writerow([“Product Name”, “Price”])
writer.writerows(data)
According to this code, the writer.writerows() function writes your scraped information into the file and the writer.writerow() function indicates the column headers.
To deal with more advanced data handling, utilize pandas, which provide assertive tools for data examination and control. The following code can help you with data storage in the form of a pandas DataFrame, then exporting it as a CSV:
import pandas as pd
data = {“Product Name”: [“Product 1”, “Product 2”], “Price”: [“$10”, “$15”]}
df = pd.DataFrame(data)
df.to_csv(‘scraped_data.csv’, index=False)
Pandas streamline structuration, analysis, and even visualization of expansive datasets, making it an outstanding choice when dealing with complex data arrangements.
After storing your scraped data effectively, you can readily examine it, communicate it with others, or utilize it for further processing, both for machine learning and statistical analysis operations.
Conclusion
In a nutshell, the combination of different Python libraries with Beautiful Soup can significantly enhance the quality and efficiency of your web scraping projects. Beautiful Soup is an excellent choice for projects that focus on extracting data from a large number of static websites. On the other hand, libraries like Selenium, with their robust browser automation capabilities, are better suited for complex scraping operations that involve webpage interaction. Furthermore, to store data in appropriate formats, you will need the help of librarians like Pandas. Ultimately, with a diligent combination of different Python libraries with the Beautiful Soup as a basic component, your data extraction and processing till storing becomes a profitable task, allowing you to access both static and dynamic sites.
