How To Use Optical Character Recognition (OCR) For Automated Data Entry
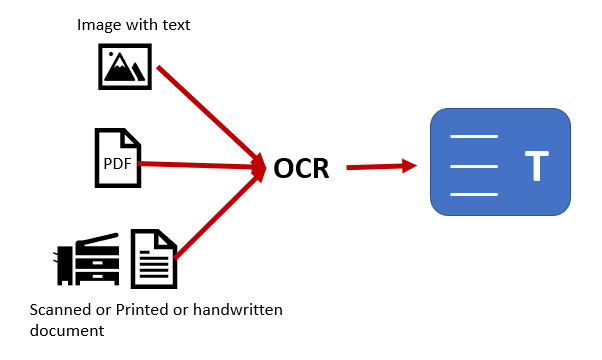
It is necessary to employ an automated data entry solution in the contemporary digital context where accuracy and precision are requisite. Among various other tools accessible, OCR or Optical Character Recognition, is one of the prevalent ones, which can viably transform various documents into editable and searchable forms. These documents can range from scanned papers and PDFs to photos captured via cameras and many more. The process begins with data collection and organization. Following this, a suitable OCR engine is chosen to extract data from specified images. To polish the extracted data, further processing is operated, and the functionality of the extracted content is also ensured. Using the thorough step-by-step process as highlighted in this blog, individuals as well as organizations working on data automation projects can benefit a lot. Having a firm grasp of details related to the efficient use of the Optical Character Recognition tool ensures the operational efficiency of data entry-related chores.
Step 1: Collecting And Preparing Data
The initial step in utilizing Optical Character Recognition (OCR) for automated data entry is to collect the documents that include the text you opt to extract. That can incorporate scanned pictures, PDFs, or photos. Make sure that the documents are legible and of good quality to enable precise recognition.
After collecting the documents, it is fundamental to qualify them for processing. That can include transforming PDF files to image formats or cropping pictures to emphasize significant text ranges. In Python, you can employ libraries such as PyMuPDF to extract pictures from PDFs. Consider the following arrangement:
import fitz # PyMuPDF
pdf_document = “sample.pdf”
doc = fitz.open(pdf_document)
for page in doc:
pix = page.get_pixmap()
output_image = f”page_{page.number}.png”
pix.save(output_image)
Furthermore, be sure that you have consistent formatting across documents to play down disparities during recognition. After you are done with data organization and preparation, you are all set to head toward preprocessing for more suitable OCR results.
Step 2: Preprocess The Input Data
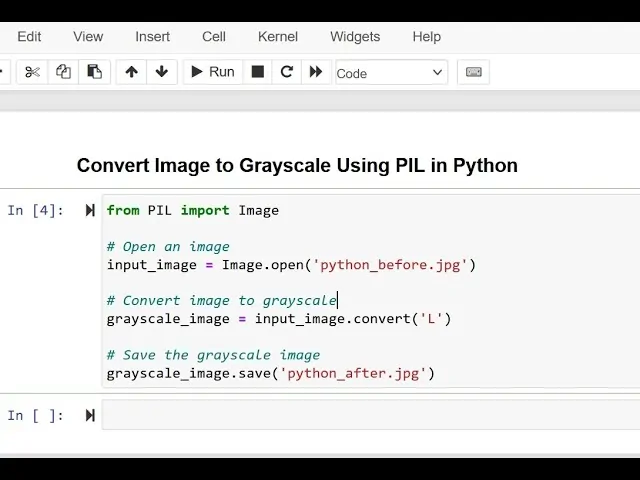
It is vital to preprocess the input information to improve the precision of OCR. This phase concerns various techniques to advance picture quality and prepare the content for recognition. Begin by switching over images to grayscale, which decreases complexity and highlights text more effectively. You can accomplish this utilizing the Python Imaging Library (PIL). Look into the following example:
from PIL import Image
# Open the image
image_path = ‘input_image.png’
img = Image.open(image_path)
# Convert to grayscale
img_gray = img.convert(‘L’)
img_gray.save(‘gray_image.png’)
After that, you have to apply binarization to convert the grayscale image into a black-and-white form, which helps identify content from the background. This may be accomplished using a thresholding method as follows:
# Binarization
threshold = 128
img_binary = img_gray.point(lambda x: 0 if x < threshold else 255, ‘1’)
img_binary.save(‘binary_image.png’)
Besides, consider rectifying any skew within the image. Skew rectification algorithms can be executed with the libraries such as OpenCV. A well-organized photo with high contrast and appropriate alignment will greatly improve OCR execution, permitting for more exact text extraction within the taking-after steps.
Step 3: Picking The Correct OCR Engine
Picking the correct OCR engine could be a pivotal step in automating data entry. Various tools are accessible, each with notable highlights and credentials. Well-known choices incorporate Tesseract, Google Vision API, and ABBYY FineReader. In most cases, Tesseract could be a favored open-source option because of its adaptability and support for considerable languages.
To begin with Tesseract in Python, you ought to install the Pytesseract library together with the Tesseract executable. To begin with, make sure you have Tesseract installed on your framework. You can download it from here.
