How To Automate Data Processing Using AWS Lambda And Python
Data is essential to every contemporary business. It drives choices, establishes plans, and facilitates a deeper comprehension of consumers. The sheer amount of data that companies gather and utilize, however, soon becomes a problem if it gets unmanageable. Added to that, in the rapidly evolving fields of cloud computing and data engineering, the idea of serverless data processing has become significant. This method offers a strong alternative to managing conventional infrastructure for processing data activities in an economical and efficient manner. AWS Lambda, a potent computing tool from Amazon Web Services (AWS), has become a major force in this field. Developers can run code using AWS Lambda, a serverless computing technology, without having to worry about managing or procuring servers. Among the many advantages of this fundamental change in computing paradigm are cost savings, reduced operational overhead, and autonomous scaling. AWS Lambda can execute Python code. Python runtimes from Lambda let users run code to handle events. Organizations can focus on creating business logic by simply automating their data operations with AWS Lambda. This blog will further proceed with providing a step-by-step approach to automate data processing with the integration of AWS Lambda and Python.
Step 1: Identifying The Source

Before you proceed to automate any data processing task, you may need to clearly identify the source of your data initially. In AWS-based automation, data regularly arrives from sources such as Amazon S3, Amazon Kinesis, DynamoDB, or even third-party APIs.
You have to comprehend the kind of data you are going to deal with, such as CSV files, JSON logs, pictures, etc. Also, you need to learn how regularly that data arrives. It will help decide the fitting trigger component for your Lambda function.
For instance, on the off chance that you are processing log files from a web app, these could be pushed into an S3 bucket intermittently. Or, in case you are examining real-time sensor information, Kinesis could be more appropriate.
The structure, format, and size of the information ought to also be considered since Lambda contains memory and timeout limits. In case the data surpasses Lambda’s capacity, preprocessing or chunking the data could be essential.
Also, look into the anticipated results, such as:
Are you changing the data? Putting away results in another service such as Amazon RDS or Elasticsearch, or sending notifications?
All of that relies on the nature of the information. Defining the information source legitimately guarantees that the remainder of the workflow can be built effectively and with negligible surprises while executing.
Step 2: Setting Up The Trigger
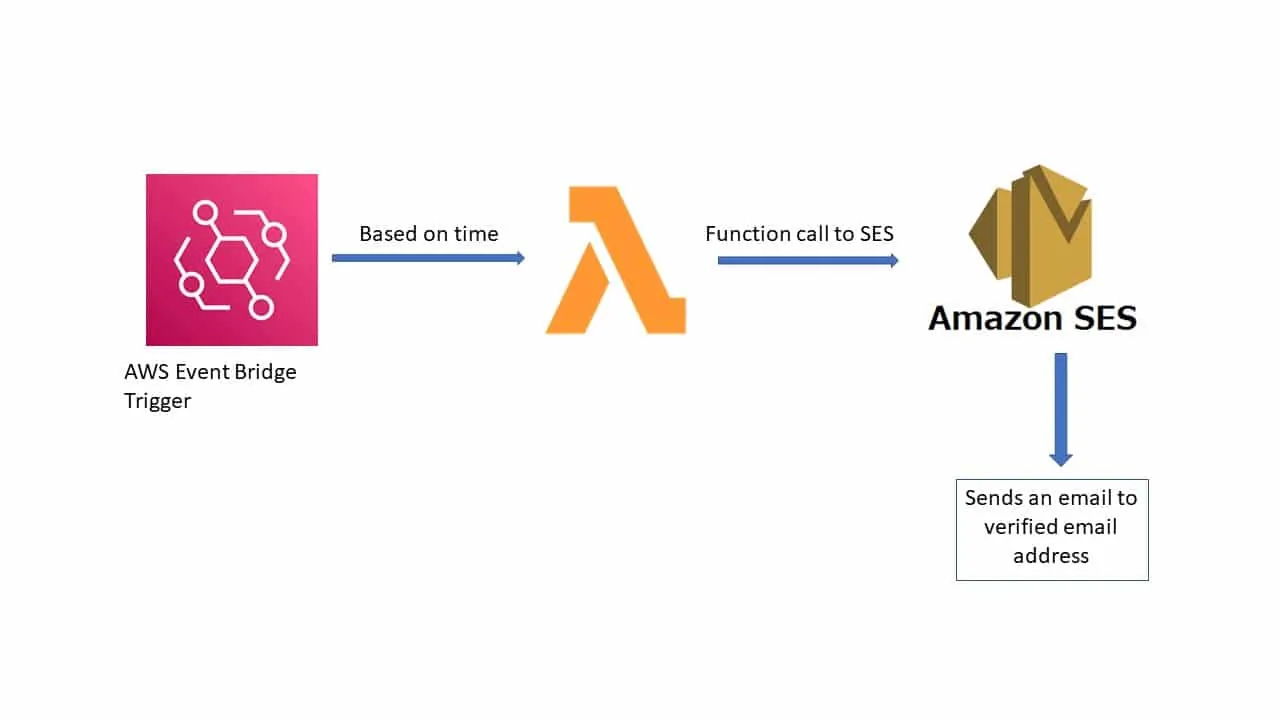
After the information source is defined, the second step involves setting up the trigger that will start the Lambda function. In most commonly utilized cases, that can be an S3 bucket where files are uploaded. Creating a new S3 bucket in AWS is direct and can be done through the console, CLI, or SDK.
