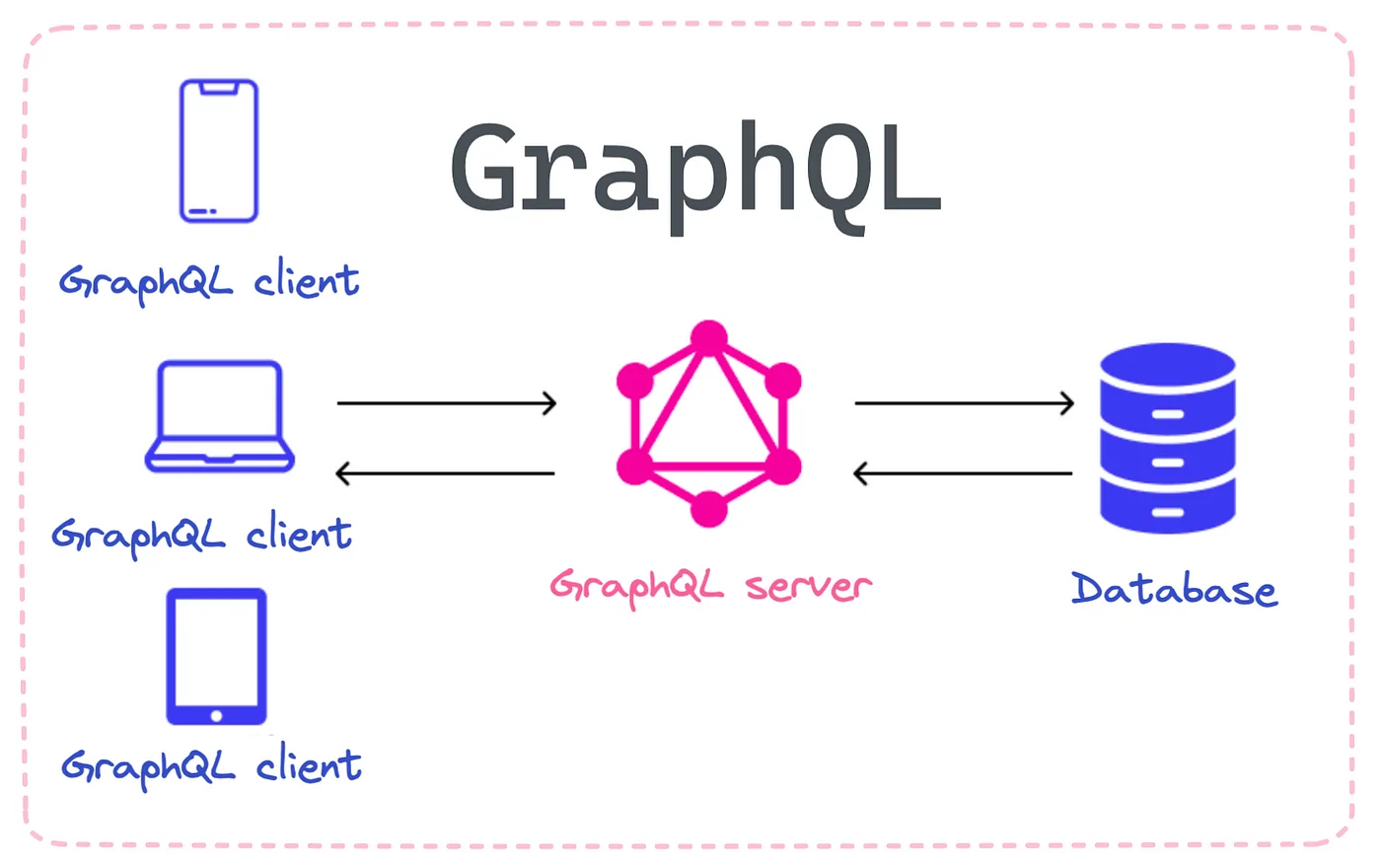
How To Use GraphQL For Web Scraping And Data Querying
GraphQL is a query language designed for graph-based data collection. Since graphs are a more effective and adaptable method of data conveyance, they are growing in popularity on websites with a lot of data. Because it enables more effective data transmission and quicker, more flexible development, web developers prefer the graphql client’s capability to specifically request certain dataset components over REST services. The same advantages apply to web scraping as well, in which by limiting our queries, we can simply scrape the targeted information we want, saving time and scraping resources. This useful tool ensures correctness and consistency with the website’s actual data by fetching the data we want straight from the backend. Additionally, using GraphQL makes the process more efficient by eliminating the requirement to parse and extract information from the HTML code. As GraphQL is specially made for use programmatically, it is seen to be a more reliable choice than scraping a web page’s dynamic structure.
