How To Use WebHarvy For Visual Web Scraping And Data Extraction
WebHarvy is a visual web scraper that lets you get info from websites with an easy-to-use point-and-click interface. In contrast to conventional scraping tools, WebHarvy does not need code. The website interface allows users to visually choose data components. They simply navigate to the page with the data that needs to be extracted, then click on the necessary data to pick it. WebHarvy is appropriate for intensive data extraction as it can easily handle dynamic webpages, CAPTCHA-protected pages, and paginated material. WebHarvy’s ability to allow users to scrape data from websites with little to no software involvement is one of its key advantages. This indicates the least number of mouse clicks and keystrokes. Therefore, unlike other online data extraction applications, WebHarvy will not ask you if you are trying to capture a single data item or a list of items when you are trying to scrape a list of recurring data items from a web page, such as name, address, email address, price, etc. WebHarvy will intelligently recognize data that repeats. This blog will further proceed with the step-by-step guidelines regarding the use of WebHarvy for visual web scraping and data extraction.
Step 1: Launching The WebHarvy Application On Your PC

The initial stage of using WebHarvy for visual web scraping is about launching the WebHarvy application on your PC. After the program is open, you will be welcomed with a basic interface.
The following activity is to load the target site from which you would need to extract information. That can be effortlessly done by heading to the Start New Project segment in WebHarvy, where you’ll input the site URL into the address bar. Once you have entered the URL, tap on the Browse button to let WebHarvy load the page in its built-in browser.
After the site loads inside the tool, you will be able to see it just like you would in a normal browser. At this stage, you’ll begin identifying the elements that you need to scrape.
The magnificence of WebHarvy is that it automatically identifies and accentuates data elements, including text, images, links, and tables, making it simpler for users to concentrate on what is critical.
Before you proceed with data extraction, hold on to make sure that the site is completely loaded and that all vital components, such as images, tables, or links, are apparent. It will guarantee that WebHarvy can viably recognize patterns and begin the scraping process once you move to the next stage.
Step 2: Inputting The Configuration Mode In WebHarvy
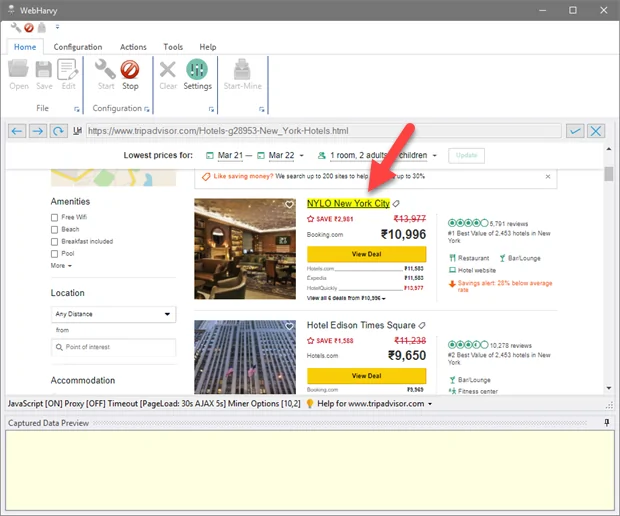
Within the second step, you have to input the configuration mode in WebHarvy. After the website is loaded in WebHarvy, tap on the Start Configuration button. It will switch the tool into a mode where you’ll begin selecting elements from the webpage to scrape.
In the configuration mode, WebHarvy’s interface permits you to interact directly with the content of the website. The tool will underline elements once you approach them, making it simpler to recognize the data you want to extract.
You will also detect that WebHarvy gives visual prompts to direct you through the process. You will simply have to press on the data elements like text, images, or links that you need to scrape. Once you have selected a component, WebHarvy will automatically attempt to catch similar elements over the webpage, which enables in extraction of reliable information.
This stage is critical for mapping out the sort of data to extract and confirming that WebHarvy can reproduce the selection process over different pages of the site.
Step 3: Visually Selecting The Data Elements
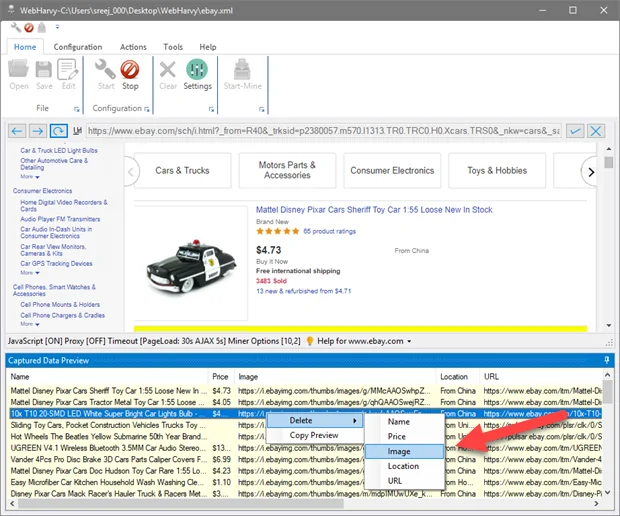
The third step involves visually selecting the data elements you need to scrape from the webpage. After you are in configuration mode, head over to the elements on the webpage. Once you hover, WebHarvy will accentuate the data items it recognizes.
To choose an element, essentially click on it. For example, if you need to scrape text from a product description or an image from a gallery, just tap on the particular thing. WebHarvy will automatically grab that element and display a preview.
