How To Handle CAPTCHAs With Machine Learning
CAPTCHAs are globally utilized security measures that are designed to head off automated bots to access online services. They prompt people to solve puzzles or tasks before proceeding to interact with a particular website. CAPTCHAs challenges are those that are difficult for bots to go through but typically easy for humans to accomplish. CAPTCHAs were initially created to stop bots from automatically completing forms by confirming that you are a human, but they get bothersome when you need to interact with websites overly frequently. Nonetheless, you can now readily overcome them with the development of machine learning and vision. In order to handle a Captcha, we need to train a machine-learning model. When the model is trained, all we have to do is feed it any CAPTCHA, and it will instantly solve it for us. This blog will cover in deeper detail how machine learning is used to handle CAPTCHAs effortlessly.
Step 1: Collecting And Preprocessing Data
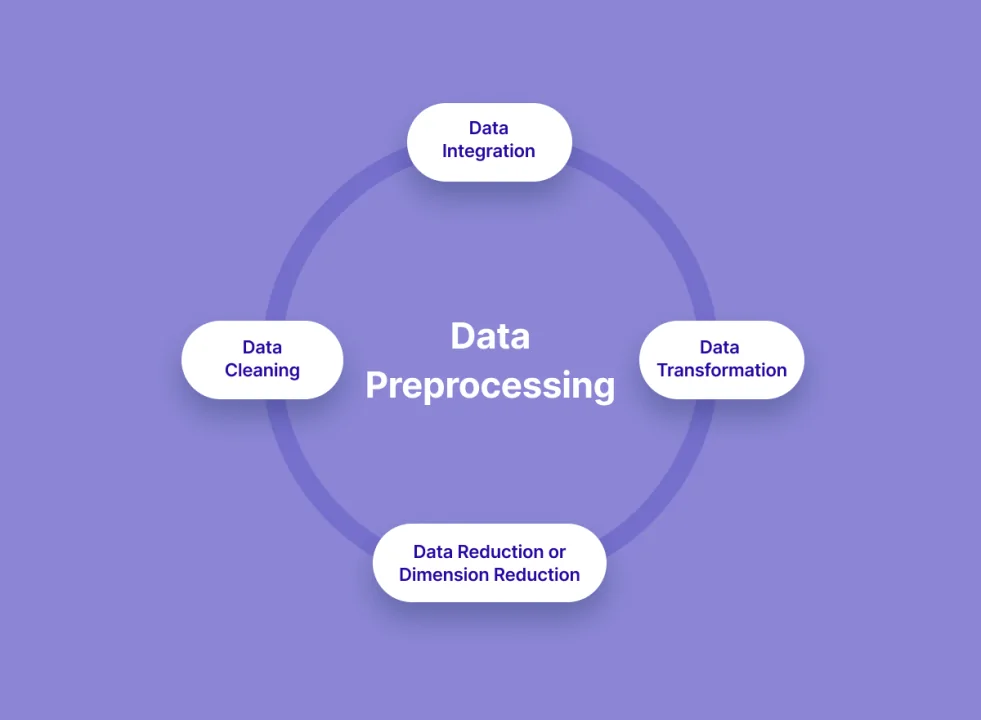
The initial step in handling CAPTCHAs with machine learning is to assemble a differing and comprehensive dataset of CAPTCHA images. As CAPTCHA plans shift broadly from distorted content and overlapping characters to image-based perplexes, it is fundamental to incorporate a variety of styles to assist the model in generalizing. That assortment trains the model to identify patterns over different CAPTCHA formats, making it more versatile for distinctive cases.
After the information is gathered, preprocessing is essential to clean and standardize the pictures. It frequently includes resizing images to a reliable measurement, changing them to grayscale for less complex processing, and expelling noise, like lines or foundation patterns, that may meddle with precise character recognition. Preprocessing also incorporates sectioning CAPTCHA pictures, which implies isolating individual characters or objects inside each CAPTCHA.
This step is significant because it streamlines the dataset and empowers the model to center on the core components without pointless diversions. Appropriate data collection and preprocessing lay the foundation for proficient model training and precise CAPTCHA handling.
