
How to use ScrapeHero for Web Scraping?
Everyone is seeking methods to innovate and use new technologies in today’s competitive world. For those looking for an automated method for obtaining structured web data, web scraping—also known as web data extraction or data scraping—offers a solution. If the public website you want to obtain data from doesn’t have an API or if it has but only offers restricted access to the data, web scraping can be helpful. Furthermore, you can find the number of web scrapers available today, however, in this post we will talk about ScrapeHero cloud.
This article will show you how to use ScrapeHero Cloud to get data on grocery delivery from Amazon. Simply start the Amazon crawler after feeding it the relevant URLs, and you can extract as much data as you like.
What is web scraping?
The technique of automatically downloading data from websites to your computer or database is known as web scraping. The tiresome process of manually copying and pasting the displayed data can be automated by using web scraping software that crawls numerous pages of a website. Usually, the data is downloaded in spreadsheet (tabular) format.
Many digital firms that rely on data harvesting use web scraping. Legitimate use cases consist of:
A website is crawled by search engine bots, who then examine its content and assign it a ranking.
Price comparison websites use bots to automatically obtain product prices and descriptions from affiliated seller websites.
Companies that conduct market research use scrapers to gather information from forums and social media (e.g., for sentiment analysis).
What are the benefits of web scraping?
There are countless uses for web data extraction, commonly referred to as data scraping. You may rapidly and accurately automate the process of information extraction from other websites with the use of a data scraping tool. Additionally, it can ensure that the information you’ve gathered is properly arranged, making it simpler to analyze and apply to other tasks.
Web scraping data is frequently utilized for competitor price monitoring in the domain of e-commerce. It’s the only realistic way for brands to examine the prices of the goods and services offered by competitive firms, allowing them to adjust their own pricing policies and gain an advantage over rivals. Manufacturers also use it as a tool to make sure retailers follow the rules for pricing their goods. By monitoring online product reviews, news stories, and feedback, market research firms and analysts rely on web scrapers for data extraction in order to evaluate customer sentiment.
There are further uses for web data extraction. In journalism, SEO monitoring, competitor analysis, data-driven marketing, lead creation, risk management, real estate, academic research, and many more fields, data and web scraping tools are frequently utilized.
What is ScrapeHero cloud?
ScrapeHero Cloud is a cloud-based web scraping tool. It contains pre-built scrapers that can gather information from a variety of websites, including Twitter, Google, Yelp, LinkedIn, Indeed, Zillow, Walmart, and more. You don’t need to bother about choosing the fields to be scraped or download any software because these scrapers are simple to use and cloud-based. The majority of crawlers have a free test plan. Any browser can access the scraper and the data at any time, and it can transfer the data directly to Dropbox.
Here are the steps for scraping Amazon’s grocery delivery data.
Register for a ScrapeHero Cloud account.
Select the Amazon Search Results Scraper as your Amazon scraping tool.
Enter the list of input URLs.
Run the crawler, then download the data.
Web scraping is effortless with cloud-based web crawlers from ScrapeHero Cloud. You may easily scrape the necessary data, whether it is public data from Google, retail websites, social media, or recruitment websites.
All you have to do is submit the input URLs, schedule the data-scraping task at your convenience, and receive the collected information directly to your inbox.
Data fields from Amazon that we can extract
You can obtain the following data using the Amazon Search Results Scraper:
Name of the product, category, price, reviews, ratings, description, ASIN, and much more.
Scraping Amazon for Grocery Delivery Data
One of the easiest online scrapers to use is ScrapeHero’s Amazon Search Results Scraper. The following steps describe how to extract the desired data fields from the Amazon grocery search results page:
Step 1: For access to the Amazon scraping tool, register for a ScrapeHero Cloud account
By registering with your email address at https://cloud.scrapehero.com/accounts/login/, you can create a ScrapeHero Cloud account.
