
How To Scrape Data From Websites With CSRF Protection Using Scrapy
CSRF indicates a security drawback that empowers an attacker to induce users to execute actions for which they aren’t willing to. CSRF attack compels users who have already been authenticated to send a request to a Web application. CSRF attacks take advantage of a Web application’s confidence in a user who has been authorized. If a Web application is unable to distinguish between a request made by a single user and one made by a user without their permission, a cross-site request forgery (CSRF) attack can take advantage of this weakness. Consequently, the websites have to take some countermeasures to prevent such an attack. Various anti-CSRF strategies are employed, of which the use of CSRF tokens is the most influential ones. Furthermore, scraping the sites that employ CSRF tokens is a bit challenging, specially without a proper utilization of scraping tools and approaches. The following steps are a useful manual for those who want to scrape useful insights, yet CSRF tokens are making it tricky for them.
Step 1: Examining The CSRF Tokens
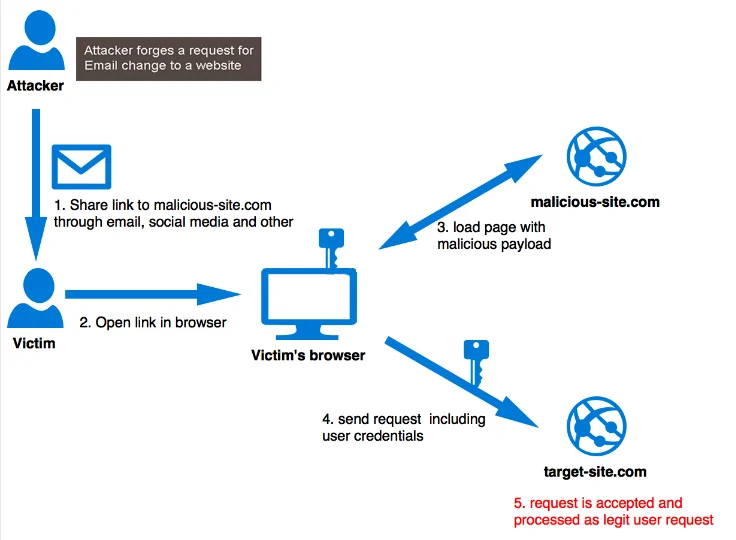
Cross-Site Request Forgery (CSRF) tokens are special values that websites utilize to avoid unauthorized requests. usually these tokens are typically found in headers, cookies, and hidden form fields.
You will analyze the CSRF tokens by loading the developer tools of your browser by using F12 or alternatively right-clicking and choosing the inspect option. Then head to the Network tab to run the action you opt to automate. For instance, it could be logging in or submitting a form.
Seek requests like POST or AJAX made to the server. Look at the Headers, Cookies, or Form Data in these requests, and distinguish the CSRF token’s location. It could be labelled as csrf_token, X-CSRFToken, or something comparable.
After you have identified it, look into how the token is transmitted. It could be within the request header, as a hidden form field, or stored in cookies. A few websites can regenerate CSRF tokens dynamically with each request, mandating you to extract and upgrade them persistently. Comprehending this process is significant before endeavouring to scrape, as coming up short of incorporating the proper token will end up in blocked or given-out requests. The following phase includes extracting this token dynamically utilizing Scrapy.
