How To Scrape Data From Single-Page Applications (SPAs)
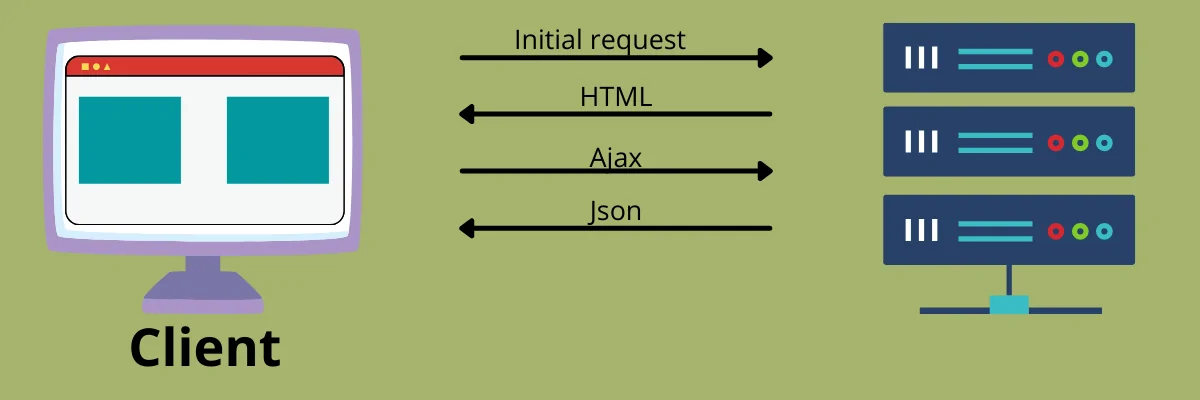
A single-page application, or SPA, loads just one web page and then uses JavaScript APIs to update the document’s body content when different content needs to be displayed. As a result, users may access websites without loading whole new pages from the server, potentially improving speed and creating a more engaging experience. However, when it comes to scraping SPAs, standard scraping tools may not work smoothly as they are made to deal with static web pages. In contrast, single-page apps shift the page and load content dynamically without requiring a page reload. The reason is that the server sends back a static HTML file with some JavaScript code and the SPA’s basic structure anytime a user requests a page. After that, the JavaScript code dynamically creates the page’s content by retrieving data from the server. It suggests that the SPA produced the data we needed to scrape subsequently and was not present in the original HTML file. To extract data from an SPA, we need to use certain techniques and make effective use of scraping tools that simulate user interactions with the website. Here is the detailed process.
Step 1: Examining The Website
Before you proceed to the intricacies of data scraping from a Single-Page Application (SPA), you need to examine how the site loads and exhibits its data. Far from conventional websites that serve static HTML, SPAs can dynamically fetch content utilizing JavaScript, usually via API requests.
Begin by opening Developer Tools in your browser by pressing F12 or right-clicking, then selecting the Inspect option. Head to the Network tab and filter by XHR or Fetch requests. Load the page again, and then see how information is being retrieved. If you catch JSON responses, the site presumably depends on API calls. Record the request URLs, headers, parameters, and authentication strategies.
On the off chance that no API is visible, study the Elements tab to see if content shows up within the HTML when loading. It will suggest that JavaScript renders the information dynamically. In this context, employing a headless browser such as Selenium or Puppeteer might be essential.
Also, review for anti-scraping components like CAPTCHAs, rate limits, or bot-detection scripts. Some sites load information in chunks or utilize infinite scrolling, which mandates additional techniques such as scrolling computerization or AJAX interception.
