How To Scrape Data From Websites With Multi-Factor Authentication
Multi-factor Authentication or MFA is a type of authentication in which the user must submit two or more verification factors in order to obtain access to a site. MFA is a critical component of an effective identity and access management (IAM) policy. It reduces the possibility of a successful cyberattack by requiring one or more extra verification elements in addition to the login and password. MFA’s primary advantage is that it will improve an organization’s security by prompting users to provide more than just their login and password to authenticate themselves. However, when attempting to scrape data from authorized websites, MFA introduces an additional degree of complication. You must thus use practical scraping tools and techniques in order to scrape data from these websites. Additionally, you must adhere to a peculiar procedure as traditional scraping techniques might still fail despite putting in a lot of time and effort. The following blog will present a similar step-by-step process to help you in scraping data from websites with MFA.
Step 1: Examining The Working Of The Authentication Framework
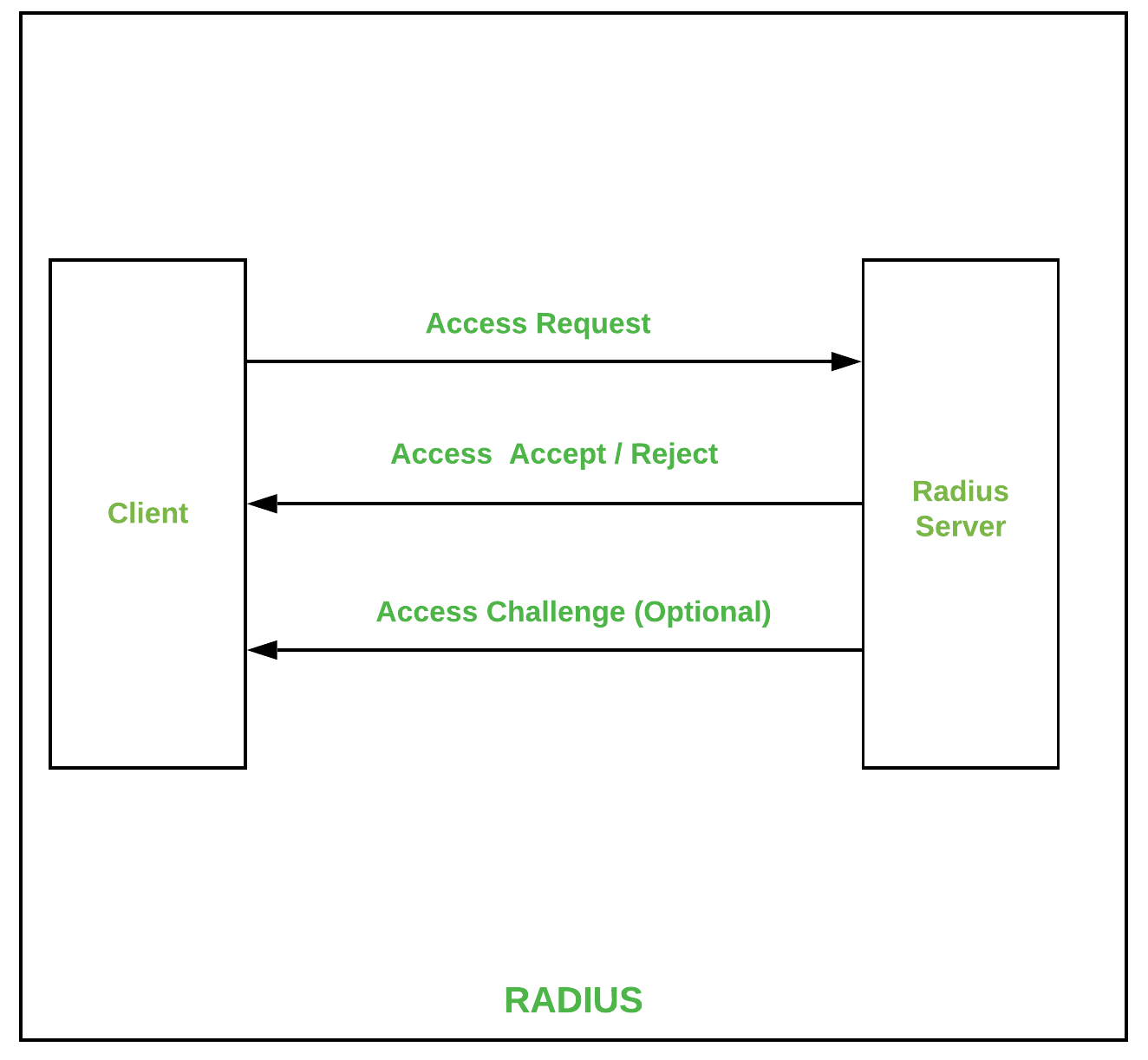
Before you get into the detailed process of scraping data from a website with Multi-Factor Authentication (MFA), first you have to examine the working of its authentication framework. MFA includes an additional security layer exceeding just a username and password, frequently mandating a one-time password or OTP, push notification approval, biometric verification, or security questions. A proper understanding of this process aids in determining the process of bypassing or automating the verification step legally and ethically.
