How to automate PDF data extraction to Excel using Docparser?
Data extraction and Web scraping have become essential in today’s businesses for many reasons. In this article, you will master the most valuable skills; Extracting PDF data to Excel with Docparser.
Docparser is a document processing software designed to meet the needs of businesses that frequently process large amounts of documents.
How to Automate PDF Data Extraction to Excel?
Step 1: Create a Document Parser
Sign up first to get a Docparser trial at no cost. After that, you will be on your dashboard. Here you will be able to browse a selection of templates that are pre-set for various kinds of documents. Select the template that best matches the document you wish to analyze. If you cannot find the appropriate template, choose “Custom Template.”
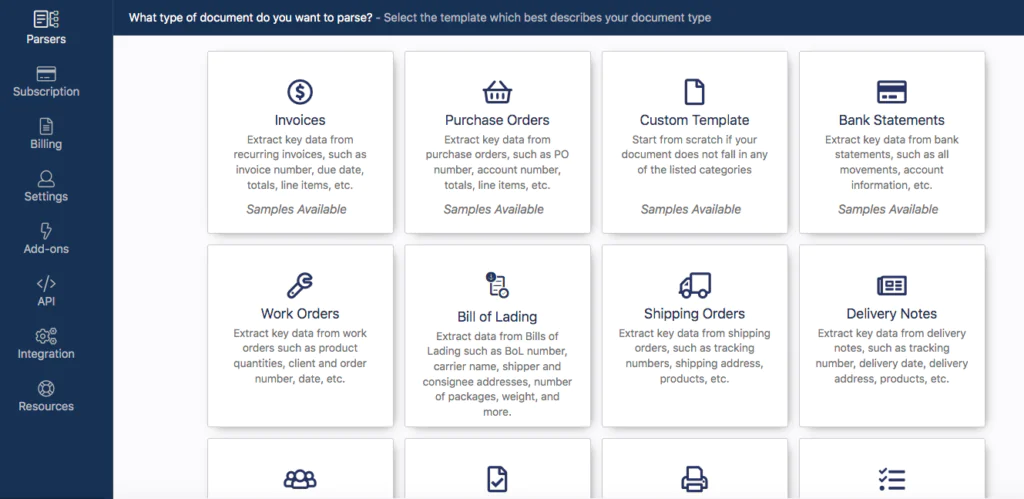
Pro tip: You can make multiple Document Parsers, each for a specific type of document that has a particular format (an invoice, bank statement, etc.).
Step 2: Upload a PDF sample
Upload one (or many) PDF(s) of your drive, or drag and drop it onto your computer. Connecting to your cloud storage service or emailing your PDF to your email address as an attachment is also possible.
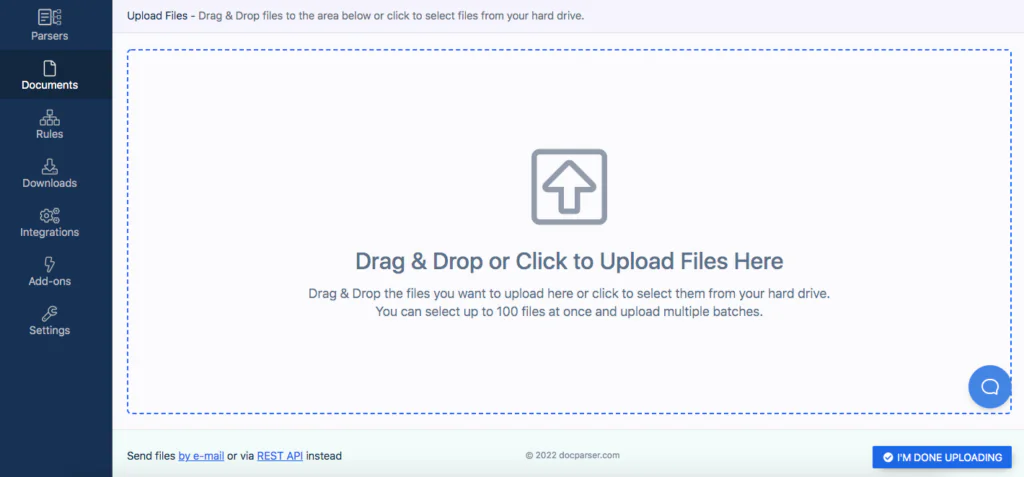
Then, click “I’m done uploading” and type in a name for your Parser.
Step 3: Create Parsing Rules to aid table data extraction
Docparser utilizes Parsing Rules set by the user to determine the best place to search for information in documents to extract the data. It would be best if you made a Rule for every field within your PDF.