Step 2: Selecting A Scraping Strategy
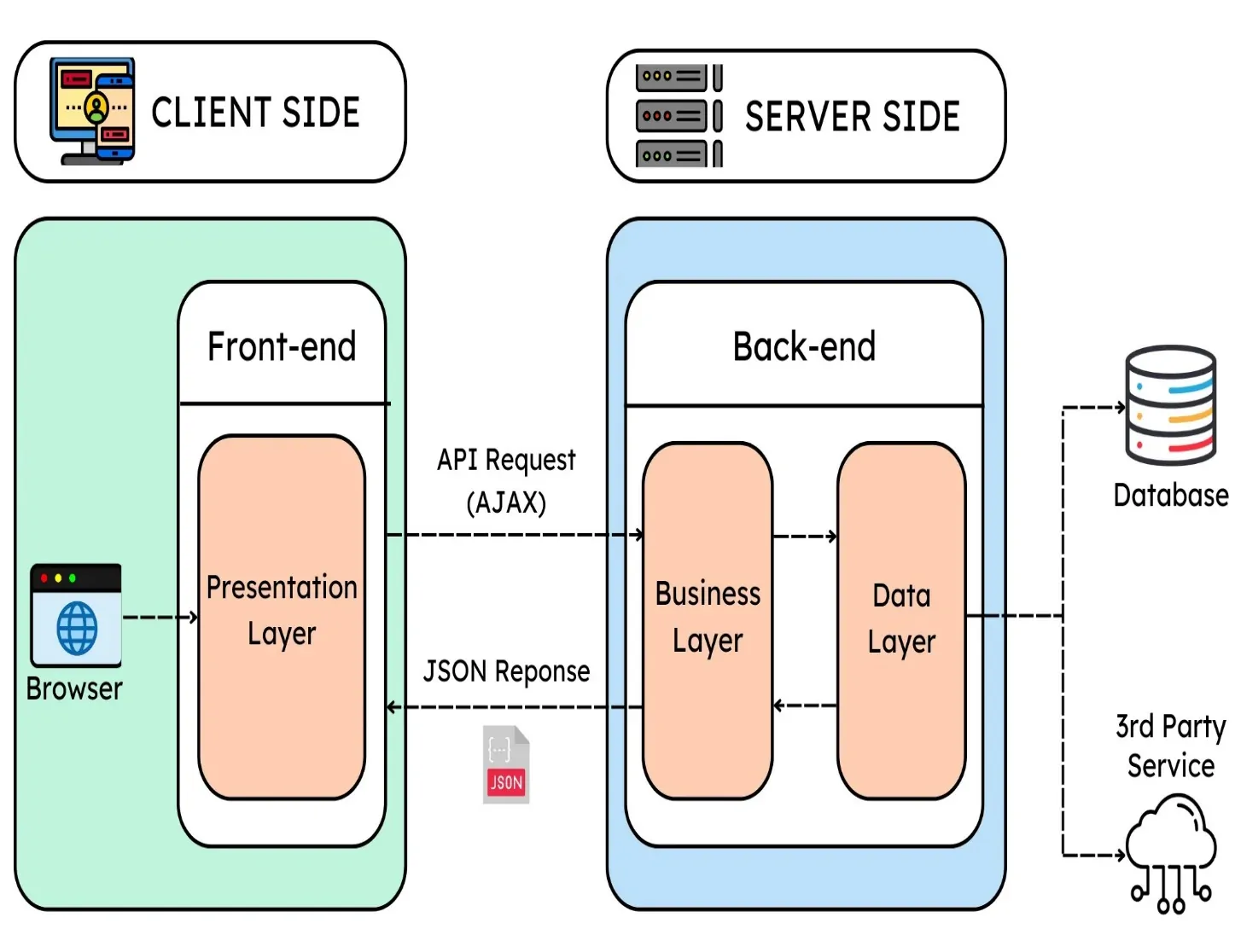
After analyzing the data loading method of a Single-Page Application (SPA), the next step is to select the most compelling scraping strategy. The two fundamental approaches include the use of API requests and JavaScript-rendered scraping.
If the site creates API calls to fetch data, this is often the most productive strategy. So, you will directly send requests to the API endpoints, imitating the browser’s behaviour. Utilize tools such as Postman or Python’s requests library to test the API. Make sure that you incorporate essential headers, authentication tokens, and query parameters. That strategy is speedier and prevents rendering issues, though some websites may need authentication or contain rate limits.

Alternatively, if the data isn’t directly accessible through an API, you will have to render the JavaScript content. Utilize headless browsers such as Selenium, Puppeteer, or Playwright to mimic user interactions. Such tools help you wait for elements to load, click buttons, and scroll dynamically loaded pages. That strategy is more resource-intensive yet operates for SPAs that intensely depend on client-side rendering.
Selecting the correct strategy is based on the site structure. As possible, in any case, prefer API scraping for productivity. or else, headless browser automation will make sure that you are able to extract dynamically loaded information.
Step 3: Setting Up The Fundamental Tools And Libraries
Once you are done choosing the scraping strategy, the following phase is to put up the fundamental tools and libraries. In the case of API-based scraping, you will install Python and utilize libraries such as requests for making HTTP calls and BeautifulSoup to parse HTML as required. If JavaScript rendering is needed, you will install Selenium, Puppeteer, or Playwright.
If using Python, look into the code to install the essential libraries:
pip install requests selenium beautifulsoup4
If you are utilizing Selenium, you can download a WebDriver that is consistent with your browser, like ChromeDriver. If you are employing Puppeteer, you will install it through Node.js like this:
npm install puppeteer
Design your script by indicating headers and user agents to prevent being detected. For example, suppose you are utilizing requests; you will set headers to imitate a genuine browser request. Look into the given example:
import requests
headers = {“User-Agent”: “Mozilla/5.0”}
response = requests.get(“https://example.com/api/data”, headers=headers)
print(response.json())
If you are utilizing Selenium, start a browser instance and hold up for JavaScript elements loading. Here is an illustration:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(“https://example.com”)
data = driver.page_source
driver.quit()
An appropriately designed environment makes sure that you have a smooth implementation of your scraping script, lowering detection troubles and improving proficiency.