Step 2: Extracting The Token
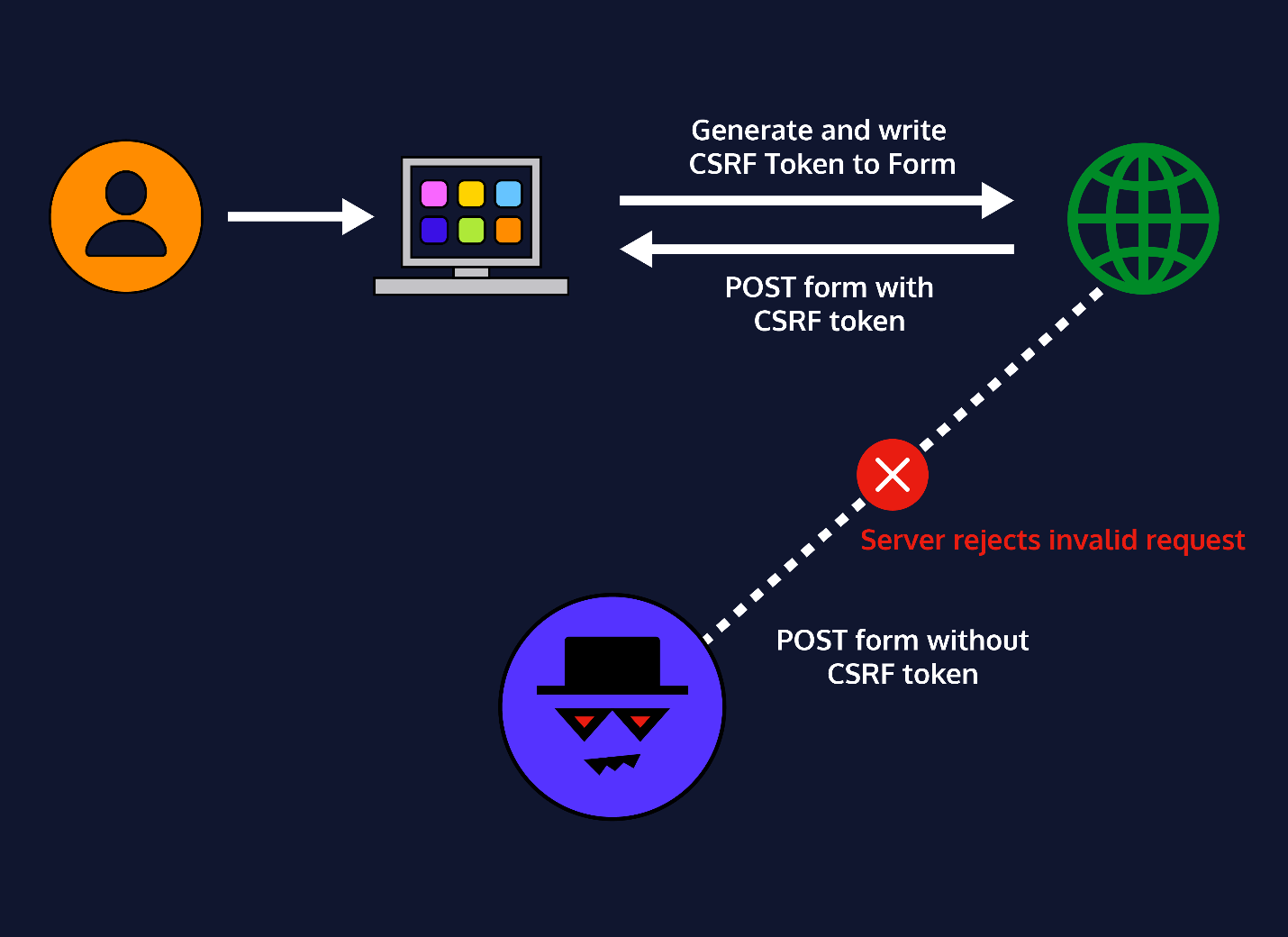
After the CSRF token’s location is identified, the second step is to extract it powerfully utilizing Scrapy. As the CSRF tokens frequently vary with each session, your Scrapy Spider should get the latest token before making confirmed requests.
To begin with, create a Scrapy spider and send a beginning GET request to the login or form page. That request recovers the CSRF token inserted within the page source or response headers. Utilize Scrapy’s response.xpath() or response.css() selectors to extract the token in case it’s in a discreet input field. In case the token is in cookies, get to it using response.headers.get(‘Set-Cookie’) or response.cookies.
Look into the following example if the CSRF token is in a hidden field:
csrf_token = response.xpath(“//input[@name=’csrf_token’]/@value”).get()
Here is another example in case the token is in headers:
csrf_token = response.headers.get(‘X-CSRFToken’, ”).decode()
After extracting the token, you can store it for use in ensuing requests. On the off chance that the site regenerates the token per request, you must overhaul it dynamically in your Scrapy middleware or spider logic. The following phase includes sending requests while incorporating the CSRF token appropriately.
Step 3: Storing And Updating

After a dynamic extraction of the CSRF token, you may need to store and update it for subsequent requests. As numerous websites regenerate CSRF tokens per session or ask, keeping up an upgraded token guarantees that your Scrapy spider can effectively authenticate and interact with the website.