Before subscribing to ScrapeHero Cloud as a new user, you can test your chosen crawler by free-scraping up to 25 pages. For a thorough description of how to utilize the Amazon Search Results
Scraper offered by ScrapeHero Cloud, see the section below.
Step 2: Fill out the inputs and add the Amazon Search Results Crawler to your account.
You may add the Amazon Search Results Scraper from the Crawlers tab after creating your ScrapeHero Cloud account.

Now, click “Add this crawler to my account”. You can see the following data fields on the main input page under the “Input” tab:
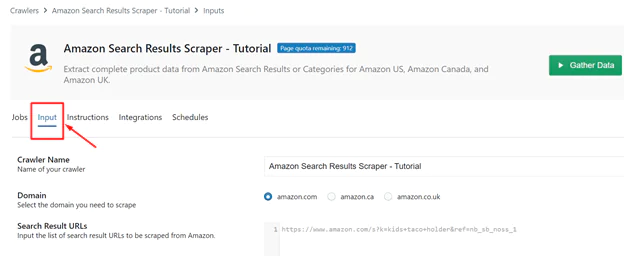
1 Crawler name: You may distinguish between different scraping operations by giving your crawler a name. Fill out the input field with the desired name, then click “Save Settings” at the bottom of the page.

2 Domain: You may extract comprehensive product data from categories or search results on Amazon US, Amazon Canada, and Amazon UK with ScrapeHero’s Amazon Search Result Scraper. Simply enter the domain you want to use in the input field, and the scraper will handle the rest.
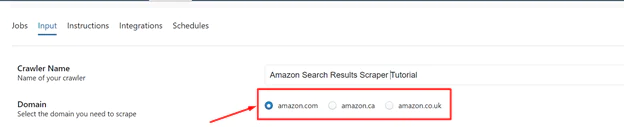
3 Search Results URL: Put your target URLs in this data field after that. You can add more than one URL if you want to scrape them by separating them with a new line (press Enter key).
If you’re using the free plan, we advise utilizing no more than three input URLs. The Amazon Search Results Scraper may retrieve data from as many URLs as you add, though, if you already have a ScrapeHero Cloud subscription.
The following method can be used to retrieve the search results URLs from the Amazon website:
Visit Amazon US, Canada, or the UK. For this tutorial, Amazon US has been selected.
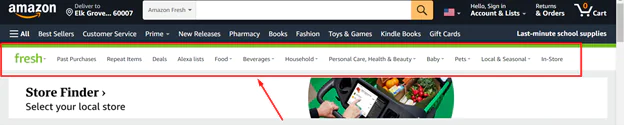
Choose an Amazon Fresh category at this point. You can also add filters if necessary to get the search results you want. Next, enter the following URL in the Search Results URLs data field:
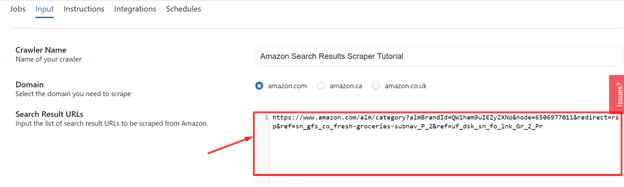
4 Keywords: Users must enter the list of keywords they want to use to scrape data about Amazon’s groceries in this box. Use phrases like “apples organic,” “apples fresh,” or “apples fresh Honeycrisp” as examples.
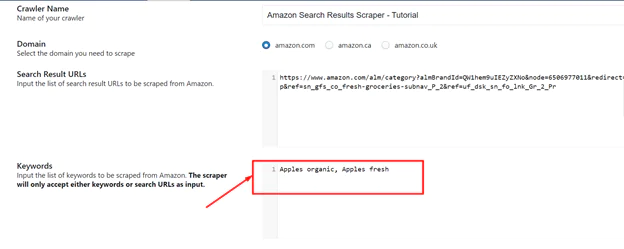
If you’re unclear about the keywords to use, you can enter the URL you want for the search results.