During the bucket creation, arrange it according to your data’s essentials. Set appropriate region, versioning as required, and access authorizations. If information protection is a concern, allow encryption and block public access by default. Moreover, look into organizing incoming files utilizing folder prefixes or naming traditions for simpler processing and filtering.
Other than S3, other services such as DynamoDB, Kinesis, or even API Gateway can function as event sources for Lambda. Your selection relies on how and when the data joins the framework. For instance, real-time streaming data accommodates satisfactorily with Kinesis, whereas somehow structured changes in databases are way better addressed through DynamoDB streams.
Once you are done with choosing the trigger source, it should be configured to send an event notification to the Lambda function. It implies indicating the type of event, like “ObjectCreated” in S3, that ought to trigger the function execution.
An accurately configured trigger guarantees that your Lambda function operates precisely when it ought to, decreasing delays and preventing pointless executions. It will shape the foundation of dependable, event-driven automation in AWS.
Step 3: Writing The Core Python Script
After the trigger source is ready, the fourth step is to write the core Python script that will execute inside your Lambda function. That script ought to center on retrieving the approaching data, preparing it according to your business rationale, and then storing or passing the results as required. AWS Lambda utilizes the handler format, in which the event parameter bears the data from the trigger.
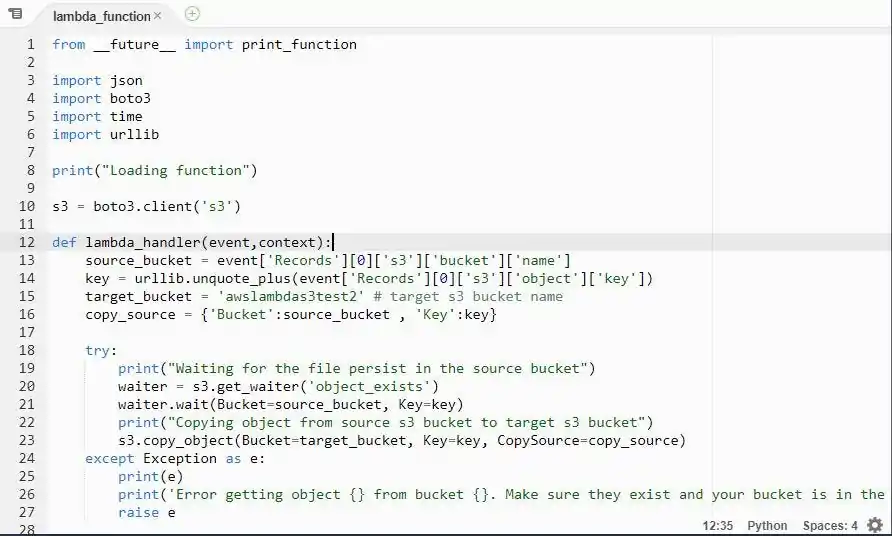
The following is a sample code to handle an S3-triggered event:
import json
import boto3
def lambda_handler(event, context):
# Get the S3 bucket and file name from the event
bucket_name = event[‘Records’][0][‘s3’][‘bucket’][‘name’]
file_key = event[‘Records’][0][‘s3’][‘object’][‘key’]
s3_client = boto3.client(‘s3’)
# Download the file from S3
try:
response = s3_client.get_object(Bucket=bucket_name, Key=file_key)
file_content = response[‘Body’].read().decode(‘utf-8’)
# Process the data (for example, here we print it)
print(f”Processing file: {file_key}”)
print(f”File content: {file_content}”)
# Example: Save processed data back to S3
processed_data = file_content.upper() # Sample transformation
s3_client.put_object(Bucket=bucket_name, Key=f”processed/{file_key}”, Body=processed_data)
except Exception as e:
print(f”Error processing file {file_key} from bucket {bucket_name}: {str(e)}”)
raise e
The above script will retrieve the file from S3, process it, and save it again to the S3 bucket. You can substitute the data processing portion with more elaborate logic per the user case.
Step 4: Deploying Python Script Into A Lambda Function
Develop a new Lambda function within the AWS Management Console or utilizing the AWS CLI. Employ Python as the runtime environment and title your work clearly per its purpose for easier management.
Upload your script with a code editor or a zip package; you may need to link external libraries inside the zip in case of the script’s dependency on them.
Arrange the memory allocation of the function and a timeout per the expected workload. More memory results in the maximized level of performance, facilitating huge tasks.
Imply the entry point through a handler specification and add logging with the help of the logging module or print() by Python. The Logs will shift to CloudWatch, displaying visibility of happenings during performance occurrences.