Develop a Parsing Rule that you can use for the extraction of your table
Click on ‘Rules’ on the left-hand side of the panel. Click on the button that says ‘Create The First Parsing Rule.’
Within the Parsing Rules editor, there are a variety of Parsing Rules for all kinds of information from the text to names or addresses, phone numbers tables, etc. In this case, we’ll extract the table, so we’ll select the tab ‘Table Data.’ An editor will then open the document and allow you to decide where the table will start and the place it will end. It is also possible to add sliders that indicate the location where each column starts and where it ends.
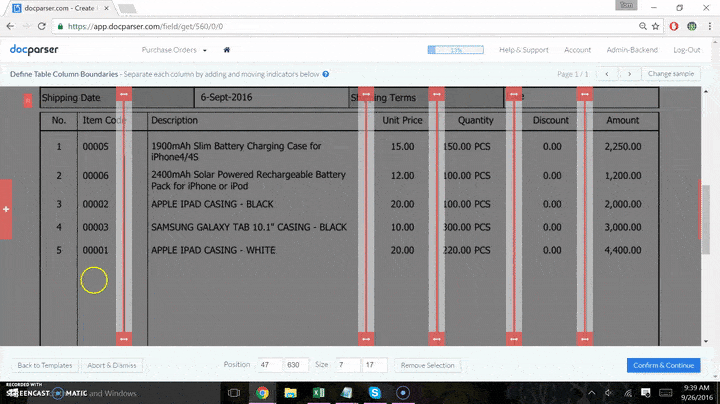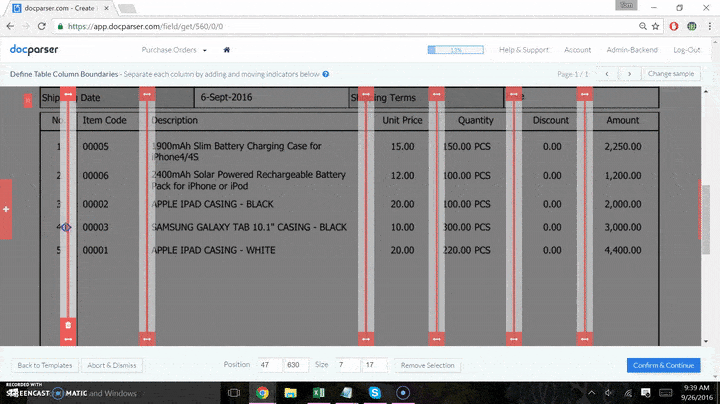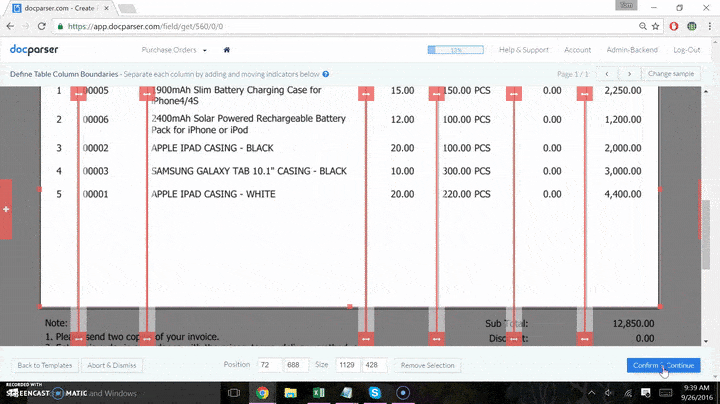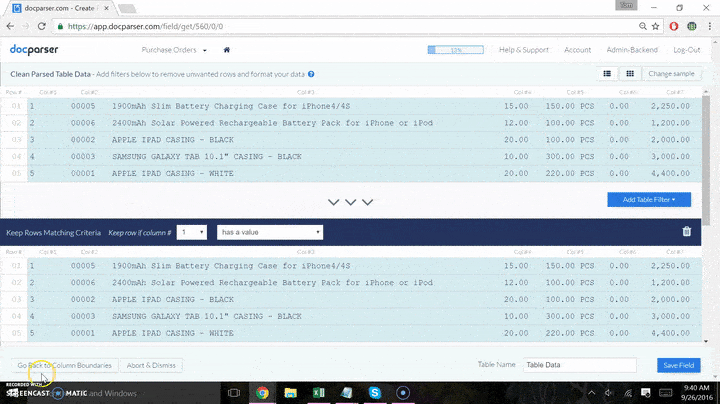
After you’ve finished:
Click “Confirm,” The program will give you a visual representation of the extracted information.