Step 1: Locating The GraphQL Endpoint
The basic phase involves locating the GraphQL endpoint of the target site or API before you proceed to query or scrape data. A GraphQL endpoint is ordinarily a single URL that addresses all queries and changes. It often looks this way:
https://example.com/graphql or something comparative.
To locate the GraphQL endpoint, assess the site’s network activity utilizing browser developer tools by visiting the “Network” tab, filtering by “XHR” or “Fetch”, and interacting with the site to see if any GraphQL requests are created. These requests typically have a POST strategy and contain a query field within the payload.
Another strategy is inspecting the site’s documentation or API references, particularly in case it is a public or semi-public API.
A few GraphQL services also expose an interactive UI such as GraphiQL or GraphQL Playground, which you’ll be able to use to explore accessible queries. In case that interface is accessible, it’ll frequently be facilitated at /graphql or /playground.
Comprehending the precise endpoint is pivotal since each query or mutation must be coordinated to that URL. Without having that information, it is not possible to link with the GraphQL server or retrieve any structured data. After it is identified, save the endpoint as you will utilize it throughout the whole scraping and querying process.
Step 2: Inspecting The Schema
After you are done with the endpoint identification the second step is to comprehend what data is accessible and the way it is organized. The GraphQL schema defines all types, fields, queries, and relationships accessible within the API. Reviewing the schema helps you know exactly what you’ll be able to request and how to request it.
Numerous GraphQL servers permit introspection like special queries that yield the schema itself. These can exhibit accessible types, objects, fields, and their mandated arguments. You’ll operate these queries manually or utilize tools that automate the method.
If the API offers a graphical interface like GraphiQL or GraphQL Playground, utilize it to browse the schema. These tools present autocomplete, documentation panels, and visual representations of query structures, making schema exploration simpler and speedier.
Concentrate on root types such as Query and Mutation. These are the primary entry points for linking with the API. Aim for valuable fields like users, posts, or products since these options often frequently bear the core information you are looking for.
While you explore, note down paths and field names that you will likely query afterwards. Understanding the schema early on anticipates errors and saves time when composing your actual queries.
Step 3: Designing The Query
Before you compose a query, you have to define precisely what information you need. GraphQL helps you be precise, such as only requesting the fields you need. Whether it is product names, user profiles, or article outlines, clarity aids you in building proficient and targeted queries.
A GraphQL query takes after a JSON-like sentence structure but only depicts the shape of the anticipated response. It begins with a root field, like a query then details the nested fields in curly braces. Each level ought to coordinate the schema’s hierarchy precisely to bypass errors.
A few fields require arguments like IDs, filters, or pagination values. These must be incorporated within the query syntax. Scan the schema or documentation to comprehend which arguments are mandated and their valid format.
Only inquire for what you require as requesting numerous nested fields or unnecessary data can slow down responses and trigger rate limits. Lean queries lower server load and enhance scraping rate.
On the off chance that a graphical tool is accessible, utilize it to build and test your query. It reveals blunders right away and permits you to preview information, making it simpler to refine before utilizing it in your scraper.
