
How To Scrape eBay Listings Using Python And BeautifulSoup
eBay is the biggest e-commerce platform that upholds millions of products and detailed details, providing diverse datasets. eBay Listings include detailed descriptions of the products in the form of advertisements created by sellers on the eBay site. The key elements of these listings are the product title, images, product information or traits, price, shipping procedure and seller information. Scraping that listing data can provide useful facts regarding product information and market trends, as well as analyze competitors, which is key to a successful business. Utilizing influential tools like Python and BeautifulSoup, users can readily scrap product data directly from the eBay platform, including price, title, description, and relevant links. The integration of the flexible functioning of Python with the potent parsing proficiency of BeautifulSoup makes web data scraping a productive and modifiable process. Nevertheless, scraping eBay listings is not so simple or a free-hand process; it requires cautious handling of HTTP requests, the page’s layout, and anti-scraping measures. For that, you need to employ a detailed framework or precise step-by-step process like the one described in this blog. Following the below-mentioned process, you can effortlessly scrap eBay listings with fruitful outcomes.
Step 1: Installing The Essential Libraries
Set up the environment on your local machine, which is about installing the essential libraries, including the requests to send HTTP requests and the BeautifulSoup library from the bs4 package to parse HTML content.
Download Python and, then, open your terminal or command prompt and install the particular libraries utilizing pip:
pip install requests
pip install beautifulsoup4
Compose your Python script by importing the libraries in your Python code. Here is an example:
import requests
from bs4 import BeautifulSoup
Further, make a new Python file to store your code, such as ebay_scraper.py. Also, confirm that you’re employing a virtual environment to keep dependencies separated.
Ensure a sound internet connection to pass requests to the eBay server.
Step 2: Sending A Request To The eBay Webpage
Now, you have to send a request to the eBay webpage, and you have to scrape it. The requests library in Python permits you to communicate with web pages through HTTP. Particularly, you can utilize the requests.get() function to send a GET request to eBay’s URL and get the HTML substance of the page.
Begin by specifying the URL of the eBay listings page you need to scrape. That can be a category page, a particular search result, or a page of listings from a specific seller.
After accessing the URL, utilize the requests.get() function to create the request, just like the following:
import requests
url = “https://www.ebay.com/sch/i.html?_nkw=laptop”
response = requests.get(url)
The above example depicts the scraping of a page that lists laptops on eBay. The response object includes the complete HTML data of the webpage, like headers, cookies, and the body of the content.
To confirm the success of the request, you’ll print out the response status code. Also, look into the following code:
print(response.status_code)
The status code of 200 implies the request was fruitful. On the other hand, receiving other status codes, like 403 or 404, means you need to troubleshoot by including headers to your request to prevent blocks.
Step 3: Parsing HTML Content
The third step involves parsing HTML content utilizing BeautifulSoup, which permits you to explore and extract particular information from the document.
To begin with, pass the content from the response object into BeautifulSoup. That yields a BeautifulSoup object, which simplifies the searching and overseeing of the HTML structure.
Look into the code mentioned below for parsing the response:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, ‘html.parser’)
In the above code, the response.text has the HTML content of the page returned by the request. The ‘html.parser’ indicates the parser to utilize. BeautifulSoup backs various parsers through html.parser is generally utilized.
After the soup object is created, you can effortlessly go through the HTML. BeautifulSoup proposes various modes to seek components, like find() for single elements or find_all() for all matching elements.
To look at the initial 500 characters of the HTML document, you’ll simply print. Below is an example:
print(soup.prettify()[:500]) # Output first 500 characters
That can provide you with an organized view of the HTML structure, helping you identify the tags and classes that include the data you need to extract.
Step 4: Locating And Extracting Required Data
Locate and extract the specific information you are looking forward to by assessing the HTML structure and focusing on the suitable tags and classes that retain the required data.
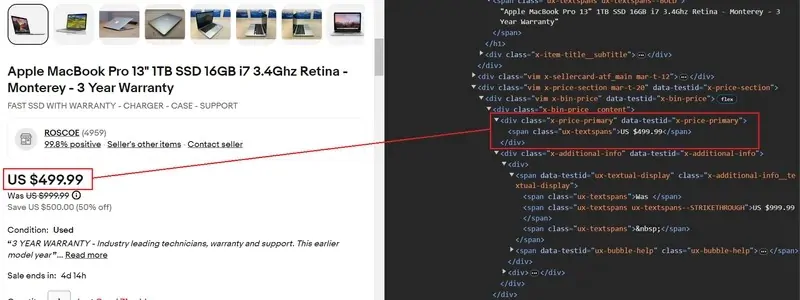
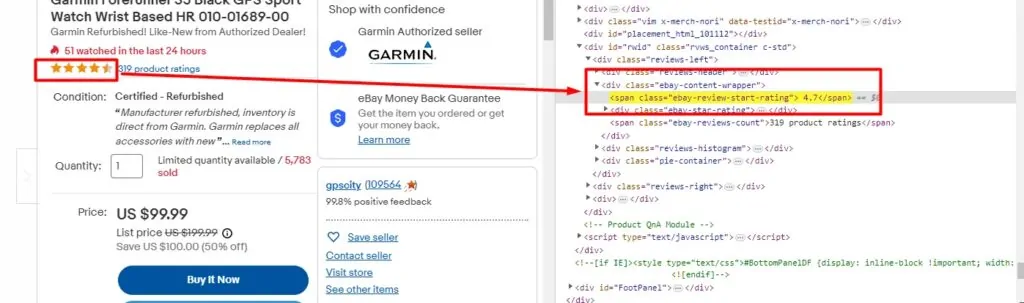
To identify the significant tags, you can utilize browser developer tools by right-clicking on a webpage and selecting “Inspect” to look at the HTML structure of eBay’s listings. Inside eBay’s search results, product titles, costs, and other particulars are usually held inside particular HTML elements like <li>, <div>, or <span> tags, each having unique classes or traits.