While you proceed by clicking on data elements, WebHarvy will comprehend the pattern and specify similar items across the whole page. You will need to tap on multiple items to be sure that all pertinent data is chosen. For instance, if you are extracting product costs, you should press on several product cost elements to aid WebHarvy in recognizing the reliable pattern.
That step will make sure that WebHarvy gets the data you need to extract, making it simpler for the tool to gather similar data from other pages.
Step 4: Applying The Pattern Identification

Once you have chosen the data elements you need to scrape, WebHarvy will consequently identify patterns within the selected data. This implies that once you have clicked on some elements, WebHarvy will identify comparative elements on the webpage and group them according to typical patterns.
For instance, if you choose a product title and price, WebHarvy will recognize that other item titles and costs on the page follow a comparable structure. It will, at that point, automatically highlight and mark these patterns.
You’ll polish the pattern detection by inspecting WebHarvy’s suggestions. As required, you’ll manually alter or add more cases to guarantee that the tool seizes all the vital data points. It will help ensure that no imperative information is missed when the scraping process is carried out.
The pattern detection highlight is a key portion of WebHarvy’s visual scraping capabilities because it permits proficient and precise extraction of data from numerous items over a webpage.
Step 5: Handling Multiple Pages
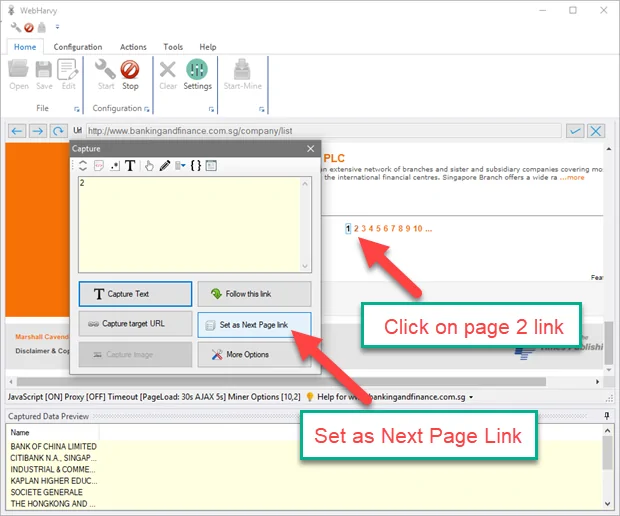
In case the site you are scraping has multiple pages of data, for instance, product listings spread over several pages, you will have to establish pagination in WebHarvy to scrape data from all pages.
WebHarvy permits you to configure the pagination by automatically recognizing the Next or Page button, which is usually utilized to go through the different pages of a website. In configuration mode, WebHarvy will highlight navigation elements such as Next or page numbers.
To put up pagination, simply tap on the Next or pagination button inside the WebHarvy interface. The tool can recognize it as a design and permit you to scrape information from ensuing pages automatically.
On setting up pagination, you can guarantee that WebHarvy will proceed scraping across all the pages of the website, collecting data from each page in a reliable way, without needing you to manually press through each page. This action is particularly supportive for scraping expansive datasets spread over numerous pages.
Step 6: Scraping And Data Export
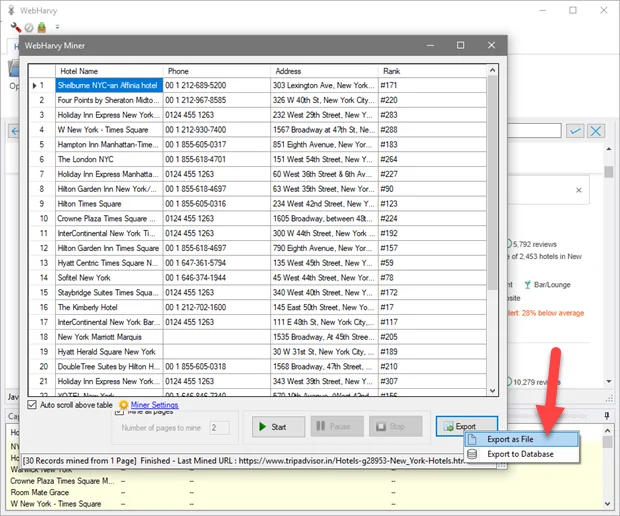
Once you are done with the data elements selection, you will proceed to setting up pagination accordingly. Within the interface of WebHarvy, you will find the Start Scraping option, which you will use to initiate the extraction process.
As a result, you will see that WebHarvy will go on with gathering all data per your established patterns. It collects the specified information from the identified elements across multiple pages while observing the pagination rules. You will also be able to preview the information being extracted in real time.
Once the scraping is executed till the end, WebHarvy will facilitate you to export the content in CSV, Excel or XML based on your requirements. You can consider the format and the saving location as you like.
With the final phase, your data is both efficiently extracted and prepared for further utilization or examination.
Conclusion
To sum up, WebHarvy is an ideal data extraction tool for those who are not technical. It provides a user-friendly visual interface in contrast to conventional online scraping tools that require technical expertise. Users can save time and effort by just pointing and clicking to choose the data they want. WebHarvy allows you to efficiently and productively scrape text data, including names, descriptions, and reviews; images and the URLs that go with them; links; and structured online data. This flexibility in selecting from various data sources implies that users can gather a diverse range of data types to fulfil their needs.