Step 4: Establishing Request Headers
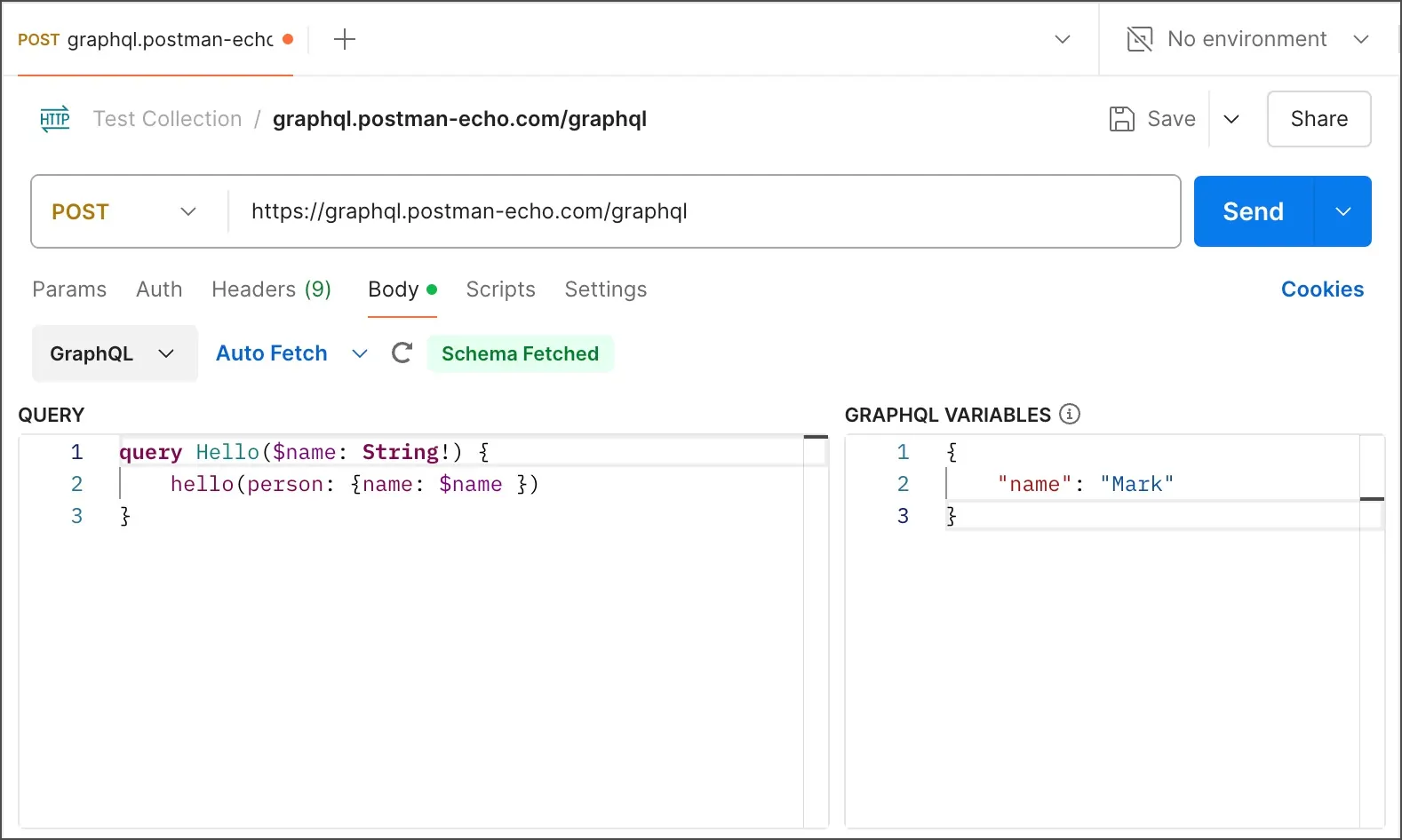
Request headers are essential to effective communication with a GraphQL server. They carry fundamental metadata such as content type, authentication tokens, and sometimes user-agent data. Without proper headers, your query can be denied or overlooked.
GraphQL APIs generally anticipate a Content-Type header set to application/json. It conveys to the server you are sending a JSON-formatted query. Missing or inaccurate content type is one of the foremost typical reasons for failed requests.
Numerous endpoints need authentication. It can be an API key, bearer token, or session cookie. As required, add the suitable Authorization header, like Authorization: Bearer YOUR_TOKEN. Review the API docs or intercepted requests for the precise format.
Some servers block automated activity. To avoid the common bot filters, include headers such as User-Agent, Referer, or Origin to imitate a real browser. Replicating these from browser network requests can help reproduce the right behaviour.
As you are setting up your script or tool, schedule headers in a reliable dictionary or object. It will make it simpler to oversee changes, particularly when working with numerous endpoints or rotating tokens amid expansive scraping assignments.
