
How To Scrape AJAX Content With Scrapy-Splash
AJAX comprises a set of technologies used in website development that increases the responsiveness of web applications to user interaction. The browser communicates with a remote server whenever a user interacts with a web application. Pages can reload as a result of data transmission, disrupting the user experience. Web apps often use AJAX to send and receive data in the background, allowing only specific areas of the page to refresh when essential. Though it becomes a bit challenging to scrape websites based on AJAX layout, thus the process demands an effective tool. Scrapy-Splash is one of those tools that helps users scrape dynamic content from such sites with much more ease as compared to traditional scraping tools. It contains a compelling blend of Scrapy frameworks and the Splash rendering service. Scrapy and Splash in combination make it easy to offer organizations better access to AJAX-based web content for simple, speedy workflow, especially in large-scale web scraping tasks. Let’s proceed with the detailed steps to scrape AJAX content with Scrapy-Splash.
Step 1: Setting Up The Integration Of Scrapy And Splash
The first step to scrape AJAX content is to integrate Scrapy with Splash, a JavaScript rendering service. To begin with, install the scrapy-splash library and make sure that you have installed Docker to operate Splash. Initiate the Splash server with the command as mentioned below:
docker run -p 8050:8050 scrapinghub/splash
Within your Scrapy project’s settings.py, include Splash middleware and configure essential settings. Look into the following code:
DOWNLOADER_MIDDLEWARES = {
‘scrapy_splash.SplashCookiesMiddleware’: 723,
‘scrapy_splash.SplashMiddleware’: 725,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’: 810,
}
SPIDER_MIDDLEWARES = {
‘scrapy_splash.SplashDeduplicateArgsMiddleware’: 100,
}
DUPEFILTER_CLASS = ‘scrapy_splash.SplashAwareDupeFilter’
HTTPCACHE_STORAGE = ‘scrapy_splash.SplashAwareFSCacheStorage’
SPLASH_URL = ‘http://localhost:8050’
With that setup, Scrapy can pass requests to Splash, empowering you in rendering and scraping JavaScript-heavy pages viably. Continue with an essential spider set-up to try the connection.
Step 2: Installing And Configuring The Splash Server
Before you integrate Scrapy with Splash, you have to install and run the Splash server. The best way to establish Splash is through Docker. If you do not have Docker, to begin with, install it on your device.
For installing and running Splash, you can utilize the Docker command as follows:
docker run -p 8050:8050 scrapinghub/splash
It will drag the Splash image from Docker Hub and begin the Splash service on port 8050. make sure that your Splash service is operating accurately by going to http: //localhost: 8050 in your web browser. You would notice a Splash interface affirming that the server is in form.
In case you need to utilize the Splash server in a cloud environment, you’ll deploy it through a hosting service such as Scrapinghub, where you’ll get a dedicated endpoint. To alter your Scrapy project for remote utilization, simply upgrade the SPLASH_URL in your settings.py file with the URL given by the cloud host.
After the server is established and running locally or remotely, you can continue to configure Scrapy to work with Splash.
Step 3: Setting The SplashRequest
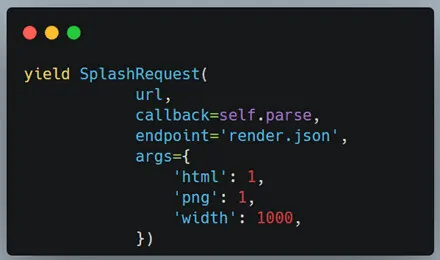
In Scrapy, you have to replace the default scrapy.Request with SplashRequest while scraping AJAX-heavy content. SplashRequest is planned to operate dynamic pages that need JavaScript execution.
To begin with, import SplashRequest at the top of your spider file, using the following code:
from scrapy_splash import SplashRequest
After that, adjust the start_requests() strategy in your spider to start a request through Splash. Indicate the target URL and determine a callback strategy to process the response after the rendering of the page. Look at the following code:
def start_requests(self):
yield SplashRequest(
url=’https://example.com/ajax-content’, # The page you want to scrape
callback=self.parse, # The method to handle the response
args={‘wait’: 2} # Wait time to ensure the page has fully loaded
)
In the above code, args={‘wait’: 2} guarantees that the Splash server holds up two seconds for JavaScript content to load before it continues with rendering. You can also alter the wait time as required, according to the AJAX loading time of your page.
Presently, when Scrapy forms that request, it’ll inquire Splash for rendering the page first before proceeding on to the following step.
Step 4: Tailoring The Splash Behaviour Utilizing Lua Scripts
For handling AJAX requests more sufficiently, you can tailor the Splash behaviour utilizing Lua scripts. Lua permits you to handle how Splash will render pages and hold up for particular components to load dynamically.
As you dealing with AJAX content, you may need to guarantee that the page fully loads or wait for a specific element such as a button or table to appear. In your spider, you’ll utilize a custom Lua script to achieve this.