Check that everything is correct and formatted as you want it to appear.
If not, include table filters to cleanse your data.
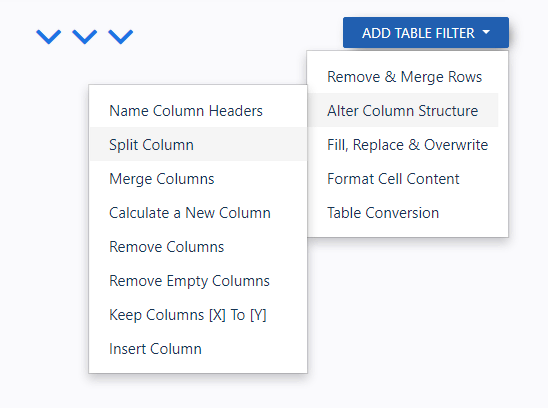
There are many filters you can link up, for example:
Take out specific columns or rows
Name column headers
Convert columns into one or split them
Text search and replacement
Format dates as numbers, dates, or blank spaces
Plus, a lot more
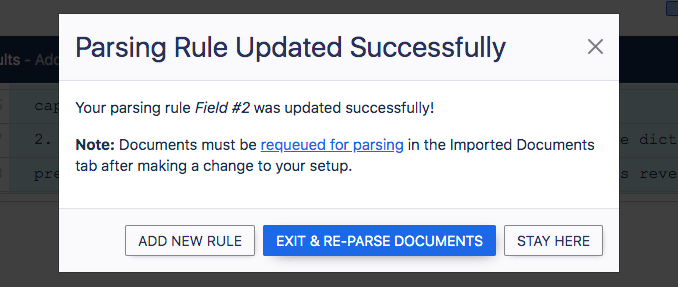
When your data is formatted according to your preferences, and you are happy with it, click ‘Save the parsing rule.’ A pop-up will appear asking you to create a new Rule, exit and re-parse the document, or remain within the editor.
Create a new Rule for each additional data field you require. After adding the previous Rule, when the dialog box appears again, choose the option “Exit and Re-Parse Documents.”
Step 4: Download your parsed data parsed to Excel
We’re almost done! Navigate to the Downloads section of your dashboard, and select Excel from the available download formats. You can download the extracted data in the screenshot below, not just in Excel format. However, you can also download it as a CSV, JSON, or XML file.
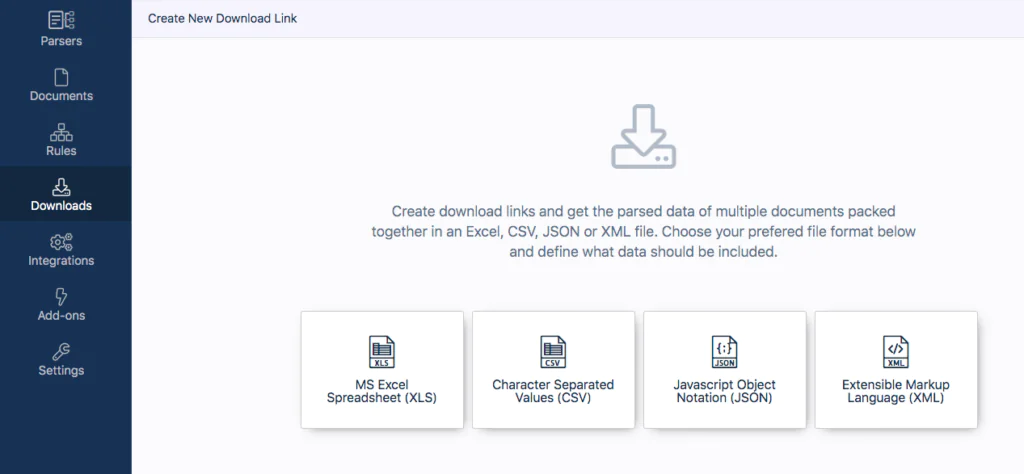
Create a name for your Excel file, and then select the number of parsed files you want to download. For instance, you can download the latest 100 files or the ones received on the current day.
Then, click “Save,” and Docparser will generate the download link. Click on it to copy the Excel spreadsheet to your computer. Voila!
Final words
PDF files usually permit users to download, browse, print, and send information. Therefore, to alter information, you must convert it from PDF into an alternative format. Excel is mainly efficient for editing data, maintaining an inventory of data, conducting analysis and calculations, and other tasks. The most effective method is to transfer PDF data into Excel.