For instance, assume the product titles are within tags with the class name s-item__title, and the costs are within tags with the class s-item__price. You can extract these components by using the following command:
# Extract product titles
titles = soup.find_all(‘h3′, class_=’s-item__title’)
for title in titles:
print(title.get_text())
# Extract product prices
prices = soup.find_all(‘span’, class_=’s-item__price’)
for price in prices:
print(price.get_text())
The find_all() will retrieve all elements that correspond to the required tag and class title. The .get_text() can extract the text content from the found element, expelling any HTML tags.
Also, you will need to extract the URLs of the item listings:
# Extract product URLs
links = soup.find_all(‘a’, class_=’s-item__link’)
for link in links:
print(link[‘href’])
That loops through the links and extracts the value of the href attribute, which includes the URL of the particular product pages. With this process, you can grab the necessary particulars for each eBay listing, permitting you to store or handle the data as required.
Step 5: Storing The Scraped Data
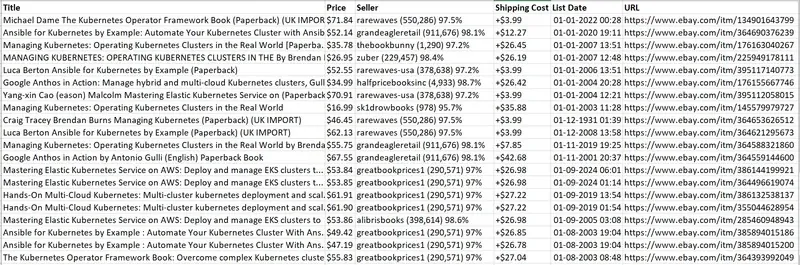
This step is about exploring and utilizing different options to store the scraped data, like CSV, JSON files, or a database. For clarity and easy analysis, we prefer the CSV file to save the data.
To initiate, import the CSV library using the following code:
import csv
After that, you’ll need to structure the extracted data into rows of a CSV by opening a CSV file in write mode and utilizing the csv.writer() to add each piece of data.
To store the information in a CSV file:
# Open a CSV file in write mode
with open(‘ebay_listings.csv’, mode=’w’, newline=”, encoding=’utf-8′) as file:
writer = csv.writer(file)
# Write the header row
writer.writerow([‘Title’, ‘Price’, ‘URL’])
# Write data rows
for title, price, link in zip(titles, prices, links):
writer.writerow([title.get_text(), price.get_text(), link[‘href’]])
The csv.writer(file) will initiate the CSV writer object.
The writer.writerow([‘Title’, ‘Price’, ‘URL’]) will write the header row to the CSV file with column names.
After that, the zip(titles, prices, links) will iterate over the extracted information for titles, prices, and links at once. Each iteration writes a row with the extracted information in the CSV file.
Finally, the .get_text() helps extract the title and price text.
At the end of this step you can get an ebay_listings.csv file that contains the eBay listings with their related titles, costs, and URLs.
Step 6: Dealing With Errors And Anti-Scarping Measures

Move on to handling failed requests, server errors, and strategies to prevent getting blocked or flagged as a bot.
In case of request failure, utilize try-except blocks to catch exceptions and retry or log blunders:
try:
response = requests.get(url)
response.raise_for_status() # Raise an exception for HTTP errors
except requests.exceptions.RequestException as e:
print(f”Error occurred: {e}”)
Set the User-Agent header to imitate a genuine browser by including the header to your request. For instance:
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36”
}
response = requests.get(url, headers=headers)
Add delays between requests to prevent hitting the server too often. You’ll be able to include random delays utilizing time.sleep():
import time
import random
time.sleep(random.uniform(1, 3)) # Delay between 1 and 3 seconds
To scrape big amounts of data, think about utilizing proxy rotation or a pool to distribute requests across multiple IPs and bypass blocks.
Conclusion
In a nutshell, eBay amasses a ton of information that is helpful to researchers, marketers and business owners. eBay data scraping, especially when using tools like Python and BeautifulSoup, allows individuals to obtain contemporary consumer information that they can analyze in any way that best fits the needs of their business. For instance, it assists enterprises in identifying the attributes of popular items so that they may develop new products that conform to these trends. By looking at consumer feedback, they can also gain suggestions for design improvements and ensure that the new articles meet the demands and cravings of the people.
