
What is Automated Document Classification & Indexing?
Document indexing and classification captures essential information from paper documents to readily convert them into digital formats for purposes such as data storage, search, usage, and retrieval at any intended time. But by which process does the information is readily categorized under proper category reference? Indeed the process requires smarter intelligent systems to understand the meaning and content of information in an as accurate manner as possible. Here, automated document classification and indexing mechanisms play their part to efficiently process the text into suitable categories and formats. For instance, let us take the word “apple”, to enable the system to understand and classify the word as a “fruit” it must identify the relationship existing between the two terminologies.
Does One Need Document Classification? Isn’t Google Enough?
Is it really important to organize a text into functional categories when Google can search for all material within a matter of seconds? Google can only provide you with information that is of little relevance to your particular content needs. Certain business-centric contexts are complex and the situation fluctuates daily. Automated document classification and indexing provide a meaningful and systematic document classification based upon certain specific business contexts. A manual approach to document classification can make you suffer two major limitations i.e. it is more time-consuming and it is subjective. While automated solutions are fast-paced, accurate, and detail-oriented.
Human intelligence requires maximum time and input to understand as well as organize information within appropriate proportion. When dealing with mass text you are likely to make personal errors that will hinder your business schedules and progress. Just suppose you reading all the articles in a newspapers archive on laws of a governmental institution or any other information that proves useful for your business domain, it is inconceivable for a human mind to manage such a huge volume of information even within a reasonable amount of time. With our human capabilities and biases, we assume different interpretations from a piece of information. Thus, to keep business data safe, unbiased, consistent, coherent, organized automated document classification and indexing is the way forward!
Best Practices To Begin Automated Document Classification & Indexing Right Away
Many people believe in a perfect algorithm the one that can readily classify data with little or no initial setup and can instantly turn high-quality results for every area of application. Hence, your perfect algorithm is none other than an automatic document classification and indexing system. Whose output is scalable, objective, and faster, it allows organizations and businesses from any field to classify content making it available at any point in real-time? Reliable document classification and indexing software require defining the process diligently for a smooth data classification workflow.
Define the requirements as your content will be recognized and organized based on the input.
Define the method by starting by sending an objective and clear configuration of categories. Furthermore, you can also conduct testing, refinement, and customization activities for measuring content performance.
Document Classification & Indexing Services
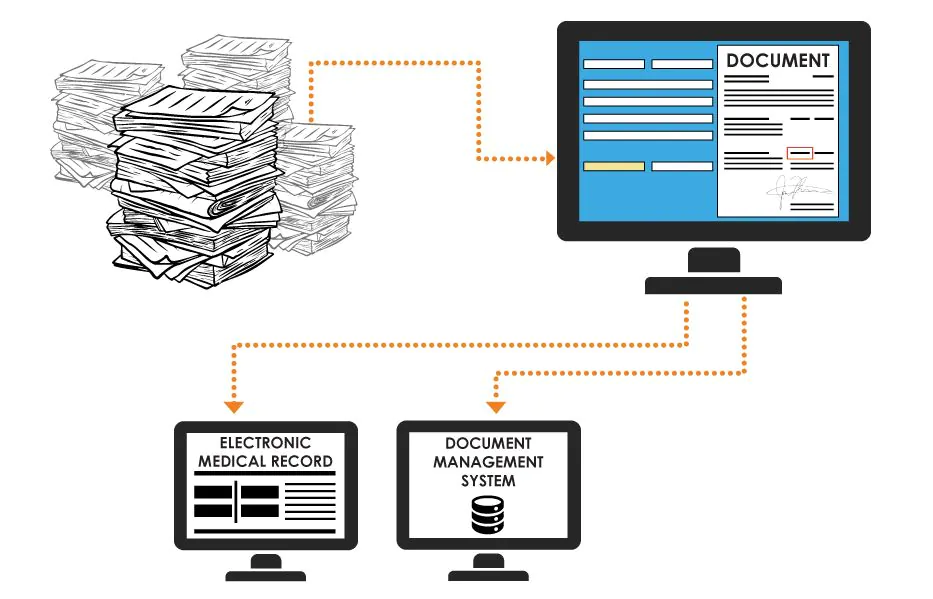
There are various related services that you can benefit from by outsourcing your document processing projects, these services include –
Creation of Classification Database
Document classification is carried out by collecting multiple images. The latest big data technology used in automatic document classification systems enables the creation of a dedicated and robust database. The classification and organization mechanism is well suited to cater to document processing. Advanced features such as Optical Mark Recognition (OMR) and Optical Character Recognition (OCR) have inbuilt cognitive features to accurately recognize the size and type of any document.
Document Classification
Machine learning customizable capabilities and versatility allow a professional to create a self-learning module to index documents. By outsourcing your major and minor document processing projects you get well structured and balanced databases that speak finesse and ease themselves. Automated solutions are likely to increase data accuracy by 80%. The system can be updated when you introduce any new document type.
Data Import and Auto-Discovery of Documents
You can easily group and categorize volumes of data automatically without the need to manually check the process progress time and again. All business documents can be properly indexed and classified by eliminating the use of conventional methods.
Classification and File naming
Automatic document classification solutions allow you to efficiently organize mass documentation files into portable file formats saving you more time and effort. An automated document classification system is the right option for always ready-to-go information. The software can be readily updated and adapted to carry out unlimited document classification.
PDF File processing application Development
Automated document classification tools such as HTML plugins and JavaScript modules allow document labeling PDF files. All results are editable and searchable for prospect future functions. An outsourcing partner allows effective document scanning and classification into PDF files with utmost consistency.
High Volume Data Scanning and Management Solutions
An experienced professional can transform your manual classification and indexing solutions to skillfully optimize your business operations. For larger enterprises and organizations all your big data concerns are well taken care of by utilizing top quality bf data analytics frameworks such as Hadoop to derive unique data insights. All automated systems offer smooth document processing for better backend support. A good outsourcing partner provides in-depth consultation to help you interpret, plan and implement automated document indexing.
Benefits of Automating Document Classification & Indexing System
High Levels of Data Accuracy
Automation is a superior method to manual task management in terms of accuracy, efficiency, and speed of operations.
Reduction in Operational Costs
Less human intervention means less time consumption and less use of resources to classify documentation. This helps to significantly reduce business operational costs.
Ease of Data Retrieval
The automated system employed to classify documents doesn’t only make it easier to cater to large volume data storage but also opens doors to retrieve it.
Better Organization of Documents
Automatic document classification helps organize documentation, databases, and files within predefined categories and references for streamlined business workflow.
How ITS Can Help You With Data Abstraction Service?
Information Transformation Service (ITS) provides you with excellent Data Abstraction Services and other related options for a better data experience. We consider customers’ ease and satisfaction as its topmost priority. Minimizing workload and clearing out errors from large databases can serve your projects with full potential daily. Our professional Data Abstraction Service is all about encapsulating large and incomprehensible data chunks into concise data segments that can be fit into minimum space. However, the ITS Team doesn’t compromise upon the standard set for information quality while adhering to size metrics and trying to present the maximum amount of relevant information within the minimum space required.
With 30 years of prolonged satisfactory service-providing experience, you can count on us for all your big data projects. If you are interested in ITS Data Abstraction Service, you can ask for a free quote!