Step 4: Extracting The Specified Data
After setting up the essential environment, you have to extract the specified data. If you are utilizing API-based scraping, you will pass HTTP requests to the API endpoints and parse the JSON response. If you are employing a headless browser such as Selenium, Puppeteer, or Playwright, hold up for JavaScript to load the content before you extract.
In the case of API-based extraction, a basic Python script utilizing requests can retrieve data proficiently:
import requests
url = “https://example.com/api/data”
headers = {“User-Agent”: “Mozilla/5.0”}
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
print(data)
In case the data is loaded dynamically by means of JavaScript, Selenium can be utilized to wait for elements and extract content. Here is an example:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get(“https://example.com”)
time.sleep(5) # Wait for JavaScript to load
elements = driver.find_elements(By.CLASS_NAME, “data-class”)
for element in elements:
print(element.text)
driver.quit()
The process of extracting the content may need dealing with AJAX calls, infinite scrolling, or clicking buttons to load further information. In such cases, scroll automation or explicit waits confirm a comprehensive information retrieval. After the information is extracted, it needs to be properly cleaned and stored.
Step 5: Data Structuring And Storing
After data extraction, the fifth step is dedicated to cleaning, structuring, and storing it in an appropriate format. Since raw data frequently contains pointless HTML tags, spaces, or inadequate entries, it must be handled before utilization.
In the case of structured data such as JSON, basic parsing is sufficient. Here is an example.
import json
data = ‘{“name”: “Product A”, “price”: “$50”}’
parsed_data = json.loads(data)
print(parsed_data[“name”], parsed_data[“price”])
If the web scraping is processed with Selenium or BeautifulSoup, the extracted HTML components may need to be cleaned. Consider the following example:
from bs4 import BeautifulSoup
html = “<div class=’price’> $50 </div>”
soup = BeautifulSoup(html, “html.parser”)
price = soup.find(“div”, class_=”price”).text.strip()
print(price)
Once the processing is done, you can store the information in a CSV, JSON, or database. Here is an example of writing a CSV file that is straightforward with Python’s CSV module:
import csv
data = [[“Product A”, “$50”], [“Product B”, “$30”]]
with open(“data.csv”, “w”, newline=””) as file:
writer = csv.writer(file)
writer.writerow([“Product”, “Price”])
writer.writerows(data)
In the case of large-scale projects, storing information in a database such as MySQL or MongoDB is exemplary. It will guarantee easy retrieval and examination. Cleaning and organizing data appropriately makes it valuable for further examination or automation.
Step 6: Addressing Detection Challenges
Since the SPAs scraping regularly includes dealing with issues like CAPTCHAs, anti-bot mechanisms, dynamic content loading, and rate limits. Addressing these needs is key to guaranteeing effective data extraction without getting blocked.
Websites might detect scrapers by checking reiterated requests from the same IP. To prevent that, utilize proxy rotation services such as ScraperAPI or residential proxies. Here is a basic Python example utilizing requests and a proxy:
proxies = {“http”: “http://your-proxy.com”, “https”: “https://your-proxy.com”}
response = requests.get(“https://example.com”, proxies=proxies)
Numerous SPAs utilize CAPTCHAs to jam bots. In case such issues are encountered, services such as 2Captcha or Anti-Captcha can help decipher them. Some CAPTCHAs can also be bypassed by utilizing headless browsers via manual intervention.
In the case of sites that load data via infinite scrolling, you can automate scrolling with Selenium. Check out the following example:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get(“https://example.com”)
for _ in range(10):
driver.find_element(“body”).send_keys(Keys.PAGE_DOWN)
time.sleep(2)
driver.quit()
Dealing with request limits includes setting random delays between requests to imitate human browsing. Utilizing time.sleep() or exponential backoff techniques can minimize the hazard of blocking. Appropriately addressing these challenges guarantees persistent and successful data scraping.
Conclusion
In summary, Single Page Applications (SPAs) are prevailing because of their quick load times and smooth user experience. Nevertheless, conventional procedures might not be enough for web scraping SPAs. You can use the strategies discussed in this blog to scrape data from dynamic online applications for a variety of uses, including data analysis, monitoring, and creating your own web services. Also, keep in mind that online scraping may be complicated from a legal and ethical standpoint. You should always abide by the terms of service of the website you are scraping to ensure effective outcomes.