To store the CSRF token in Scrapy’s meta dictionary, cookies, or a class attribute, here is an example:
self.csrf_token = response.xpath(“//input[@name=’csrf_token’]/@value”).get()
On the other hand, if the token is in cookies, you can utilize:
self.csrf_token = response.cookies.get(‘csrftoken’)
If the CSRF token changes repeatedly, you have to update it after each request by extracting it from the response and adjusting the stored value. You’ll accomplish this in Scrapy’s parse or parse_login strategies, just like this:
def parse(self, response):
self.csrf_token = response.xpath(“//input[@name=’csrf_token’]/@value”).get()
yield scrapy.FormRequest(
url=self.login_url,
formdata={“username”: “your_username”, “password”: “your_password”, “csrf_token”: self.csrf_token},
callback=self.after_login
)
Keeping up an updated CSRF token makes sure that your requests are confirmed. The fourth step includes sending these requests legitimately with the token included.
Step 4: Sending Request With Tokens
After the CSRF token is extracted and stored, it should be included in requests to be sure of effective authentication or data submission. According to the way the site expects the token, it ought to be included in either the headers, cookies, or form data.
To add the CSRF Token into Headers you will be utilizing Scrapy’s headers parameter. Here is an example:
headers = {
“X-CSRFToken”: self.csrf_token,
“User-Agent”: “Mozilla/5.0”
}
yield scrapy.Request(url=self.target_url, headers=headers, callback=self.parse_response)
Similarly, to add a CSRF Token in Form Data you can incorporate it within the formdata parameter of scrapy.FormRequest. Look into this example:
yield scrapy.FormRequest(
url=self.login_url,
formdata={“username”: “your_username”, “password”: “your_password”, “csrf_token”: self.csrf_token},
callback=self.after_login
)
On the off chance that the CSRF token is stored in cookies, it ought to be sent utilizing Scrapy’s cookies parameter like the following:
yield scrapy.Request(url=self.target_url, cookies={“csrftoken”: self.csrf_token}, callback=self.parse_response)
Confirming the proper arrangement of the CSRF token helps prevent request failures.
Step 5: Handling Authentication And Session
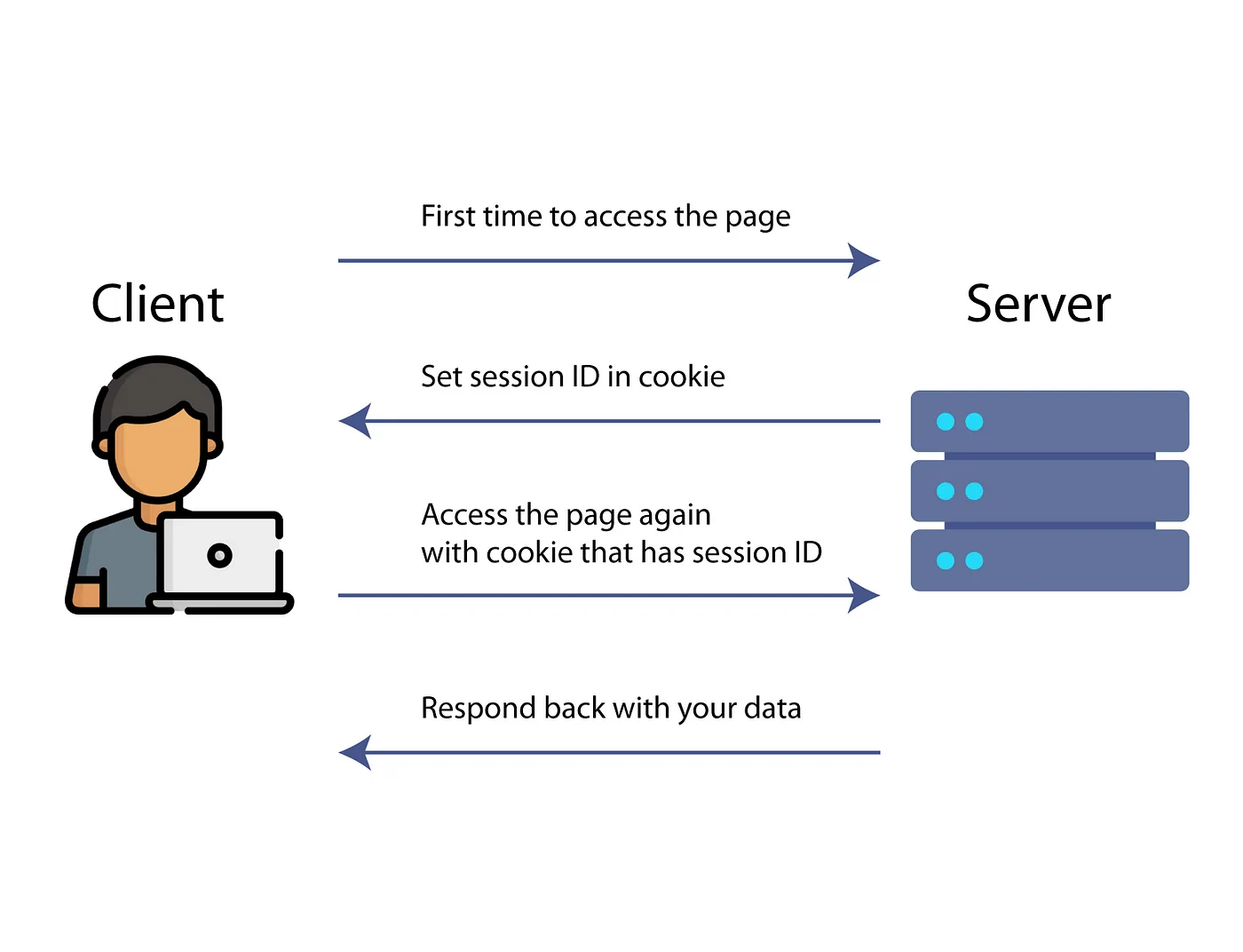
Effectively sending requests with the CSRF token is not sufficient. As a result, you also need to keep up an authenticated session to scrape protected pages. Numerous sites utilize cookies and sessions to keep track of the logged-in users. Therefore, your Scrapy Spider should continue these across requests.
Once you have extracted the CSRF token and sent it within the login request, store session cookies to preserve authentication:
def start_requests(self):
yield scrapy.Request(url=self.login_url, callback=self.parse_login)
def parse_login(self, response):
self.csrf_token = response.xpath(“//input[@name=’csrf_token’]/@value”).get()
yield scrapy.FormRequest(
url=self.login_url,
