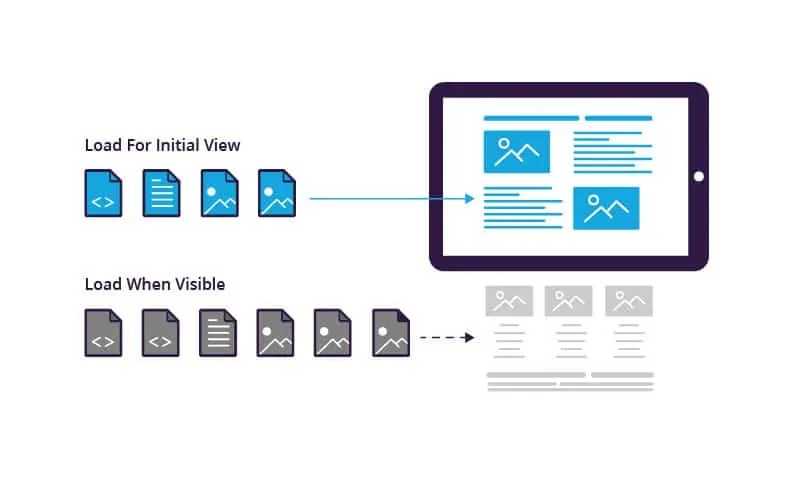
How To Scrape Lazy Loading Websites
The lazy loading strategy is commonly employed by websites today and is related to performance optimization by only loading the content that is visible on the screen. The other parts of the content only load on user interactions, like scrolling and clicking, with the page. Though lazy loading is beneficial on a user’s behalf since it speeds up the loading of page data, it is a tremendous challenge for web scrapers. As a result, the conventional scraping strategies fall short of grabbing content from those dynamic sites. To scrape lazy loading sites, one needs to go beyond merely fetching the HTML. It requires simulating user behaviour, like clicking or scrolling the specific elements to trigger content loads. Using the appropriate techniques and utilizing the right tools, scraping lazy-loading sites is no longer a nearly impossible task. Developers can use the Selenium, Puppeteer, and Playwright libraries to mimic human user behaviour, including clicking, scrolling, and waiting for loading. The following steps of this blog present the comprehensive process of using these libraries efficiently to retrieve dynamic content from a lazy-loading website.
Step 1: Understanding The Website Structure
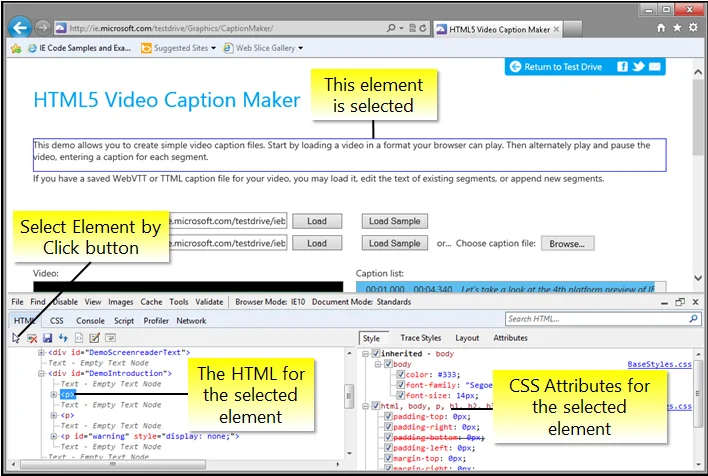
The first step to effectively scrape information from a lazy-loading site involves understanding the way its content is loaded. Lazy loading often happens when content is dynamically infused into the page as the user scrolls or after particular activities, such as clicking buttons or loading particular areas.
Begin by opening the site in a browser and utilizing Developer Tools or using the F12 key to examine network activity and analyze HTTP requests. Within the Network Tab, search for XHR (XMLHttpRequest) or fetch requests that provide the content without reloading the page. Look at the Response for data, usually in JSON format, which is then rendered dynamically.
Determine any API endpoints or endpoints that yield the data you want to scrape. Review how the site triggers new data like scroll, button click, etc. and inspect for any JavaScript events such as window.scroll or button interactions that might trigger content loading.
By comprehensively analyzing that behaviour, you will know when and where to apply your scraping strategies to gather dynamic content effectively.
Step 2: Identifying The Trigger Moves
Once you are done inspecting how lazy loading works on the site, the second step is to recognize what initiates the content load. Lazy-loaded websites regularly depend on particular activities, like scrolling, clicking, or different user interactions, to load new content.
You can easily check whatever happens during these events within the browser’s Developer Tools. In case content loads as the user scrolls, you will presumably notice changes within the Network tab when new information is fetched, triggered by scrolling down or activating a Load More button. For further interaction-heavy websites, these triggers might also apply by clicking a specific element or coming to the bottom of the page.
See for patterns in how the content shows up. Is it bonded to the scroll position of the browser, or does the page issue requests after you press a Next button? In case you are dealing with a more complicated website, assess the JavaScript code on the page, particularly functions bound to user activities such as onclick or onscroll, which specifically invoke the content load.
