
Web Scraping Challenges eCommerce Businesses Should Know About
We all know that data is imperative to web scraping. Data is an important force that helps to drive business-centric and knowledgeable decisions. It has become a common practice nowadays to multiply eCommerce data via web scraping. But do you understand the science behind data extraction and collection of target information? If not! Then by the end of reading this blog, you will develop better know-how about web data scraping. In data scraping, things can go smoothly at one time and can go all wrong the very instant. This is why it is very essential to talk about common challenges that if not handled properly can raise a ruckus.
4 Challenges of eCommerce Web Scraping
The internet is a global hub of information that can be used to gather information anytime and anywhere. But due to the data undefined boundaries, it may take days to get to the needed information. To solve data collection-related issues web scraping tools are used today. It is an effective medium to get your hands on unstructured data without spending a huge sum of money. Ergo, it is easier to lose your way ad make mistakes if you do not have professionally sound knowledge consulting web scraping dos and don’ts. Many businesses trade compromise data quality over quick speed. You must avoid this practice as unstructured or inaccurate data can have serious repercussions on your business partnership. To avoid losing good data, you must be aware of the following mentioned 4 web scraping challenges and prepare yourself in advance.
1. Changing Website Formats
Web pages are structured in an interconnected manner. It is due to the diverse page design standards that can grasp as much information as possible within the compact form. These web pages are updated every other minute leading to a shift in their structural elements from time to time. Owing to this fact web crawling of these web pages can result in incomplete or unstructured data collection. Not all websites allow easy data access the web pages are flooded with sloppy codes of various kinds. Be it character encoding challenges or broken javaScript issues. Such problems can sabotage your scraper out of the blue.
When you own a web data extraction service providing company at a larger scale these problems arise without check. Always keep in your mind –
- Websites will change now and then
- Code issues will pop up more frequently than you’d like
- Scrapers will be lost to either changing codes or broken elements
Reputed data outsourcing companies double-check their tools and software to beat such challenges. They monitor the data in real-time to pinpoint the exact red flag. It is important to perform checks to skim out weak, inconsistent or unnecessary data and retouch the web scarper in time. It is wise to be fully prepared for the worse part in case of web scraping a certain number of scraping bots may fail. But if you run data extraction campaigns with leeway in hand then you can fix these challenges in time.
2. Bot Access, Captcha, and Traps
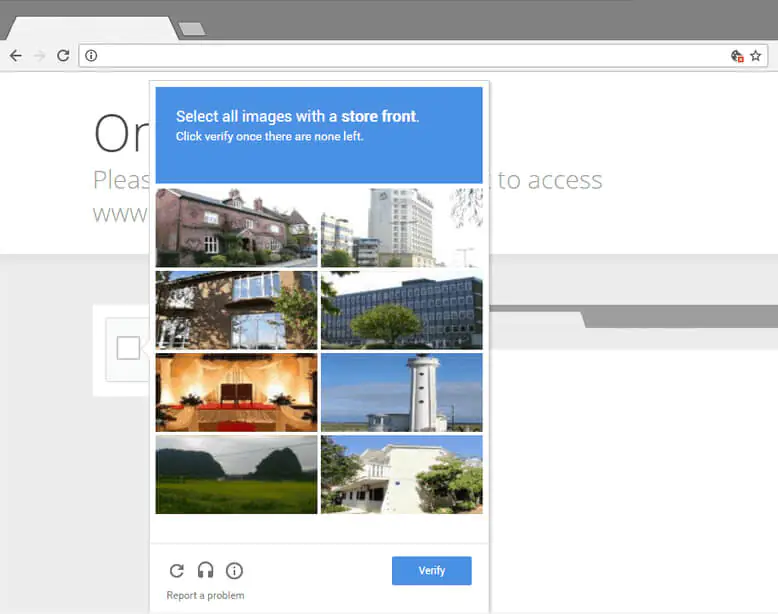
In anti-scraping technology, these factors make data collection even more difficult. Amazon and LinkedIn are popular examples that make use of sophisticated anti-bot measures to reduce intruders from scraping data. Some websites tend to refuse bot access, use an IP blockage mechanism to detect an unusual number of requests from any single IP address, while some others use CAPTCHA which can easily distinguish between a human and a scraper.
You will come across a few Honey-Pot pages during the data extraction process. These are straightaway traps that are set that no human will feel the need to access but a bot would. Since they can open all the links present within a web page. All you need is a scraper that can efficiently work around these preset boundaries. Try using Proxy IPs when scraping on a larger scale. Employ session management and IP rotation for a smooth web scraping experience. Implement a good blacklisting logic to avoid getting your bot from being blocked. Try not to use scriptable headless browsers to access web pages in excess. This is because JavaScript is used by many anti-scraper codes to separate humans from bots. Therefore, a scriptable headless browser will expose your web scraper.
3. Crawling Efficiency
Once you encounter the above-mentioned two problems that means you deal in web scraping at scale. Now data efficiency can become the next roadblock in the process. While performing data extraction at such a larger scale it becomes essential to maintain optimal performance. In an ideal scenario, the crawling strategy must involve minimum manual effort. The scraper must be able to gather information within an estimated time frame without disrupting the quality of the data. To achieve such perfect results, distractions must be kept under constant notice like data extraction requests. Otherwise, the request cycle will increase and scraper performance will decrease. To enhance your crawler potential you must deploy your crawler across multiple servers instead of a single server. Make use of appropriate tools to extract data sets and eliminate any sort of data duplication. Reduce time for crawl stats metadata by optimizing database queries.
4. Data Quality

Data quality is the most crucial part of web scraping. It becomes challenging to maintain data quality maximum while gathering millions of data points a day. All collected data is within the unstructured format. It is also necessary to perform data conversion right after data collection. When data is obtained from several different sources it becomes vulnerable to impurities and complexities. However, manual monitoring solely is not enough to get 100% quality data as well. To detect duplicate entries, false entries, or inaccurate data we must use software tools. Data problems can range over –
- Falsified information being returned
- Volume-based problems
- Inconsistent data types
- Ambiguity in data because of website changes
- Junk data being accepted
- Data and product validation issues
It is the responsibility of data analysts to ensure data quality is kept up to the mark. This can be achieved by performing data analysis when designing a web scraper bot. An automated system that can monitor data inflow to report any existing data inaccuracies. Note that developing such a system requires money as well as time. It is at times easier to delegate data extraction services to a third party. It proves useful in further breaking down business expenses.
How ITS Can Help You With Web Scraping Service?
Information Transformation Service (ITS) includes a variety of Professional Web Scraping Services catered by experienced crew members and Technical Software. ITS is an ISO-Certified company that addresses all of your big and reliable data concerns. For the record, ITS served millions of established and struggling businesses making them achieve their mark at the most affordable price tag. Not only this, we customize special service packages that are worked upon your concerns highlighting all your database requirements. At ITS, our customer is the prestigious asset that we reward with a unique state-of-the-art service package. If you are interested in ITS Web Scraping Services, you can ask for a free quote!