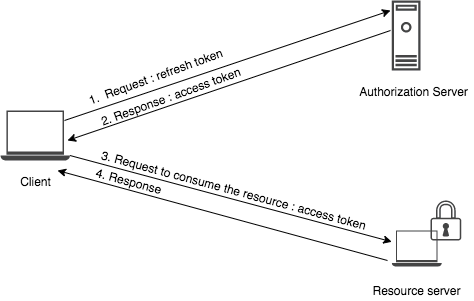
Begin by manually logging into the site while reviewing network requests utilizing browser developer tools via F12 → Network tab. Seek for API calls, cookies, session tokens, or headers included in verification. Specify if the websiet employments OAuth, SAML, JWT tokens, or a custom authentication strategy. In case MFA is activated, inspect how the additional verification step is handled. A few websites pass an OTP through SMS or email, while others demand app-based verification.
After that, evaluate whether MFA is required on each login or only for new devices. In case of session persistence is permitted, capturing authentication cookies or API tokens may eliminate the requirement for recurrent MFA challenges. This stage is significant for selecting the proper automation procedure in subsequent steps. After you understand the flow, you’ll be able to proceed to automate the login process.
Step 2: Automating The Login Process
After you are done understanding the authentication flow, the second step involves automating the login process by employing a headless browser such as Selenium, Puppeteer, or Playwright. These tools mimic genuine client interactions, permitting you to enter credentials, address MFA challenges, and extract session information for further usage.
Begin by writing a script to open the login page, find the username and password areas, and submit credentials. Utilize XPath or CSS selectors to discover and interact with elements. Once MFA is enabled, you will have to dynamically regulate the second authentication factor. In the case of e-mail or SMS-based OTPs, your script has to retrieve the code from an inbox or messaging API. Similarly, if the site uses app-based authentication such as Google Authenticator, tools such as pyotp, used for TOTP-based verification, can produce valid codes.
For the instances where push notifications like Duo, Microsoft Authenticator are utilized, human intervention could be vital unless the site permits Remember this Device functionality. Likely, store session cookies or authentication tokens after a successful login to prevent recurring MFA challenges.
After the automation of login is successful, you can proceed to the following step of capturing and storing authentication tokens.
Step 3: Capturing And Storing Authentication Tokens

Once the login is automated, the following pivotal step is to capture and store authentication tokens or session cookies to preserve access without repeatedly proceeding through Multi-Factor Authentication (MFA). Various websites create session tokens after a productive login, which can be reused for future requests.
To capture these tokens, utilize browser developer tools via the F12 → Network tab to examine authentication requests. Seek for session cookies, JWT tokens, API keys, or bearer tokens within the request headers. On the off chance that you are utilizing Selenium, Puppeteer, or Playwright, you’ll extract cookies and headers programmatically. While using Selenium, for instance, utilize driver.get_cookies() to retrieve session cookies. Likewise, in Puppeteer or Playwright, capture response headers utilizing their request interception highlights.
After the tokens are captured, you will store them safely in a database, an environment factor, or an encrypted file. Do not go for hardcoding them to avoid security risks. Execute logic to identify when a token expires and refresh it automatically by re-running the login script.
By keeping up substantial authentication tokens, you’ll make direct API requests or scrape protected pages without having to log in once more, guaranteeing a consistent and proficient data extraction process. The following step includes utilizing these tokens for genuine information scraping.