formdata={“username”: “your_username”, “password”: “your_password”, “csrf_token”: self.csrf_token},
callback=self.after_login
)
def after_login(self, response):
if “logout” in response.text: # Check if login was successful
self.logger.info(“Login successful!”)
yield scrapy.Request(url=self.protected_url, callback=self.parse_protected)
else:
self.logger.error(“Login failed!”)
Mostly Scrapy can handle cookies automatically, though in case required, you can utilize meta={‘cookiejar’: 1} to ensure session persistence across numerous requests. Here is an example:
yield scrapy.Request(url=self.protected_url, callback=self.parse_protected, meta={‘cookiejar’: 1})
By keeping up the session, you can proceed to create authenticated requests. The ultimate step is dealing with errors and retries to confirm a smooth scraping.
Step 6: Addressing Errors And Implementing Retry

The sites having CSRF protection frequently execute extra security measures including token expiration, session timeouts, or request blocking. To guarantee smooth scraping, you must have to deal with errors and enforce retry mechanisms.
Often, websites discredit CSRF tokens after a specific period. In case you get a 403 Forbidden or an authentication issue, you will re-fetch the CSRF token and retry the request, just like this:
def handle_failure(self, response):
if response.status == 403:
self.logger.warning(“403 Forbidden: Retrying with a new CSRF token”)
return scrapy.Request(url=self.login_url, callback=self.parse_login, dont_filter=True)
Moreover, Scrapy gives an automatic retry mechanism. To empower it, you will follow the example below to configure RETRY_ENABLED in settings.py:
RETRY_ENABLED = True
RETRY_TIMES = 3 # Number of retries
RETRY_HTTP_CODES = [403, 500, 502, 503, 504]
In case the site frequently updates CSRF tokens, you will make custom middleware that will intercept responses and update the token powerfully. Here is an illustration:
class CSRFHandlingMiddleware:
def process_response(self, request, response, spider):
if response.status == 403:
spider.logger.warning(“Updating CSRF token and retrying…”)
return scrapy.Request(url=spider.login_url, callback=spider.parse_login, dont_filter=True)
return response
With the successful implementation of the above error-handling approaches, your Scrapy spider will easily bypass CSRF protection reliably and prevent undue failures.
Conclusion
In summary, CSRF tokens are a prevalent authentication technique that offers an additional degree of defence against scrapers and bots. Using a trustworthy parsing library, you can effectively extract the CSRF token from the HTML of the login form while scraping such websites. The retrieved CSRF token will then be included in the login request payload when the form is submitted. The scraping process is finally completed by making sure the CSRF token is refreshed for every new session or request. The above-stated steps can serve as a helpful manual for you while scraping websites with CSRF protection using Scrapy, an effective Python tool.