Step 2: Labeling And Classifying Data
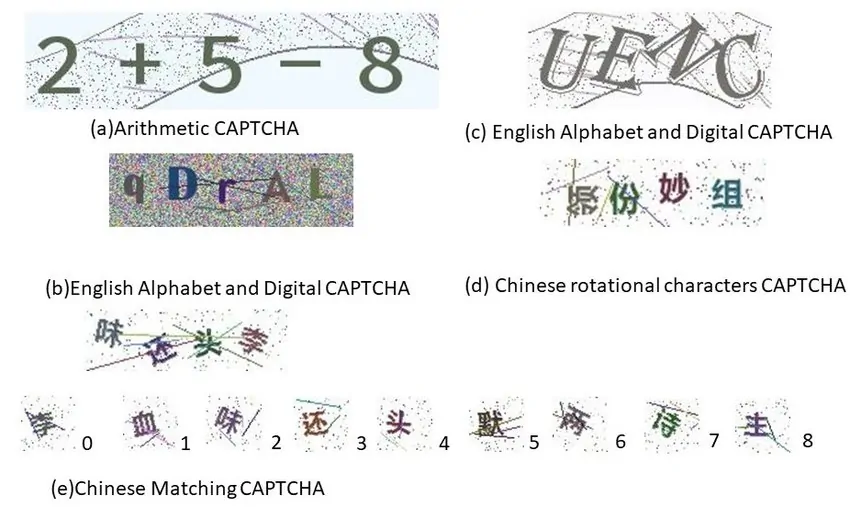
Once done with collecting and preprocessing the CAPTCHA images, the following step involves labeling and classification. Labeling includes labeling each character or object inside the CAPTCHA pictures so that the model can learn to catch and classify them precisely. This can be a significant step since well-labeled information empowers machine learning to relate particular designs with adjusted yields, progressing its capacity to anticipate characters or objects in unseen CAPTCHAs.
For text-based CAPTCHAs, each character inside the picture must be labeled exclusively. For image-based CAPTCHAs, like those needing users to recognize particular objects like cars, traffic lights etc, each object ought to be labeled agreeing to its class. Automated labeling devices can accelerate this process, in spite of the fact that manual verification is often essential to guarantee precision, particularly when dealing with complex or extremely distorted CAPTCHA styles.
After being done with the label thing, the data is all set for classification, empowering the model to gather comparative patterns and highlights. Precise labeling and classification are critical for the model to successfully “learn” and catch CAPTCHA components in the ensuing steps.
Step 3: Choosing A Proper Model
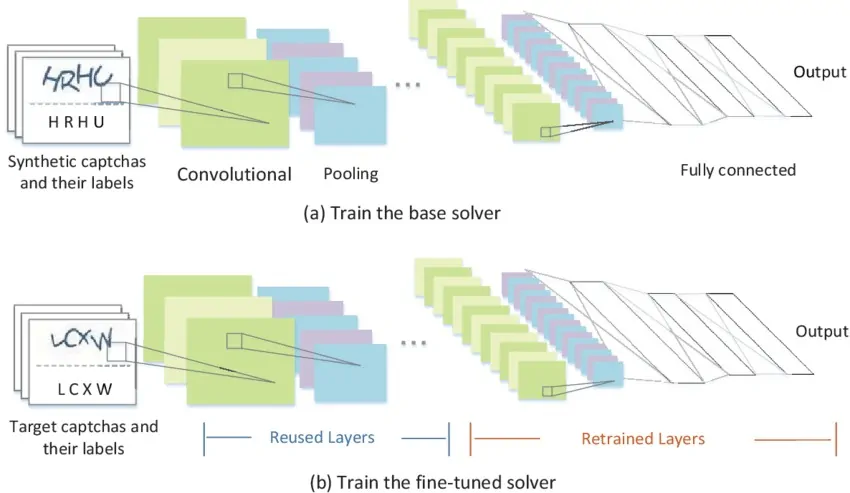
While dealing with CAPTCHAs, choosing the proper machine learning model could be a vital step. Considering that CAPTCHAs are usually visual in nature, models that excel in image recognition errands are typically valued. Convolutional Neural Networks (CNNs), recognized for their ability to identify patterns and highlights in images, are a prevalent option because of their proven success in identifying and categorizing visual data. CNNs can viably catch CAPTCHA components, including distorted text characters or particular objects in image-based CAPTCHAs.
Selecting the architecture inside CNNs relies on the complexity of the CAPTCHA dataset. For less complex text-based CAPTCHAs, an elementary CNN model could be adequate, while more complex, multi-layered CAPTCHAs may need a deeper model with progressed layers like ResNet or VGG architectures to capture complicated patterns. Transfer learning can also be useful, where a pre-trained model on a huge picture dataset is tuned for CAPTCHA recognition.
Compelling model choice sets the basis for high recognition precision, specifically affecting the model’s capacity to handle CAPTCHAs with exactness.
