How To Store And Manage Crawled Data
In order to ensure that the collected data collected through scraping is properly organized and usable, it is important to effectively store and manage the crawled data. Additionally, researchers and organizations have to deliberately rely on web crawlers to fetch useful data from various sources, and structuring that data is critical for usability. It is common to witness messiness in raw crawled data, which also consumes a lot of storage volume. That gigantic amount of messy data can also overload systems, which leads organizations to lose useful insights and face delayed data retrieval. On the other hand, the establishment of a structured storage framework enables finer data handling, search, analysis, and retrieval. The important strategies for properly organizing and storing crawled data range from the simplest phases of data extraction and formatting to the intricate steps of choosing suitable storage plans as well as ensuring the security of data. The following are the thorough steps for structuring and storing raw crawled data.
Step 1: Extracting And Preprocessing

The primary step in overseeing crawled content is extracting and preprocessing it to guarantee it is uncluttered and prepared for storage. Coding is fundamental to parsing and cleaning the raw information. Tools such as Python’s BeautifulSoup or Scrapy are usually utilized for this reason, empowering you to scrape content from web pages effectively.
After the raw information is crawled, it frequently contains insignificant components like scripts, ads, and duplicate data. Preprocessing includes cleaning this data by filtering out pointless parts, expelling duplicates, and normalizing formats. For instance, if extracting text from HTML, you’d clean the data by expelling HTML tags and extracting, as it were, the content content that’s pertinent.
Python is a fabulous language for web scraping due to its effortlessness and the accessibility of libraries such as BeautifulSoup, which permits you to extract and clean information with ease. Preprocessing guarantees that the information is organized in a standardized format and prepared for the following steps in storage and examination.
Following is an example Code:
from bs4 import BeautifulSoup
import requests
# Crawling a webpage
page = requests.get(‘https://example.com’)
soup = BeautifulSoup(page.content, ‘html.parser’)
# Extract and clean data
data = soup.find_all(‘p’)
cleaned_data = [item.get_text().strip() for item in data]
Step 2: Data Organization
Once you have extracted and processed the data, the next step is to structure it in a format that makes it simple to store and handle. Organized information is vital for efficient querying, examination, and future retrieval. You can store the cleaned information according to the use case in different designs such as JSON, CSV, or database-compatible formats such as SQL. Arranging data in proper formats helps to organize the data definitively, turning raw information into usable insights.
For instance, in case you’re extracting information such as titles, content, or dates from a website, you can store it in an organized format like a dictionary in Python, which can thereafter be changed over into a JSON file or inserted into a database. Systematizing the information confirms consistency and makes it less demanding to filter, search, and control for future use.
Python offers helpful modes to structure information utilizing libraries such as json for JSON files or csv for CSV files. An organized format moreover encourages the procedure of storing information in relational (SQL) or NoSQL databases for further management.
Look into the given example Code:
import json
# Structuring the cleaned data
structured_data = {
“title”: “Example Title”,
“content”: “This is an example of structured content”
}
# Save the structured data as a JSON file
with open(‘data.json’, ‘w’) as file:
json.dump(structured_data, file)
Step 3: Selecting A Suitable Storage

After the information is structured, the following step is selecting a suitable storage arrangement based on the sort and volume of data. Selecting the proper storage strategy is fundamental for the adaptability, availability, and proficient retrieval of data. As per upon if the information is structured or unstructured, varying storage arrangements are accessible.
For instance, if the data is structured, relational databases like MySQL or PostgreSQL are great options. These databases employ tables and relationships between information fields, making them perfect for exceedingly organized datasets that demand complex inquiries. Conversely, NoSQL databases like MongoDB or document-based stores such as Elasticsearch are way better fitted for semi-structured or unstructured data, presenting flexibility in storing expansive volumes of shifted content.
In a few cases, file storage frameworks, including Amazon S3, can be utilized when managing colossal volumes of unstructured information like pictures or crude HTML files. The selection of storage ought to assess variables such as information volume, scalability needs, and access speed.
Utilizing Python libraries such as sqlite3 for SQL databases or pymongo for MongoDB can assist you in interacting with diverse storage frameworks proficiently.
Following is a code example:
import sqlite3
# Connect to SQLite database (or create it)
conn = sqlite3.connect(‘example.db’)
cursor = conn.cursor()
# Create a table for structured data
cursor.execute(”’CREATE TABLE crawled_data (title TEXT, content TEXT)”’)
# Insert structured data
cursor.execute(“INSERT INTO crawled_data (title, content) VALUES (?, ?)”, (“Example Title”, “Sample Content”))
# Commit and close
conn.commit()
conn.close()
Step 4: Datta Indexing
Once the data is stored, the following step is to execute indexing for effective information retrieval. Indexing arranges the stored information in a way that permits fast and simple searches. Without appropriate indexing, retrieving specific pieces of data from expansive datasets can end up slow and wasteful, especially as the volume of crawled information extends.
In the case of structured data in SQL databases, making indexes on frequently queried columns like titles, dates, or distinct keywords can altogether accelerate search operations. In NoSQL databases or file-based frameworks, tools like Elasticsearch are commonly utilized to index large sums of semi-structured information, permitting near-instantaneous search results.
A great indexing procedure ought to be outlined around the sorts of queries you intend to run on the data. For instance, if you’re habitually looking through article titles, indexing that field will permit much faster lookups. Elasticsearch, for instance, indexes documents in a way comparable to how search engines work, empowering fast and effective full-text search capabilities.