Below is the illustration of Lambda environment variables:
import os
bucket_name = os.environ[‘BUCKET_NAME’]
Step 5: Linking Lambda Function To Trigger Source
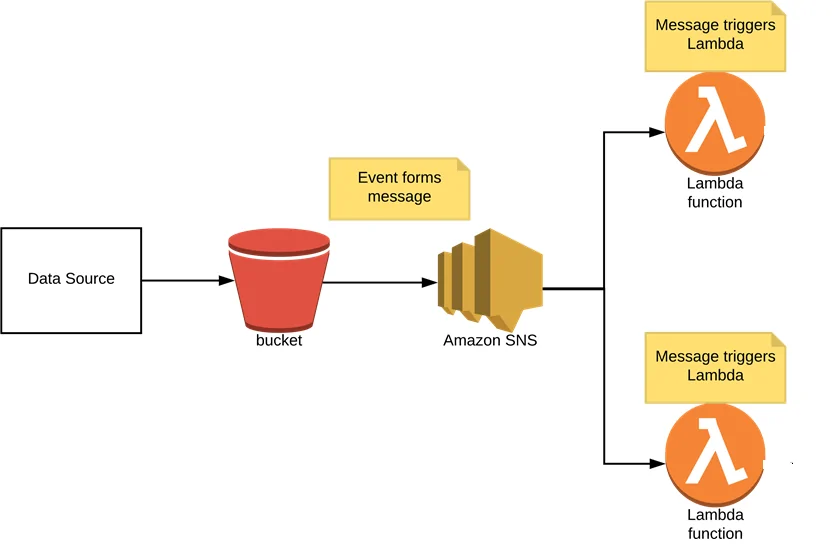
Shape the event source like an S3 bucket, DynamoDB stream or even an API gateway; it all depends upon your setup.
Here is a step-by-step explanation of linking the S3 event to trigger the Lambda function via using the console:
In the first place, open the S3 console and head to your bucket.
Locate the Event Notification within the Properties Tab.
Include a notification with a trigger type, like ObjectCreated.
Select Lambda Function and choose the function you made.
After that, centre on IAM permissions. Your Lambda function operates beneath a particular IAM role, and that part must have policies allowing it access to the assets it requires. For instance, in the event that the work reads from S3 and composes to DynamoDB, it requires s3:GetObject and dynamodb:PutItem permissions.
Look into the following sample IAM policy for Lambda’s access to S3:
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: “s3:GetObject”,
“Resource”: “arn:aws:s3:::your-bucket-name/*”
},
{
“Effect”: “Allow”,
“Action”: “s3:PutObject”,
“Resource”: “arn:aws:s3:::your-bucket-name/processed/*”
}
]
}
That IAM policy permits the Lambda function to read from and write to the required S3 bucket. Make sure to alter the resources and actions per your specific utilize case and requirements.
Step 6: Testing Your Automated Pipeline
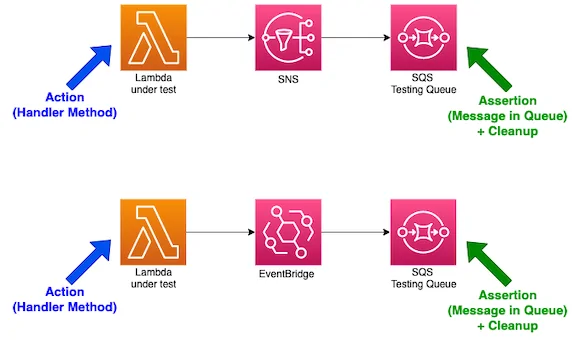
Once everything is in place, it is pivotal to test your automated pipeline end-to-end. Trigger the event in a manual manner and inspect the performance of the Lambda Function. You must be sure that it works per the expectations and processes information correctly. Then employ test cases to contemplate real data settings, assuring the integrity of your rationale under differing scenarios.
Operate AWS CloudWatch and examine the performance. Employ custom metrics and log filters to enable failure alerts, execution delay prompts or any “loss of information” case awareness.
Here is a case of logging performance metrics in CloudWatch:
import time
def lambda_handler(event, context):
start_time = time.time()
# Your processing code here
execution_time = time.time() – start_time
print(f”Execution time: {execution_time} seconds”)
Also, look into the frequency of the function and optimize the code or memory allocation if you notice a slow performance issue. It is also recommended to set up alerts to get notified in case of any disarray.
Conclusion
In conclusion, there are no servers to provision or manage while using AWS Lambda. All you have to do is submit your code; the rest will be taken care of for you, with high availability, to operate and scale it. Additionally, repetitive tasks could be automated using AWS Lambda by performing them on a set schedule or by initiating them with events. It enables you to automate your test and deployment workflow, schedule security group upgrades, start and stop Amazon EC2 instances, and update hardware firmware automatically. In summary, Python’s efficient code plus AWS Lambda’s powerful integration allow you to create a dependable and controllable data processing pipeline.