Step 5: Sending GraphQL Queries
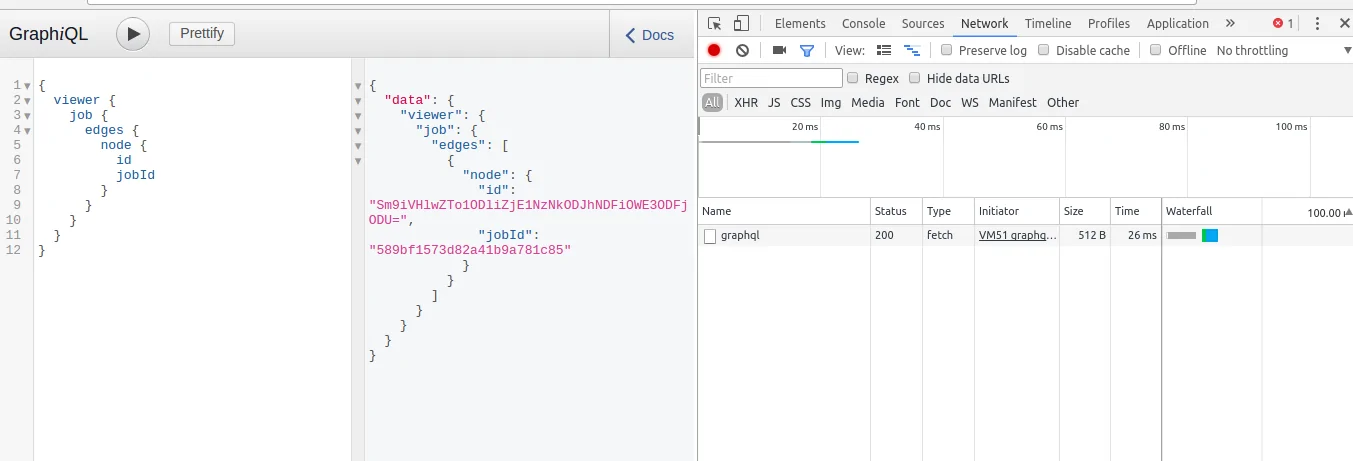
GraphQL queries are usually sent utilizing the POST strategy. In contrast to REST, where information is frequently fetched by means of GET, GraphQL depends on POST to bear the query and variables within the request body in the form of JSON.
The body of the request ought to be a JSON object with at least a query field. In case your query incorporates variables, include them in a separate variables field. Like this way:
{ “query”: “…”, “variables”: { “id”: “123” } }
You can utilize tools such as Postman, curl, or code libraries such as requests in Python or Axios in JavaScript to send the request. These options will permit you to tailor headers, and payload, and handle responses in a scriptable manner.
Sometimes GraphQL response can return both data and errors. Continuously inspect the errors field, even on the off chance that you get a 200 Ok status. Sentence structure mistakes, missing areas, or invalid arguments regularly show up here.
In case you are scraping, never spamming the endpoint. Use delays between requests, observe for rate constraint headers, and do not mishandle the server. Mindful scraping keeps your access intact and prevents you from getting IP-blocked.
Step 6: Storing The Response Data
GraphQL responses are returned as JSON, commonly having a data field and in some cases an error field. All the data you requested will be settled under data, matching the shape of your initial query.
Utilize a JSON parser in your preferred programming language to access the particular fields you need. For instance, in Python, you’ll utilize response.json() and after that. Explore the nested dictionaries to separate the values such as names, costs, or IDs.
GraphQL frequently returns deeply nested objects. During parsing, be sure that your script handles numerous levels and loops through arrays appropriately. Attend to optional areas that might not show up in each object.
Before you store the data you need to clean or transform it as needed. For instance, you can convert timestamps, strip HTML tags, or smooth structures. Clean data eases the analysis and prevents issues during later handling.
Save the parsed data in a structured format such as CSV, JSON, or a database per your project scale. To deal with huge datasets and utilize batch writes or file streaming without performance declines or memory problems.
Conclusion
In summary, GraphQL minimizes the amount of data transport and processing needed by enabling us to request only the data we require. As the developer, you can decide the fields you want to have returned to you using GraphQL. In addition to giving you only the information you need and eliminating unnecessary fields, this also makes things simpler for the target. Additionally, it makes data accessible that isn’t easily accessible through the website itself. Ultimately, the accuracy that GraphQL provides reduces superfluous clutter and saves both resources and time.