Following is a code example of utilizing Elasticsearch:
from elasticsearch import Elasticsearch
# Connect to Elasticsearch
es = Elasticsearch()
# Index a document into Elasticsearch
doc = {
“title”: “Example Title”,
“content”: “This is a sample content for indexing”
}
res = es.index(index=”crawled_data”, document=doc)
# Retrieve data using search query
search_result = es.search(index=”crawled_data”, query={“match”: {“title”: “Example”}})
print(search_result)
Indexing is pivotal for versatility and guaranteeing that your information remains readily searchable, no matter how huge the dataset grows.
Step 5: Creating Data Backup
After the crawled information is stored and indexed, setting up data backup and replication is necessary to avoid information loss and guarantee high accessibility. Backup techniques are significant for ensuring against unanticipated system failures, coincidental deletions, or cyber-attacks. Standard backups permit information restoration in case of any issues, while replication ensures that data is accessible from numerous areas to avoid downtime.
There are distinctive backup techniques, like full backups, which save all data; incremental backups, to save only changes from the last backup; and differential backups, to save changes since the final full backup. According to your system’s demands, you might utilize a blend of these strategies to attain comprehensive coverage.
Replication includes replicating your data over numerous servers or geographic locations, guaranteeing that on the off chance that one server goes down, the data is still available from another. Cloud storage arrangements such as Amazon S3, Google Cloud, or database-specific replication tools can be utilized to automate reinforcements and replication.
Observe the given code of Automated Backup:
import shutil
# Backup function for copying database file to another location
def backup_database(src, dest):
shutil.copyfile(src, dest)
# Paths for original database and backup
original_db = ‘example.db’
backup_db = ‘backup_example.db’
# Perform the backup
backup_database(original_db, backup_db)
Frequent automated backups and replication make sure that your crawled information is secure, redundant, and continuously accessible for retrieval, indeed within the case of unforeseen losses. This step is basic for keeping up the integrity of expansive information sets over time.
Step 6: Ensuring Data Security
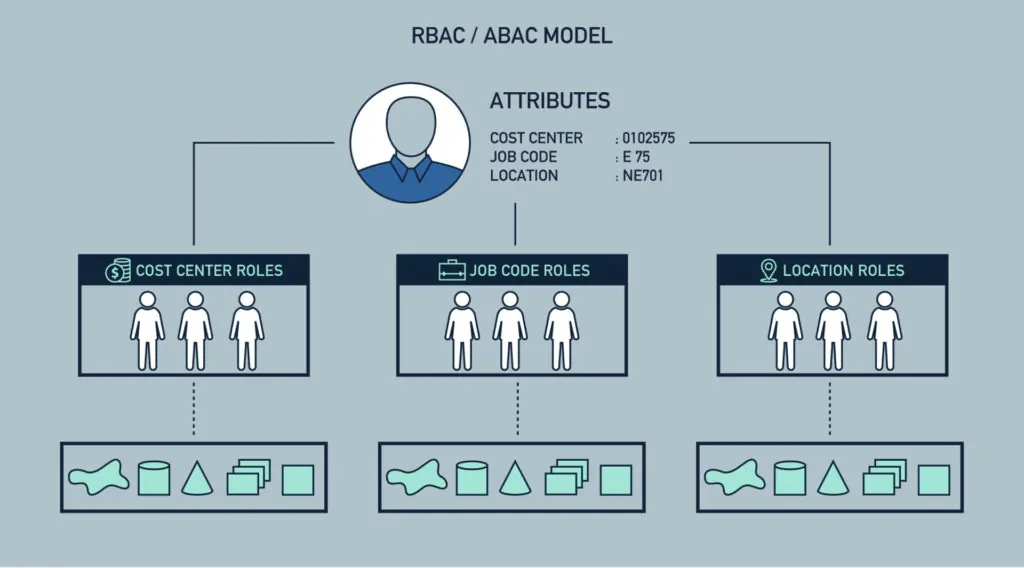
The ultimate step in retaining crawled information includes building up robust data access and management protocols. It guarantees that authorized users can associate with the stored information productively and securely. Proper access control is crucial for securing sensitive data and keeping up information integrity. Executing role-based access control (RBAC) permits you to characterize particular authorizations for distinctive user roles, restricting access to, as it were, the essential data.
Furthermore, building an interface or utilizing APIs can encourage simpler interactions with the stored information. A well-designed API permits designers and applications to query, elevate, or delete information without directly getting to the database, heightening security and convenience.
Information administration practices incorporate regular monitoring and reviewing of information access logs to guarantee compliance with information governance policies. It’s moreover critical to preserve documentation on data structures, access strategies, and utilization guidelines to help users understand the way to interact with the information viably.
For case, utilizing Flask or Django in Python can aid in creating a web interface or Restful API for overseeing and accessing your crawled information.
The following code involves Basic Flask API:
from flask import Flask, jsonify, request
import sqlite3
app = Flask(__name__)
# Function to get data from the database
def get_data():
conn = sqlite3.connect(‘example.db’)
cursor = conn.cursor()
cursor.execute(“SELECT * FROM crawled_data”)
data = cursor.fetchall()
conn.close()
return data
@app.route(‘/data’, methods=[‘GET’])
def retrieve_data():
return jsonify(get_data())
if __name__ == ‘__main__’:
app.run(debug=True)
The implementation of these access and management procedures lets you create a reliable system for users to communicate with the crawled information, making sure that it remains secure, proficient, and simple to utilize for examination and decision-making. This all-around practice increases the value derived from the information gathered through web crawling.
Conclusion
In conclsuion, managing crawled data does not only involve technical operations but also involves significant decisions about the security, accessibility, and performance optimization of that data. With the enlargement of data quantity, its security becomes more critical, to be specific when the data contains sensitive content. That’s why the implementation of vigorous security measures, as well as encryption and access control, all become imperative to secure data from unauthorized access or other casualties. By considering these factors, you enhance the productivity of your web crawling, making sure that essential data is gathered and stored securely for further analysis or business operations.
