
How Optical Character Recognition Works?
Optical Character Recognition (OCR) is the process of conversion of any piece of text containing either images or graphs into the editable text after careful processing of the document. Not only this, OCR enables you to extract text from any scanned document or an image within a text that can be pulled off with less effort. The technology is helpful for a variety of applications at large, such as data entry of documents, automatic number plate recognition, digitization of printed documents in Google Books, and even passing out CAPTCHA (Anti-bot mechanisms).
Optical Character Recognition Service plays an undeniable role in the CAD world. It can easily convert all the raster sketches into editable drawings. The blog focuses on the aspect of the functionality of OCR, to clarify all the behind the back scenes which go into smooth text extraction. There are two most commonly employed techniques in OCR, the First algorithm is pattern recognition of the text and the second one detects all elements or features within a text.

Pattern recognition
Using pattern technique, the PC can recognize the entire character list embedded within a specific document. The computer then matches it with the matrix of the characters which is already stored within the software. This matrix matching enables easy and fair recognition of the text without any error. The drawback, however, relies on input characters and the stored characters being in the same scale and font size.
Traditional formats took much time in getting trained to comprehend a certain character within an image. Now there are many capable software and tools that can easily support a variety of digital image file format images. Some systems are capable of reproducing formatted output that closely approximates the original page including images, columns, and other non-textual components. You can look up to the photo placed above, of the first-ever font created in the 1960s for OCR (— the OCR-A —). Every letter was of the same width, at the time, all bank cheques were printed with the same font to allow computers to process them, Interesting Right?
Neural networks work analogously to the human brain. They learn to recognize shapes and patterns concerning numerous examples as references.
Feature extraction
Feature extraction
Feature Extraction is the more sophisticated application, which superficially spots all elements within a document. It works to decompose characters into different features like closed hoops, and intersections. By employing such rules in the OCR program, you can identify most capital letters which you intend to locate of the font which is written in the text.
For example, The letter ‘A’ consists of two diagonal lines that are connected at the top and form closed angles at the point of intersection. All the lines join together by another short and horizontally crossing line in between the two diagonal vertical lines.
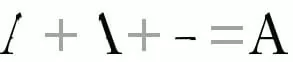
Pre-processing to improve text recognition
To recognize the text more efficiently without any recurring errors, the software pre-processes, the image within a text with the assistance of the following tools:
Pre-processing
OCR Software often “Pre-Process” images to boost the chances of recognition of elements within a text of any form or shape.
1. De-skew
when the documents are not properly aligned based upon a specific format, there is a need to title them clockwise or anticlockwise to section text lines. This organization can be vertical as well as horizontal.
2. Despeckle
This step is important to remove any sort of spots within the text such as positive spots or negative spots, which can render the text smoothness hence creating distortion. There elimination results in smooth edges.
3. Binarization
For conversion of an image into black-and-white, this step which is known as the binarization task is conducted to differentiate elements present within a text.
4. Line Removal
Cleans up non-glyph boxes and lines.
5. Layout Analysis or “Zoning”
Layout analysis significantly aligns columns, paragraphs, and captions as organized blocks of useful text.
6. Line and Word Detection
Present words and characters shape the text baseline, divides words into different categories.
7. Script Recognition
In multiple-layer documents, the script might as well be transformed at the word level. OCR comes in handy to manage the particular script easily.
8. Character Isolation or “Segmentation”
OCR Characters link other characters with artifacts. A single character is broken into several artifact-based pieces.
9. Normalization
Normalization is the simpler step, involving the ratio and scaling of the extracted text.
Post-processing
OCR Accuracy can be further increased with the output is restricted by a mental lexicon for a document file. For instance, the output can become more of a single string or a character. Advanced OCR Systems work on retaining the original page structure for safe retrieval purposes. For this, you need to create a PDF containing both the original image and searchable image text.
Error correction
The “Near Neighbor Analysis” uses frequencies for a co-relational mechanism to correct all textual mistakes. For instance, “Washington, D.C.” is more prevalent in English than “Washington DOC”. Hence, the former is switched on automatically.
Grammar
Grammar is an integral part of any text. It can also help to determine the language which is being scanned. A word is likely to be a verb or noun or adverb. This can help provide increased efficiency. In OCR Post-Processing, the Levenshtein Distance algorithm is often used to control and outnumber the OCR API outcomes more efficiently.
How will OCR help your Business?
OCR benefits your business with several advantages. OCR supports a wide range of fields with its intelligent document processing technology. It includes from daily routine newspaper assortment to managing legal documentation on a large scale. OCR performs 98% accuracy in reading the handwriting of documents and digital image structures. Further significant uses of OCR involve:
- In business, Data volume and document size matter a lot, OCR helps to process contracts, shipping slips, government forms, licenses, certificates, tariff sheets, catalogs, to enhance your business operations proficiently.
- By using OCR, you can easily check for any kind of distortion or data variance from the original terms and conditions. Cheques are verified by comparing invoices.
- With the help of OCR, any kind of data loss can be detected within a document. Such as tax avoidance or overpayment and much more.
- OCR is primarily used to enhance analog records transformation.
How ITS Can Help You With OCR Services?
Information Transformation Service (ITS) has a lot to offer in a little. ITS OCR Professionals are trained in attaining multi-lingual objectives. Our executives will manage your data center in the most effective way. ITS Team holds a comprehensive understanding of ICR and OCR Service providing process, Functioning, and solutions, making it a beneficial association for your business. We are exceptional at putting up with international standards and providing you 100% error-free results within the shortest interval of time. ITS can benefit you with OCR Services in the long run. ITS works 24/7 round the clock services for quick turnout time that helps the client benefit from the time zone advantage. If you are interested in ITS OCR Services, you can ask for a free quote!