Step 4: Utilizing Tokens To Access Content
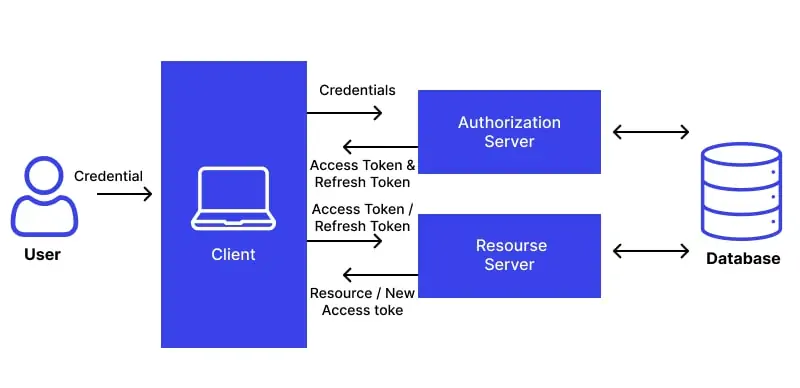
After the authentication tokens or session cookies are captured, they can be utilized to access ensured content without logging in over and over. Per the website’s structure, information extraction can be done by means of direct API calls or conventional web scraping strategies.
Numerous websites include APIs that serve data in organized formats such as JSON or XML. Utilize tools like requests or Axios to send verified requests by including the stored token in headers:
headers = {“Authorization”: “Bearer YOUR_TOKEN”, “Cookie”: “SESSION_ID=your_session_cookie”}
response = requests.get(“https://example.com/api/data”, headers=headers)
That strategy is productive since APIs return clean and organized data without needing HTML parsing.
In case no API is accessible, utilize BeautifulSoup (Python), Cheerio (Node.js), or Puppeteer to scrape the specified content. Join authentication cookies to preserve session access as you are scraping. Here is an example of it in Selenium:
For cookie in saved_cookies:
driver.add_cookie(cookie)
driver.get(“https://example.com/protected-page”)
The utilization of these tokens helps you proficiently extract data without triggering MFA once more. The following phase will deal with session expiration and token rotation.
Step 5: Ensuring Uninterrupted Access
Usually, the authentication tokens and session cookies have expiration times, demanding a technique to preserve uninterrupted access. A few tokens expire after a set duration, though others stay substantial till the session is manually logged out or the browser is shut. To address this, first, you need to determine the expiration behaviour by observing response headers and error messages. On the off chance that a request comes up short due to a terminated token, the framework may return a 401 Unauthorized or 403 Forbidden status.
To anticipate disruptions, execute automatic token renewal. On the off chance that the site gives a refresh token component, utilize it to produce new access tokens without logging in once more. For APIs, review if a dedicated refresh endpoint exists, permitting you to exchange an expired token for a new one. In case no refresh mechanism is accessible, the script ought to identify token expiration and trigger the login automation process from the second step to recover fresh authentication credentials.
A further approach is session persistence. In the event that authentication relies on cookies, saving and reloading them can extend session life. Nevertheless, in the event that the site upholds periodic logouts, automating re-authentication is essential. Overseeing session expiry successfully guarantees continuous data extraction, permitting a smooth move to the ultimate step of extracting and preparing the required data.
Step 6: Extracting And Processing The Information
Once you are done with establishing authenticated access, the ultimate step involves extracting and processing the specified information productively. Per the source, data can be obtained through direct API responses or scraped from web pages. In case of utilizing an API, extract significant fields from the JSON or XML response and structure them for storage or examination. To do web scraping, you will parse the HTML content utilizing BeautifulSoup (Python), Cheerio (JavaScript), or Puppeteer to find and extract particular components according to CSS selectors or XPath.
After the data is collected, clean and you may need to format it for convenience. It can include evacuating unnecessary HTML tags, taking care of missing values, normalizing text, or converting information types. In the case of expansive datasets, look into storing the extracted data in a database such as MySQL, PostgreSQL, or MongoDB for simple querying and examination. In case the data will be utilized for reports or machine learning models, you will export it to CSV, JSON, or Excel formats.
To preserve effectiveness, automate the extraction process at planned intervals utilizing cron jobs or task schedulers. Execute logging and error handling to pursue issues and retry failed requests as a vital step. Once these optimizations are done, the scraping process remains reliable, scalable, and capable of addressing growing authentication challenges.
Conclusion
In conclusion, WAF is not an ordinary site defence method, so the success rate of scraping such pages is quite low. Yet it is in some way possible to scrape data from MFA sites using a methodical methodology, like the one discussed in this blog. Additionally, it teaches you how to utilize the right tools and gives you a comprehensive overview of the different authentication processes. However, while scraping authorized websites, you must exercise greater caution while maintaining compliance. Therefore, it is imperative that you adhere to website policies and perform your scraping operations in a transparent manner.