After you have installed it, you can utilize the code given below to design and operate Tesseract for content extraction:
import pytesseract
from PIL import Image
# Specify the path to the Tesseract executable
pytesseract.pytesseract.tesseract_cmd = r’C:\Program Files\Tesseract-OCR\tesseract.exe’ # Adjust path as necessary
# Load the preprocessed image
image_path = ‘binary_image.png’
img = Image.open(image_path)
# Perform OCR on the image
extracted_text = pytesseract.image_to_string(img)
print(extracted_text) # Display the recognized text
Before you operate the OCR, you will configure language alternatives by setting the lang parameter if you are working with non-English content. Picking the fitting engine and appropriately configuring it can altogether improve the exactness of the text recognition process.
Step 4: Text Recognition Using The Chosen OCR Engine
This step involves the actual text recognition occurrence by using the chosen OCR engine to extract content from the preprocessed pictures. For Tesseract, the method is straightforward and can hold different formats, like printed and manually written content.
After you are done with configuring Tesseract as laid out within the last step, you’ll be able to start extracting text from your pictures. which comprises utilizing the image_to_string strategy from the Pytesseract library. Following is the way to accomplish text acknowledgment and store the extracted data:
import pytesseract
from PIL import Image
# Load the preprocessed image
image_path = ‘binary_image.png’ # Use the processed image from the previous steps
img = Image.open(image_path)
# Perform OCR to extract text
extracted_text = pytesseract.image_to_string(img)
# Display the extracted text
print(“Extracted Text:”)
print(extracted_text)
# Save the extracted text to a file for later use
with open(‘extracted_text.txt’, ‘w’) as text_file:
text_file.write(extracted_text)
The above code snippet will load the binary image prepared in prior steps, apply the OCR process to extract content and print the result. Moreover, it will save the extracted content to a .txt file for further usage, which can be valuable for data processing or integration into other apps.
Be sure to validate the extracted text, as OCR may present blunders, especially with challenging fonts or boisterous foundations. You can handle this within the following step through postprocessing strategies.
Step 5: Tuning The Extracted Content

The fifth step, which involves postprocessing, is fundamental to tune the extracted content and revamp any inaccuracies that arise during the OCR process. This action upgrades the reliability of the information for following utilize, particularly in automated data entry scenarios.
Begin by tending up the extracted content utilizing standard expressions to distinguish and correct typical OCR blunders. For instance, OCR may misinterpret characters, like confusing ‘0’ with ‘O’ or ‘1’ with ‘I.’ The below is a trial code snippet to illustrate basic error adjustment:
import re
# Load the extracted text from the previous step
with open(‘extracted_text.txt’, ‘r’) as text_file:
extracted_text = text_file.read()
# Perform basic error corrections
corrected_text = re.sub(r’\bO\b’, ‘0’, extracted_text) # Correcting ‘O’ to ‘0’
corrected_text = re.sub(r’\bI\b’, ‘1’, corrected_text) # Correcting ‘I’ to ‘1’
# Display the corrected text
print(“Corrected Text:”)
print(corrected_text)
# Optional: Save the corrected text for further processing
with open(‘corrected_text.txt’, ‘w’) as corrected_file:
corrected_file.write(corrected_text)
Exceeding basic character substitutions, consider employing a dictionary or a spell-checking library, such as pyspellchecker, to recognize and adjust incorrectly spelled words.
Furthermore, structure the text per your specific information essentials. For example, in case you extracted a list of objects or a table, you may need to arrange it into a structured data format such as CSV or JSON. That organized data can then be effortlessly incorporated into databases or employed for examination, making the postprocessing step imperative for guaranteeing the quality and convenience of your extracted information.
Step 6: Integrating Extracted Data Into Applications
The last step in using Optical Character Recognition (OCR) for automated information entry includes joining the extracted and adjusted content into your preferred framework or workflow. This step guarantees that the information is easily available and functional for further examination or processing.
To begin with, choose the format in which you need to reserve the data. Standard formats incorporate databases, spreadsheets, or CSV files. The following is an illustration of saving the adjusted content into a CSV file utilizing the built-in csv module of Python:
import csv
# Prepare the corrected text data for CSV
data_lines = corrected_text.splitlines() # Split text into individual lines
# Define the CSV file path
csv_file_path = ‘extracted_data.csv’
# Write the data to a CSV file
with open(csv_file_path, mode=’w’, newline=”) as csv_file:
writer = csv.writer(csv_file)
for line in data_lines:
writer.writerow([line]) # Write each line as a new row
print(f”Data successfully written to {csv_file_path}”)
Following, you’ll automate the complete process employing a script or workflow automation apparatus. That may include scheduling the script to operate at particular intervals, coalescing it with other applications by means of APIs, or activating it through events like uploading new documents. Tools, including Apache Airflow or cron jobs on Linux, can aid in automating these chores.
At last, guarantee that your integrated framework can manage error logging and monitoring. Execute error handling in your scripts to capture and log any issues during OCR or data entry, enabling troubleshooting and progressing reliability. This all-around strategy permits you to simplify the data entry process, lessening manual labor while boosting precision and efficiency.
Conclusion:
In summary, improving corporate operations requires accurate and dependable data extraction. On the other hand, organizations that use manual data entry must deal with reduced productivity, higher expenses and errors, and other problems. Using OCR (Optical Character Recognition) technology, data from scanned PDFs, photos, and paper documents become easy to edit and search. This software solution extracts data by recognizing various characters and comparing them to a reliable font database. OCR technology is currently widely used in a number of industries, including retail, lending, finance, government, real estate, healthcare, and logistics, to automate data extraction operations with acute accuracy.