Step 4: Train The Model
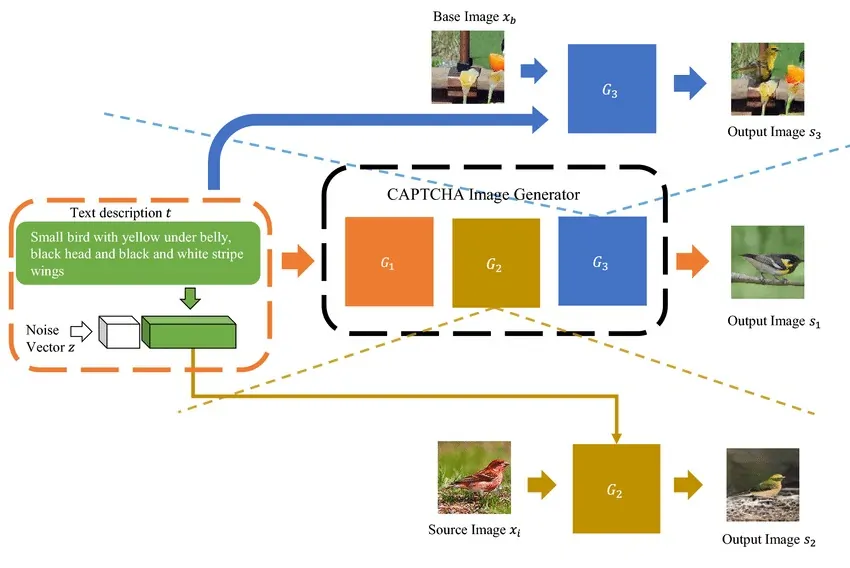
The step involving the training of the model is where the machine learning algorithm learns to note patterns within the CAPTCHA data. At this stage, the preprocessed and labeled dataset is input into the chosen model like a CNN in an organized way, allowing it to alter its internal parameters to create precise predictions. Amid training, the model iteratively examines each CAPTCHA image, identifying and recognizing highlights such as shapes, edges, and distortions specific to each character or object.
The training process includes numerous epochs, where the model makes forecasts, gets feedback on its precision, and, after that, alters itself to improve. To assist the model in preventing overfitting, which implies the stage where it performs better on training data but ineffectively on new information, strategies like data augmentation, e.g., rotating or distorting pictures, can be utilized. Moreover, optimization procedures like gradient descent and backpropagation fine tune the model’s weights for way better execution.
Effective training permits the model to create a vigorous capacity to recognize and translate CAPTCHA images, establishing it for precise taking care of in real-world applications.
Step 5: Performace Validation And Testing
After training the model is done, it is fundamental to validate and test its execution on CAPTCHA images that it has never seen before. Validation includes employing a portion of the data set apart from the training process to assess the model’s capacity to generalize its learning. This step helps to distinguish any overfitting and makes sure that the model functions evenly on different CAPTCHA types.
Once done with validation, testing on a separate, unseen dataset is significant for evaluating the model’s adequacy in real-world contexts. This testing stage gives a practical degree of the model’s precision and highlights zones where it may struggle, like with particularly complex or bizarre CAPTCHA designs. Performance metrics, including accuracy, precision, and recall, are usually utilized to measure how well the model is interpreting CAPTCHAs.
By tuning the model in view of validation and testing results, we will improve its execution, making it more solid and exact in bypassing CAPTCHAs. This step is vital to guarantee robust handling over differing CAPTCHA styles.
Step 6: Deploying The Trained Model
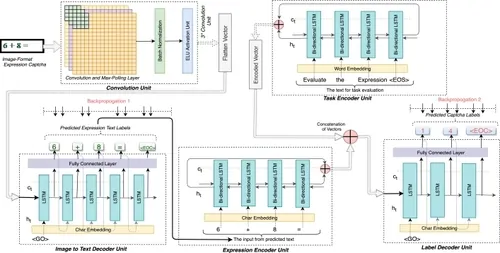
The ultimate step is deploying the trained model for real-time CAPTCHA handling and persistently assessing its performance. Deployment usually includes joining the model into an application or framework that can handle incoming CAPTCHA pictures in real-time. That may incorporate setting up an API or utilizing cloud services to handle high volumes of CAPTCHA information proficiently. Amid deployment, it is important to screen the model’s response time and precision to ensure it fulfills performance necessities.
Persistent assessment is key, as CAPTCHA designs often develop to combat machine learning-based circumvention. By frequently evaluating the model’s precision with new or altered CAPTCHA samples, any error in performance can be recognized in time. When essential, retraining the model with updated datasets keeps it compelling against shifting CAPTCHA formats.
Deployment and continuous assessment permit a dynamic, versatile framework that can reliably interpret CAPTCHAs, giving insights into its qualities and impediments in handling real-world security cases.
Conclusion
In summary, the use of machine learning to deal with CAPTCHAs is an effective strategy that shows how AI can effectively be used to address real world problems. With the careful implementation of techniques like data collection, model selection, model training, and model evaluation, you can benefit from machine learning no matter how complicated CAPTCHAs you face. Yet, as CAPTCHA’s handling strategies progress, it also causes a threat to network security. So the need of time is the adaptive evolution of CAPTCHAs cracking tools as well as security measures. That way, both human users as well as systems can exist with tangible benefits.