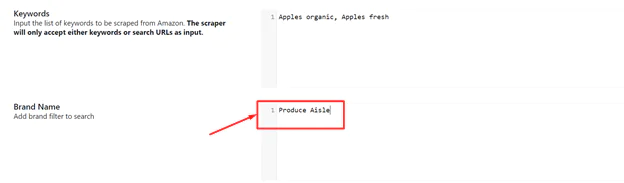
5 Brand name: There are hundreds of brands on the Amazon marketplace. Including the brand names of your competitors’ products can make the scraping process faster.
6 Number of pages to scrape: The number of Amazon search results pages that will be scraped can be selected. You have the following options from which to choose:
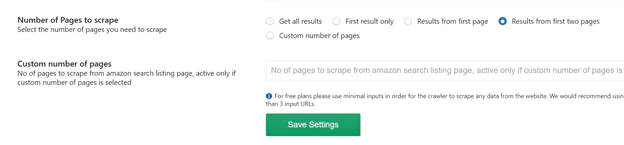
If you have specific requirements, enter the required number of pages in the data section below labeled “Custom number of pages.”
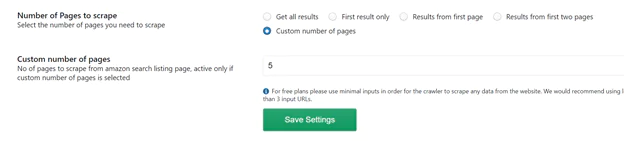
After filling in all the information, select “Save Settings” to keep the changes.
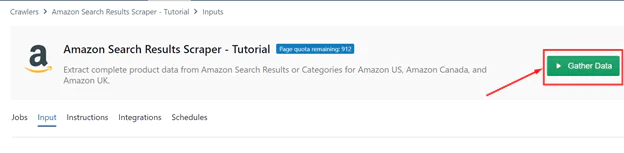
Step 3: Running Amazon search results scraper
To start the task, click “Gather Data” at the top of the page.
Under the Jobs tab, you can keep track of how the Amazon scraping tool is performing. The scraper’s status is displayed there.
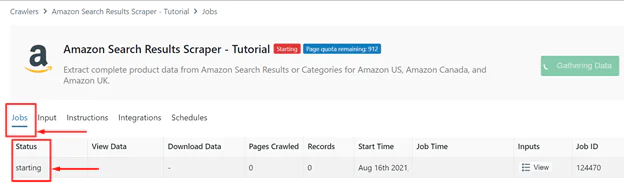
Your data is being collected if the status displays “Running.”

If the status becomes “Finished,” it means the crawler is done with its task.

Step 4: Downloading the scraped data
Finally, select “View Data” to view the collected data or “Download” to save the results to your computer in Excel, CSV, or JSON format.
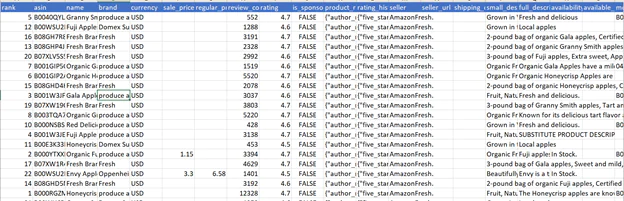
Here is how the CSV formatted data from the grocery scrape looks:
Final words
The world’s information, whether it be text, media, or data of any other type, is stored on the Internet. Data are shown in one way or another on every web page. The success of the majority of enterprises in the world today depends on having access to this data. Sadly, the majority of this data is not accessible. Most websites don’t provide you the choice to save the information they display to your computer’s local storage or to a website of your own. At this point, web scraping helps you a lot. Web scraping has countless applications for both professional and personal needs. Every company or person has a different need for data collection.
In this tutorial we learned about the Cloud-based Web Scraping tool; ScrapeHero. ScrapeHero is easy and simple to use and is commonly used for scraping data from a variety of websites, including Twitter, Google, Yelp, LinkedIn, Indeed, Zillow, Walmart, and more.