After you know the triggers, you’ll be able to simulate these activities in your code for a programmatical loading of the content you require.
Step 3: Setting Up Your Environment To Enable JavaScript Execution
Scraping lazy-loaded websites requires tools to render dynamic content by reenacting browser behaviour. Libraries such as Selenium, Puppeteer, or Playwright are perfect for dealing with JavaScript-rendered content. They regulate browser conditions and empower content loading as if a genuine user is browsing.
In the third step of your scraping process, you have to establish your environment to enable JavaScript execution. Tools such as Selenium can interact with the page, letting the content load as it could be in an actual browser. To begin with, install fundamental dependencies for tools, including Selenium or Puppeteer.
The following code demonstrates the way you’ll set up Selenium with Python to load the page and prepare for dynamic content rendering:
from selenium import webdriver
# Set up the WebDriver
driver = webdriver.Chrome() # Use Chrome driver
driver.get(“https://example.com”) # Open the target URL
# Wait for the page to load fully (if required)
driver.implicitly_wait(5) # Adjust wait time as per page loading speed
The above code unlocks the browser and loads the page, enabling the rendering of the dynamic content. From here, you’ll move to reenacting activities, such as scrolling or clicking buttons to load additional information, as clarified within the subsequent phase.
Step 4: Automating User Interactions
To thoroughly scrape dynamic content, you ought to mimic activities that activate the lazy loading. For those sites that load content by scrolling or by clicking a Load More button, you’ll automate these activities in your script. It is pivotal for triggering additional data fetches that would be otherwise missed during a single page load.
To mimic scrolling, you can utilize commands to drive the page down steadily, imitating a genuine user’s behaviour. It will guarantee that the content loads while you scrape; likewise, on the off chance that content loads after you click a button, you can utilize your scraper to programmatically activate those clicks.
The following is a code example of scrolling and loading more content utilizing Selenium:
import time
# Scroll the page to the bottom
driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”)
# Wait for new content to load
time.sleep(3) # Adjust the time for content to load
If it’s about Load More buttons, you will automate the click activity as given in the following example:
# Locate the “Load More” button and click it
load_more_button = driver.find_element_by_xpath(“//button[text()=’Load More’]”)
load_more_button.click()
time.sleep(3) # Wait for content to load
With the automation of these interactions, you’ll be sure that all dynamic content is loaded, preparing it for extraction.
Step 5: Extracting The Relevant Data
After the dynamic content is loaded through recreated actions, including scrolling or clicking, the fifth step is to extract the pertinent information. In this step, you may utilize CSS selectors, XPath, or other focusing strategies to identify and extract the loaded components from the page.
Review the components that were dynamically loaded and utilize the suitable strategy to capture the data. Tools such as Selenium lets you look for components on the page utilizing their attributes, classes, IDs, or even custom properties.
The following code is about extracting text information from dynamically loaded elements with Selenium:
from selenium.webdriver.common.by import By
# Locate the loaded elements using class name or another selector
content_elements = driver.find_elements(By.CLASS_NAME, “content-class”)
# Extract and print the text from each element
for element in content_elements:
print(element.text)
For more progressive use cases, you’ll need to extract particular attributes, such as image URLs or data from structured elements, such as tables or lists. Make sure that you handle cases where data can be missing or not loaded yet by executing waits or error handling to make the scraping more vigorous.
Step 6: Setting Up A Loop Or Repeat Mechanism
To scrape all the dynamically loaded content, you ought to automate the data loading and extracting process. This final step includes setting up a loop or repeat mechanism to guarantee that as long as new information is loaded, the scraping proceeds.
For sites that keep multiple pages or infinite scrolling, automation is critical. Once each action, like scrolling or clicking Load More, the script ought to check if new content has been added and if more actions are required to proceed with loading additional information. It will guarantee that each page or segment of content is captured.
The following is an illustration that repeats the scrolling and clicking activities until no more content is accessible:
while True:
try:
# Scroll or click “Load More” to trigger additional content loading
driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”)
time.sleep(3) # Wait for content to load
# Extract the new data
content_elements = driver.find_elements(By.CLASS_NAME, “content-class”)
for element in content_elements:
print(element.text)
# Check if ‘Load More’ button still exists, if so, click again
load_more_button = driver.find_element(By.XPATH, “//button[text()=’Load More’]”)
load_more_button.click()
time.sleep(3) # Wait for more content
except Exception as e:
print(“No more data to load:”, e)
break
By repeating the scrolling or clicking activities, your script can proceed to get information till there is no more content to load, confirming comprehensive scraping.
Conclusion
In conclusion, lazy loading is a widespread and typically used approach to loading resources only when the user requires them. By loading specific details only when necessary, a website can lessen the time it takes for the primary content to load. Infinite scrolling is a prime instance of a page loading slowly. Scraping lazy loading pages with simple HTTP queries can be tricky since the page only loads fresh content when you reach the bottom. Nevertheless, developers can efficiently scrape data from websites that load slowly by using automation-facilitating tools like Playwright, Puppeteer, and Selenium, as well as an applicable process like the one highlighted above.