An illustration of a Lua script that holds up for the dynamic content to load is as follows:
lua_script = “””
function main(splash)
splash:go(splash.args.url) # Navigate to the page
splash:wait(3) # Wait for 3 seconds to let AJAX content load
return splash:html() # Return the rendered HTML
end
“””
yield SplashRequest(
url=’https://example.com/ajax-content’, # The target page URL
callback=self.parse, # The method to process the data
endpoint=’execute’, # This is required for using Lua scripts
args={‘lua_source’: lua_script} # Pass the Lua script for Splash to execute
)
In the above script, the Lua function will make Splash proceed to the given URL, wait three seconds for AJAX to render the content, and yield the completely rendered HTML. Alter the wait time as required per the speed of the AJAX loads on the page.
Step 5: Extracting Data From Rendered Pages
After Splash has rendered the AJAX content, you’ll now extract the specified information from the fully loaded HTML. Scrapy offers effective CSS selectors and XPath support for data scraping from the rendered page.
Within the callback function you indicated like self.parse, utilize Scrapy’s selectors to navigate the DOM and extract the content you wish. The following is how you can go on:
def parse(self, response):
# Extract data using CSS selectors or XPath
titles = response.css(‘h1::text’).getall() # Extracts all text inside <h1> tags
links = response.css(‘a::attr(href)’).getall() # Extracts all links on the page
# Process or store the extracted data
for title, link in zip(titles, links):
yield {
‘title’: title,
‘link’: link
}
In the above example, the response.css() strategy extracts the content utilizing CSS selectors. You’ll be able to alter this according to your page structure. You will Utilize getall() to retrieve all coordinating elements.
Loop through the extracted information and produce the results as a dictionary or process them further, like saving to a file or database.
That strategy lets you handle dynamic, AJAX-rendered data successfully after Splash has handled the page.
Step 6: Running The Scrapy Spider And Analyzing The Output
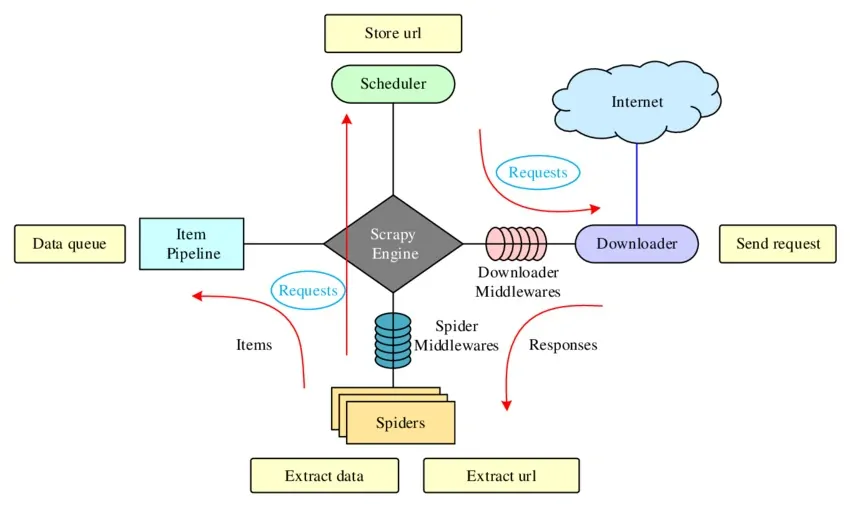
After the setup is over and you have written your spider, the ultimate step is to run the Scrapy Spider and analyze the output. This process will permit you to gather and audit the scraped information.
Running the Spider
Utilize the taking-after command within the terminal to initiate the Scrapy spider:
scrapy crawl your_spider_name
You need to replace your_spider_name with the genuine title of your spider.
Outputting Data
By default, Scrapy yields the extracted information within the terminal. Moreover, You can export it to a file, like a CSV or JSON file, by including an export argument, using the code:
scrapy crawl your_spider_name -o output.json
It will save the data in output.json within the present directory. You can utilize other formats including .csv or .xml per your needs.
Analyzing the Outcomes
Once done with scraping, review the output to make sure that the required data was captured accurately. In case something is lost, follow the following tips:
Confirm that Splash had sufficient wait time to render AJAX content.
Recheck CSS selectors and Lua scripts for precision.
Review whether any anti-scraping measures are influencing the extraction.
Alter your spider or Lua script in case vital to tune the method and capture the data as needed.
Finally, the whole process is complete. You can polish it as required based on the specifics of the websites you are scraping.
Conclusion
To conclude, the effectiveness of any web scraping process depends on the scraping tool’s ability to avoid anti-bot detection. By combining Splash and Scrapy, one can take advantage of Scrapy’s proxy rotation functionality to go around blocks. It is a tremendous tool for huge dynamic content extraction from AJAX-based websites. In the end, developers can create strong and effective web scraping solutions by integrating Scrapy and Splash while adhering to a structured approach like the one addressed in the above blog. It has never been simpler to scrape AJAX content websites, but advanced frameworks like Scrapy-Splash make it effortless.
